Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
CPU Chip Topologies
Having explained that the various cloud instances can vary quite dramatically in their hardware configurations even though on paper they have the same delivered “vCPU” count, it would be interesting to dwell a little bit more into the CPU topologies and resulting aspects such as the core-to-core latencies. Frustrated with some inflexible or inaccurate public tools on the matter, I recently had the time to write a new custom microbenchmark for testing synchronisation latencies of CPU cores, exhibiting some of the cache-coherency as well as physical layouts of current designs.
The following tables are core-to-core synchronisation latencies in nanoseconds.

Graviton1 - a1.4xlarge - Arm v8.0 ldaex/stlex
I thought that first it would be interesting to go back and showcase how Amazon’s first-generation Graviton SoC fared in this regard. Powered by Cortex-A72 cores, this design had its 16 cores arranged into 4 clusters, connected via coherent crossbar interconnect. Each cluster of 4x A72 cores had its own 2MB L2 cache, and we clearly see the faster access latencies within such a cluster in the above results. Coherency going from one cluster to the other incurred quite a high penalty, almost quadrupling the access latency.
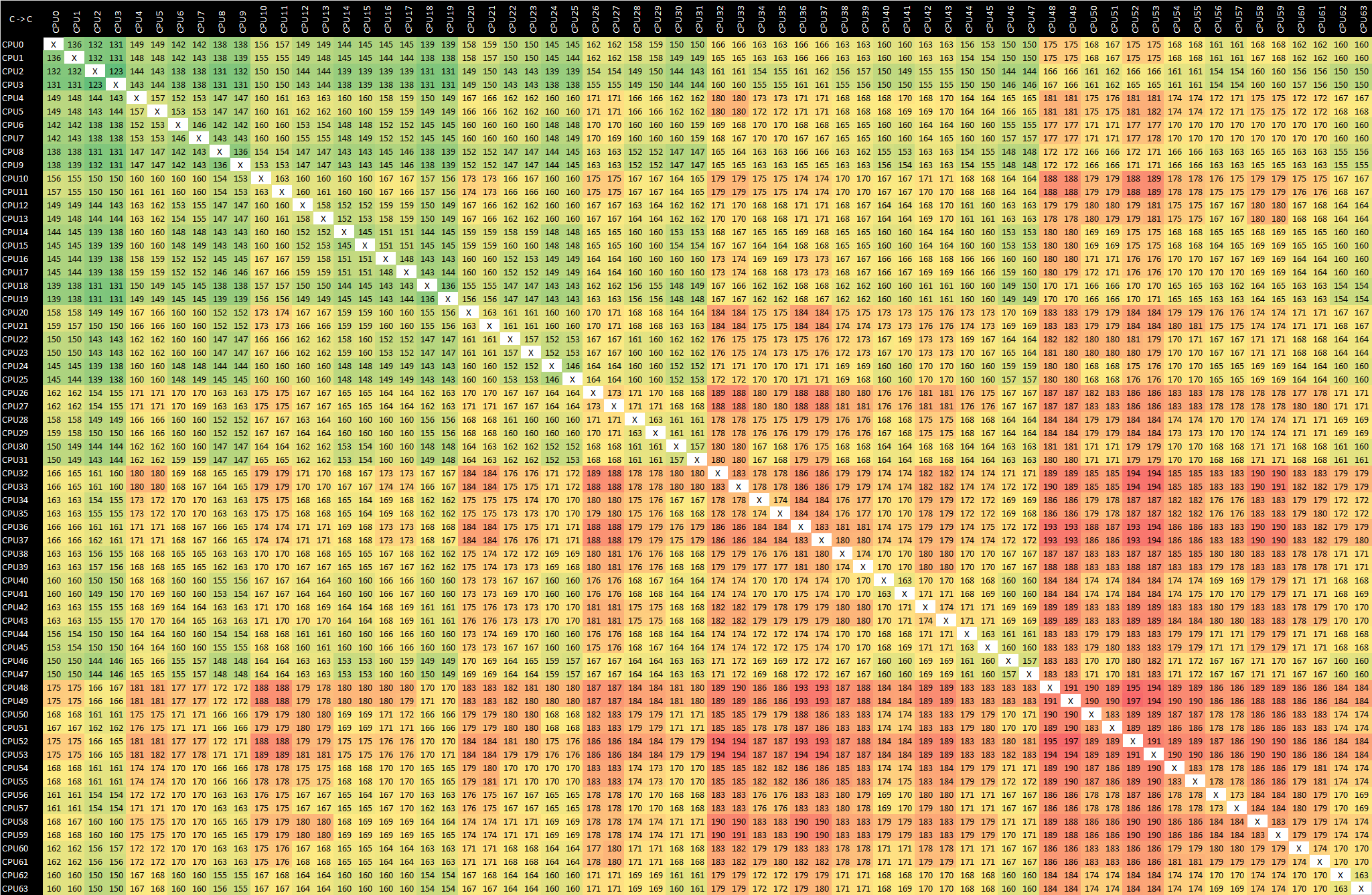
