Knights Mill Spotted at Supercomputing
by Ian Cutress on November 19, 2018 11:00 AM EST- Posted in
- CPUs
- Intel
- Xeon
- Trade Shows
- Xeon Phi
- Knights Mill
- Supercomputing 18

All the way back at Hot Chips 2017, we saw Intel launch its upgraded Xeon Phi processors, Knights Mill. These were updated versions of Knights Landing, using the same upgraded Silvermont x86 cores paired with AVX-512 units and MCDRAM, but focusing on variable length instructions for machine learning. Despite the launch way back when, we had not heard much about anyone using them. Until this past week, that is.
The Xeon Phi ecosystem was actually fairly popular for high-performance compute, with several equipped systems in the top500 supercomputing list. The combination of additional vector processing hardware with x86 compliance has helped start new collective groups. These include the Xeon Phi User Group (now the Intel Extreme Performance User Group, or IXPUG) for projects such as machine learning, matrix processing, and even visual computing. IXPUG holds a panel presentation every year at Supercomputing.
The road of Xeon Phi has not been easy, given that over the last two years Intel cancelled the Knights Landing generation PCIe cards, then stated that Knights Mill was going to be a socketed-only product, before essentially killing off the entire family altogether. (We believe the Cascade Lake-AP platform is designed to fill that role in 2019.) However, despite Knights Mill getting a mention, I haven’t seen any mentions of them in action.

At Supercomputing 2018 this past week, as is usual, I had a walk through the poster presentation room. This is usually a mix of doctoral student work, academic research bodies, and vendor assisted implementations fpr software solutions to mathematical problems. Every so often there’s an interesting hardware related poster for new silicon or a better way to manage silicon, such as the fabric network controller for GPUs we reported on in 2015. Not much luck this year, however I did spot that one of the presentations explained that the researchers were using Knights Mill for their work. It was the only place I saw, in the *whole show*, that mentioned Knights Mill.

The poster, from Joshua Davis, a student at the University of Delaware, was looking at the effects of limiting the peak power consumption of the Xeon Phi processor and correlating its effects on compute time for data-intensive benchmarks. This naturally relies on the internal DVFS implementations for voltage and frequency adjustments as well as accurate internal power reporting by the system to itself.
The idea behind the research is that there is typically a fine balance between power and execution time, and the out-of-the-box numbers are typically outside that ideal power efficiency window. By adjusting and profiling the parameters, the ideal power efficiency point could be obtained for each of the benchmarks.
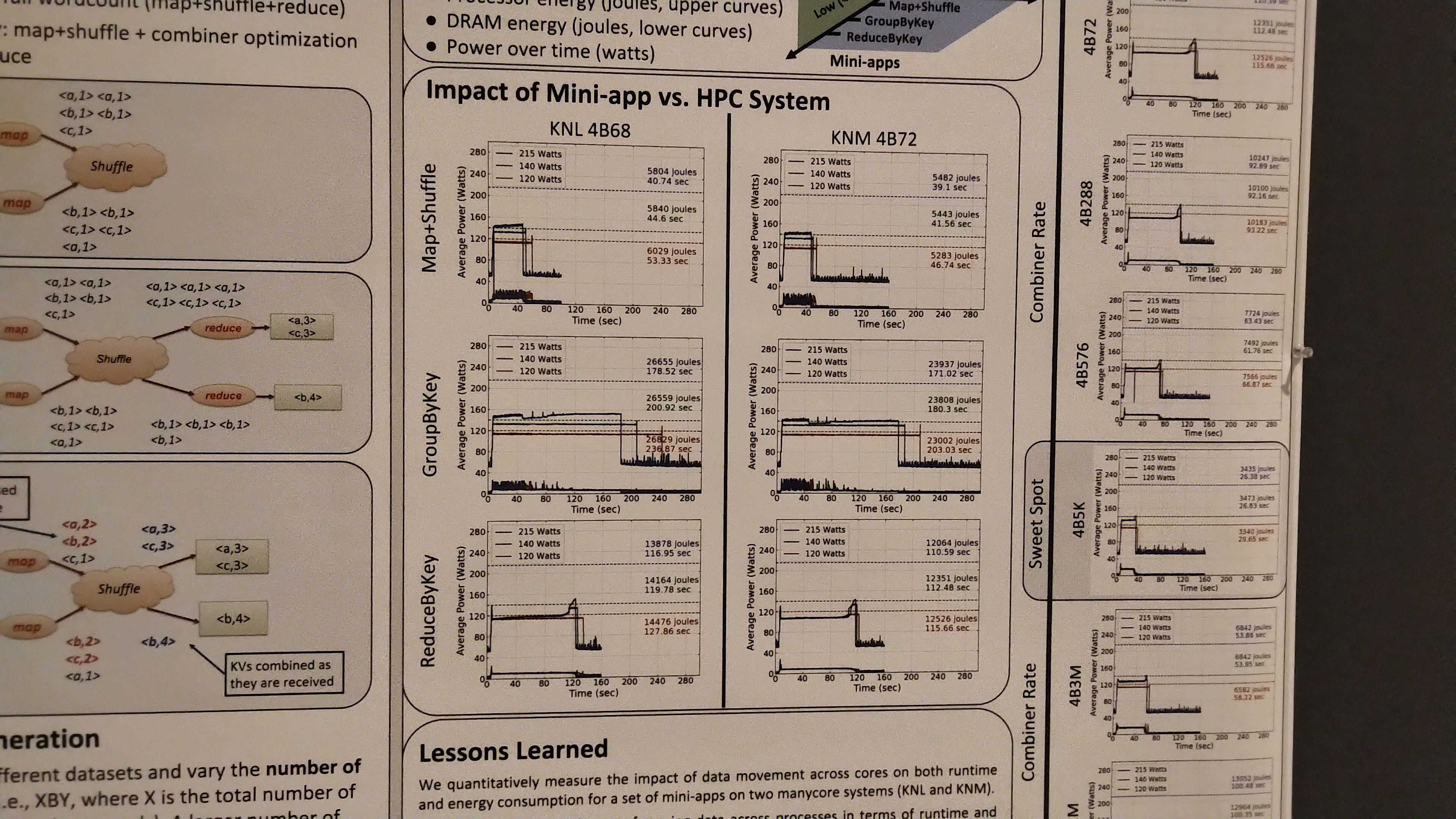
Results showed a mix of situations where reducing the power made no difference to the run time, or lengthened the run-time and saved power, or lengthened the run time but still consumed the same power. Ultimately the difficulty with this sort of testing, aside from accurate measuring, is that a full profiling set is not easily automatable – power limitations are often set at the BIOS level, requiring restarts between tests. It also means that if the high-performance software that contains parts of these benchmarks is used, a medium has to be found given that the power limit can only be applied once at machine-on.