Graviton2 - m6g.16xlarge - Arm v8.0 ldaex/stlex
Cache line Near Core 0
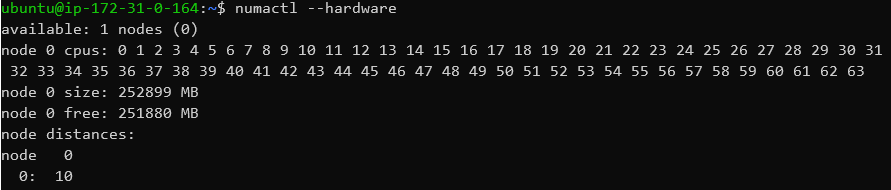
Moving onto the Graviton2 with its 64 N1 cores, we see quite a different setup that is comparatively a lot more uniform. This makes sense as the chip’s cores are connected via a mesh network, and the chip is a single monolithic die design. We do see some odd results in the latencies though, most particularly with the lower numbered cores having seemingly better access latencies between each other than the higher numbered cores. I didn’t quite understand this behaviour as in theory the latencies should behave more evenly across the mesh.
Experimenting around, I saw that the results weren’t consistent across runs. Changing the CPU affinity around did have some larger impact on the results, until I understood what was happening.
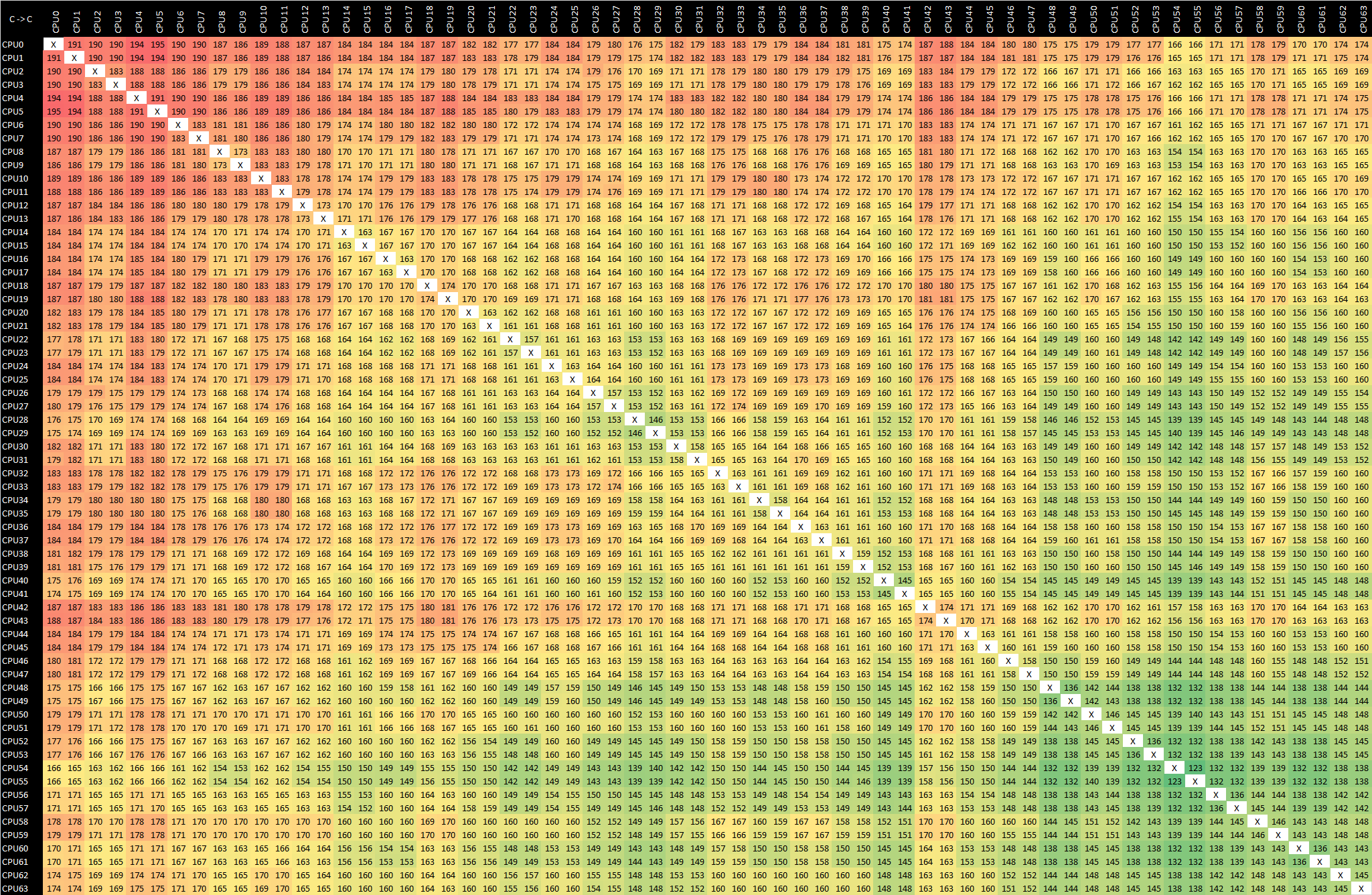
Graviton2 - m6g.16xlarge - Arm v8.0 ldaex/stlex
Cache line Near Core 63
In fact, what we’re seeing in the two above result sets isn’t the core-to-core two-point latency across the mesh, but rather the core-to-cache-to-core three-point latencies of the system. Amazon and Arm had confirmed one particular odd aspect of the CMN-600: cache lines are statically resident across the mesh’s cache slices. When allocating a cache line in the memory address space, this undergoes a particular hashing function which determines on which mesh cache slice it is physically homed in. When accessing this cache line from any CPU in the system, it always accesses the same physical L3 cache slice on the chip.
My particular test here consists of three primary threads: the main timing thread, and two ping-pong’ing bouncer threads which alter a flag on a cache-line allocated at the start of the test on the main thread. The behaviour which ensues in the above results table, is that when the flag cache line resides in one corner of the chip (Core pair 54 & 55 to be exact in this results set), and we have two cores on the opposite side of the chip accessing this cache line, it means the data must move forth across the whole chip and back even though it’s only being used by two cores adjacent to each other. Similarly, if two cores are synchronising on a cache line that is homed on a physically near cache slice in the mesh, the latencies will be significantly better as it has to travel much less distance.
It’s quite the odd behaviour that we don’t see quite as prevalent in other meshed cache interconnect systems such as Intel’s Xeons, although admittedly we don’t know if that’s just because we haven’t seen the same large core count implemented in such a manner, or if they have some sort of smarter cache line handling in such scenarios.
Amazon’s Graviton2 doesn’t partition the L3 mesh cache when launching lower vCPU count instances, and each instance in the system competitively shares the full 32MB cache with each other. I didn’t further spend time on this theory in my testing time, but it would be quite the odd result if you’re running some sort of high-synchronisation bottlenecked workload and the performance would vary just depending on where your shared cache line ends up on the chip relative to your active instance cores, food for thought for some database workloads.
The above results were core-to-core latencies implemented via Arm v8.0 exclusive load and stores, which isn’t really how you should do things on new chips such as the Neoverse N1 based Graviton2. As the N1 cores are v8.2 compatible, it means that they also implement the v8.1 ISA which add new instructions such as atomic compare-and-set (CAS).
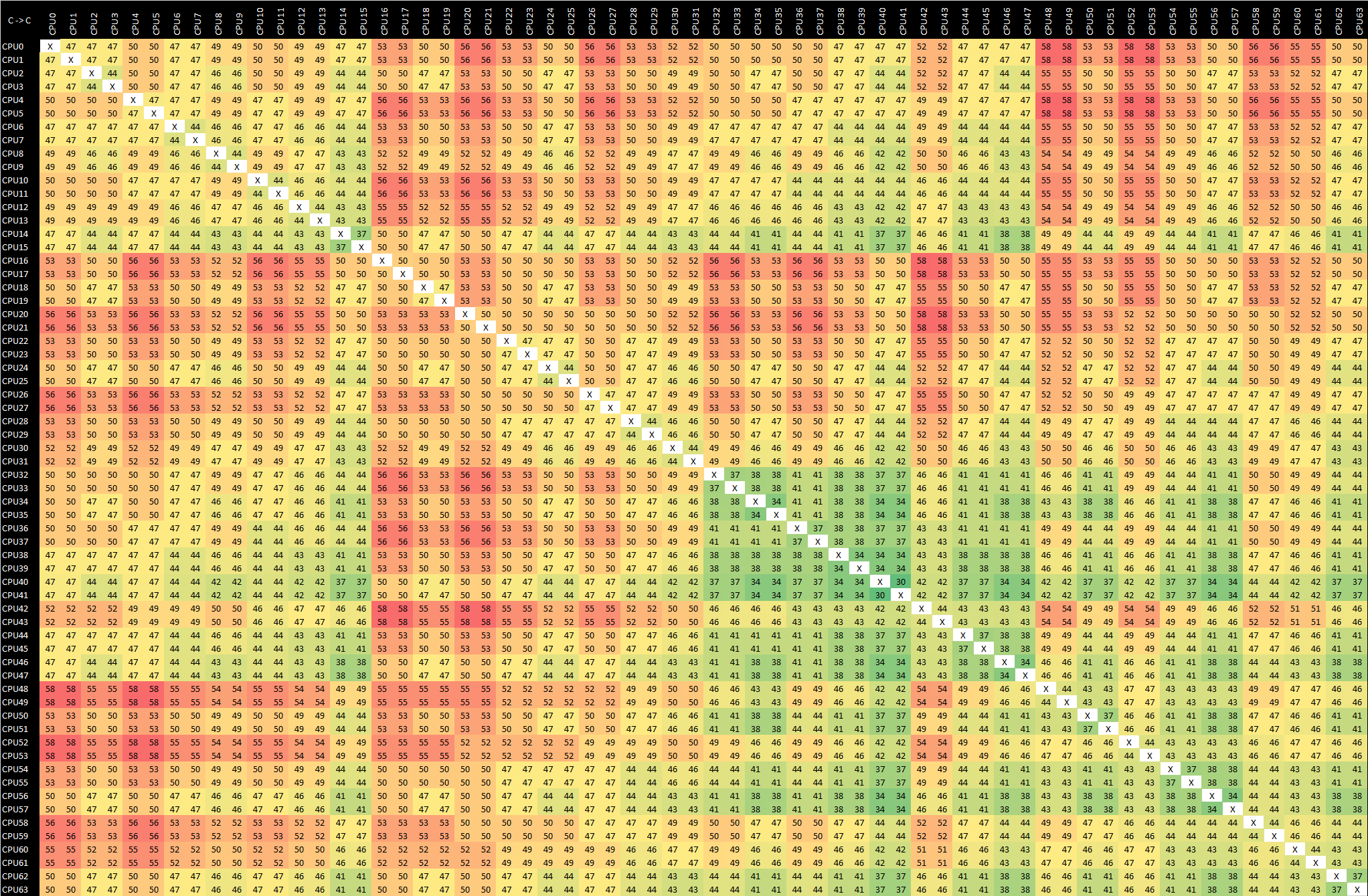
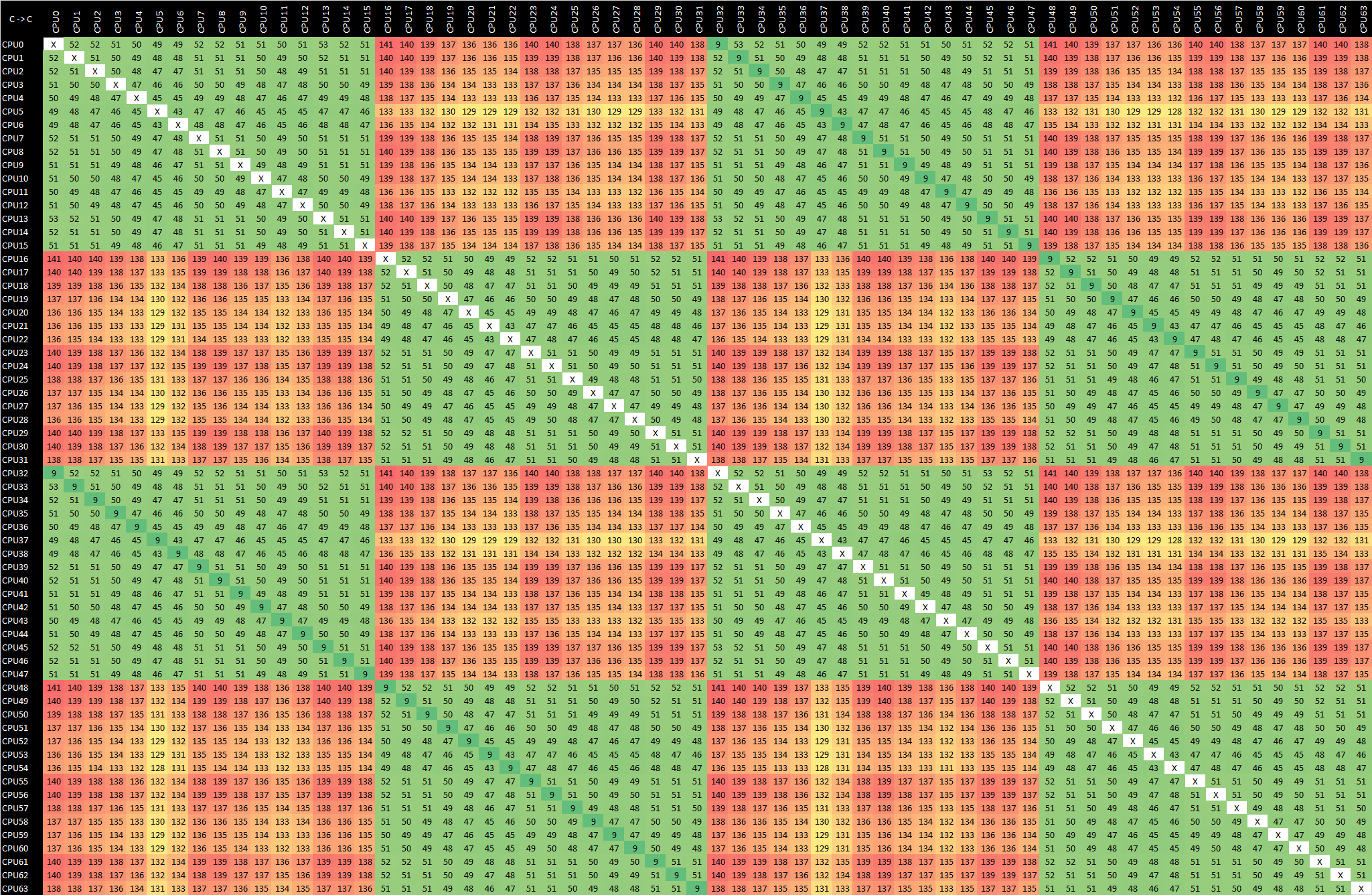
Graviton2 - m6g.16xlarge - Arm v8.1 CAS
Using CAS instructions for synchronisation is massively more efficient and faster than using several sequential operations for altering a value, as the change can be done in a single atomic operation, vastly reducing the back-and-forth coherency traffic across the chip. In absolute figures, this results in latencies almost 4 times faster than the equivalent Arm v8.0 mechanism.
What’s important here in terms of takeaways, is that if you are deploying software on the new Graviton2 system and upcoming other Neoverse N1 platforms, is that you should pay very close attention to make sure your software stack is compiled against Arm v8.1 or higher (N1 is v8.2).
Currently I don’t know how many pre-compiled packages in Linux distributions even account for such scenarios as I imagine they’re all targeting the most common v8.0 baseline. Again, database applications and other synchronization heavy workloads will be most affected and it’s recommended you compile these from source – it would be an interesting performance test for AWS users who do deploy such workloads (Taking suggestions on such a real-world test setup!).
Looking at the CAS results again, besides the lower latencies, we also see a higher-level latency pattern across the mesh, with distinct separation into 16-core groups in terms of the latencies.
Essentially what I think we’re seeing here is the separation of the chip’s mesh network into “super tiles”, essentially mesh quadrants on the chip. Depending on how the data is routed on the mesh, this appears as a pattern across the latencies between the cores. It is quite odd that these results aren’t as uniform as the v8.0 results; I don’t have any technical explanation for this behaviour.
Finally, it’s again noteworthy that we’re talking about a 64-core system with a single uniform memory domain and on a single monolithic die. AMD’s Rome does provide the former, but doesn’t achieve the same uniform access latencies as the Graviton2.
Xeon Platinum 8259 (Cascade Lake) - m5n.16xlarge - x86 CAS
Looking at the Intel Xeon based instances for comparison, we see relatively uniform access across 16 cores in the same socket, with worse latencies for the CPUs in the second socket. The Graviton2’s latencies here are better than Intel in the best case, but also slightly worse in the worst case (in the same socket).
It’s to be noted that these systems have the SMT logical cores enumerated not at N+1 as in Windows, but instead first listing the cores in physical order first, and then listing the secondary SMT logical cores, hence the mirrored latencies from core 32 onwards. Noteworthy is the low logical-to-logical core latencies of 9.3ns (~3.2GHz cores), due to the coherency between such siblings happening at the L1D cache level.
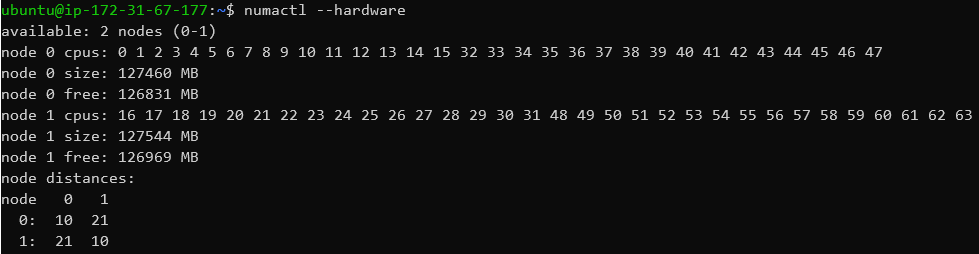
Having two sockets, we’re seeing two NUMA nodes for the Xeon system, dividing up the physical memory into two virtual memory spaces and two core sets.
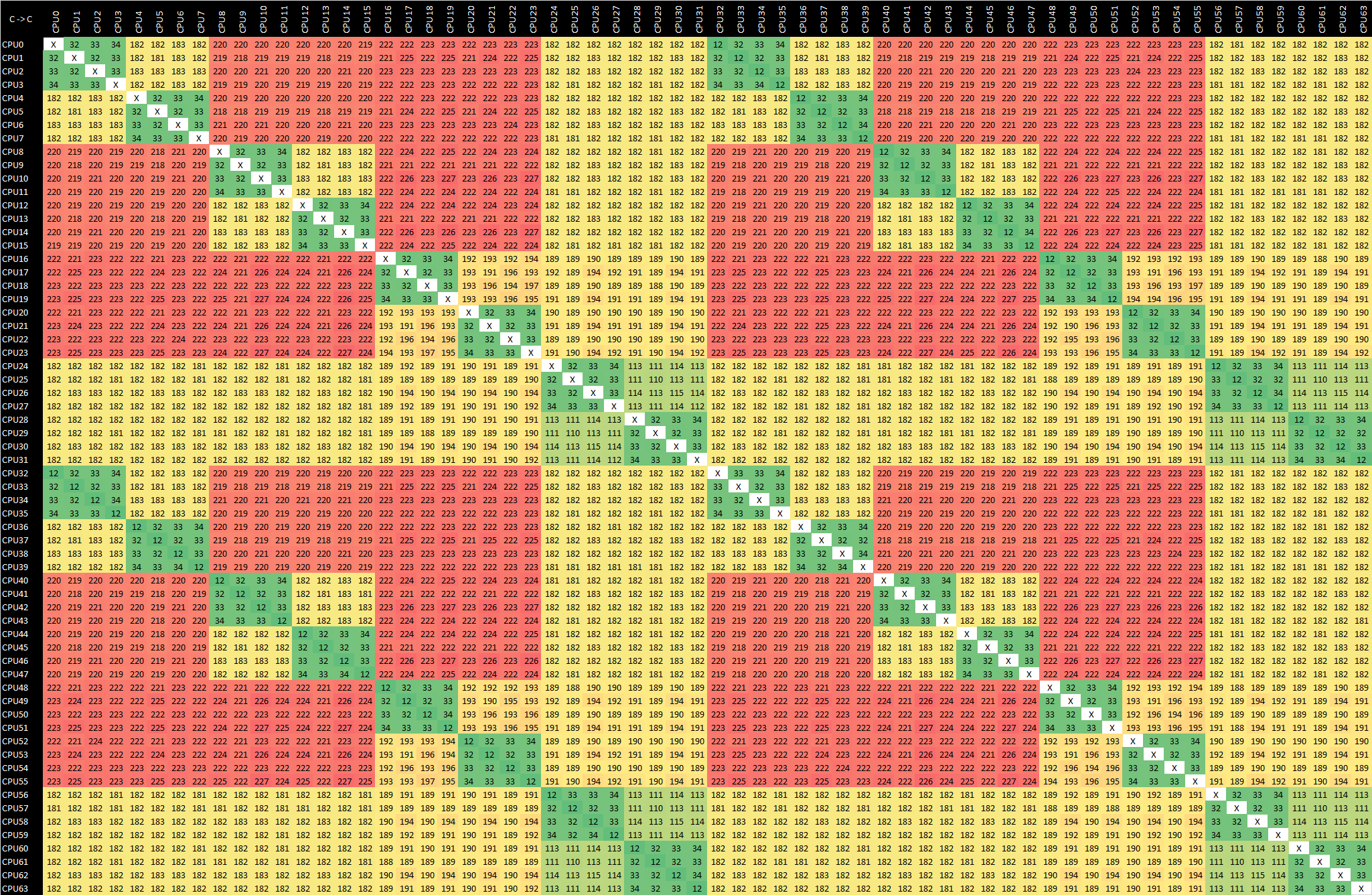
AMD EPYC 7571 - m5a.16xlarge - x86 CAS
Finally, the AMD EPYC system we see cores within an CCX having excellent latencies between each other, however coherency between different CCXs is slow, and even slower when accessing other dies within the socket.
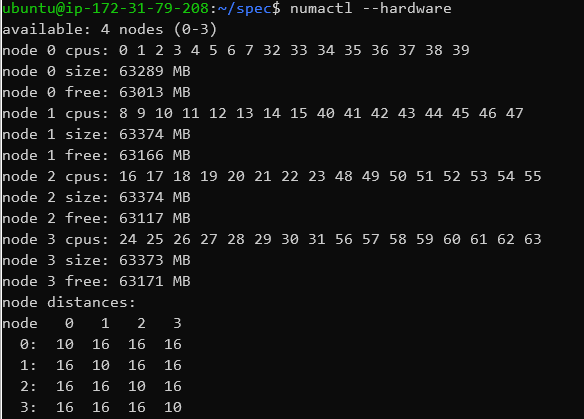
The four NUMA nodes means the memory is divided into four virtual memory spaces as well as CPU groups. Again, AMD’s newer EPYC2 Rome processors get rid of this limitation, but alas weren’t able to test on AWS at this moment in time.








96 Comments
View All Comments
SarahKerrigan - Tuesday, March 10, 2020 - link
That single-thread performance is extremely impressive. The multithreaded scaling is ugly, though. Back when N1 was announced, ARM seemed to think 1MB/core was a good spot for Neoverse LLC - I wonder why both Graviton and Altra are going for considerably less.shing3232 - Tuesday, March 10, 2020 - link
it's gonna costly(die and power wise) to build a interconnect for 64C with good performance. by the time, it would lost its power/perf edge I suppose.Tabalan - Tuesday, March 10, 2020 - link
Scaling might not be optimal, but performance loses are to expected if you greatly reduce available cache. In the end, MT performance is still far ahead of competition.ballsystemlord - Thursday, March 12, 2020 - link
You have to remember that the competition is not 64 cores, but 64v cpus. The difference is 60% or more. The Arm Graviton2 is being placed into the best possible light by this comparision.ballsystemlord - Thursday, March 12, 2020 - link
I mean 60% for the cores that are actually 1 thread. As in, the performance boost by turning on SMT is 40% best case scenario.autarchprinceps - Sunday, October 25, 2020 - link
I have to disagree. You seem to forget that the arm chip is cheaper. It’s an additional win if it manages to integrate more cores and yet still achieve a comparable single threaded performance. It’s not unfair to compare two products with one seeming to have a stat advantage from the start, if it’s still cheaper or costs the same. Why should a customer care?zamroni - Thursday, March 12, 2020 - link
L caches uses sram which needs 6 transistors per bit.So, every 1MB needs all least 48 millions transistors without counting transistors for the controller
dianajmclean6 - Monday, March 23, 2020 - link
Six months ago I lost my job and after that I was fortunate enough to stumble upon a great website which literally saved me• I started working for them online and in a short time after I've started averaging 15k a month••• icash68.coMRallJ - Tuesday, March 10, 2020 - link
Comparisons made are to the whole core performance of Graviton to just thread performance of Xeon/EPYC. It's very problematic.Also TDP rating for the graviton is off by 50% based on what was reported at re:Invent.
Andrei Frumusanu - Tuesday, March 10, 2020 - link
I go over the core/SMT topic in the article, it's only a problem from a hardware comparison aspect, but it's very much the correct comparison from a cloud product offering comparison. The value proposition also does not change depending on core count, the instances are priced at similar tiers.