Systems in play look like single node development towers, which I know that Intel commissioned SuperMicro to make as part of its expansion into development work. Here it states that the KNL system was a mid-range part with 68 cores and a TDP of 215W, whereas the KNM system was a top end model with 72 cores and a TDP of 320W. Both systems were tested at 215W, 140W, and 120W.
On a scale of zero to ‘I’m amazed someone is using a Knights Mill’, then I’m amazed that someone is using Knights Mill. It wasn’t stated if the KNM specific instruction sets were being used (or even if they were applicable). I wonder if we’ll see any mention of KNM at next year’s Supercomputing.








10 Comments
View All Comments
Yojimbo - Monday, November 19, 2018 - link
Intel has announced the death of Xeon Phi, and it sounds like what they will come out with in its stead will be significantly different. I'd be very surprised if we hear about KNM at next year's Supercomputing. It sounds like someone started with a research project and then continued on with it, presumably because there may be some use to its explorations other than what applies specifically to Xeon Phi.Ian Cutress - Monday, November 19, 2018 - link
As far as I can tell, the AP line replaces the Xeon Phi line in that segment in Intel's roadmaps. Except without the MCDRAM.Yojimbo - Monday, November 19, 2018 - link
What are their plans for the AP line? Will the A21 Supercomputer really be made with something like Cascade Lake-AP? From the way Intel talked a few months back, whatever Intel is using to try to win the A21 contract (which seems to be theirs to win as long as they come up with something satisfactory) sounded a bit more radical than Cascade Lake-AP. And it shouldn't be like Xeon Phi, because otherwise there would be no reason to be so dramatic about the whole thing. They could have just canceled Knights Hill and delayed Aurora, bringing out another Xeon Phi later. Announcing the death of Xeon Phi when it's not really dying would only serve to create instability in the ecosystem.But I didn't mean that the research was applicable to anything concrete coming out. The researchers presumably have no idea of what will come out. I just meant that perhaps their findings can be applied to other architectures somehow. I dunno, I didn't look at the poster at all.
ken.c - Monday, November 19, 2018 - link
We received a KNL evaluation system from a particular vendor that starts with D last year. Sadly, it was pretty much a bare board in a chassis, and the only way to get it to boot was off of a usb key. We've never been able to get them to send us either the cables or the card for any other storage interface. It's an utterly dead platform.Ian Cutress - Monday, November 19, 2018 - link
Is there not even a SATA port? What about PCIe storage?Ej24 - Tuesday, November 20, 2018 - link
Knights landing with 68 x86 cores at what, 1.2GHZ, was considered extremely niche just a year or two ago but soon we'll have Epyc with 64 cores and usable clock speeds. Not a niche coprocessor but a full on socketed server/workstation cpu. My how times have changed.mode_13h - Tuesday, November 20, 2018 - link
But each of the KNL cores has two AVX-512 pipes, while EPYC 7 nm (Rome?) has only dual 256-bit pipes.As we've learned from GPUs, the race for energy efficient compute is generally won by wider architectures at lower clocks.
jospoortvliet - Tuesday, November 20, 2018 - link
Sure, but those AVX pipelines are only useful in specific scenarios - in general in cases where GPUs do well, too. EPYC will perform well in a wide range of scenarios and can be paired with accelerators using its massive array of PCI Express lanes. I agree with ej24 That KNL and the likes look a little obsolete now.mode_13h - Tuesday, November 20, 2018 - link
I was just pointing out that even @ 64 cores, new EPYC is not exactly following the path of Xeon Phi.Where KNL failed was trying to beat GPUs at their own game. However, the introduction of the AP line suggests that Intel stumbled upon applications hungry for higher-density of general purpose cores.
I wonder how sustainable the path of higher core counts really is. Cache coherence will eat your perf/W.
Daniellephillips - Thursday, December 13, 2018 - link
Intel acquired Nervana Systems for its algorithms as opposed to its processor designs. As the Intel Xeon Phi Knights Mill processors and coprocessors are required to be discharged in 2017, I expect that the vast majority of the designing work for Knights Mill would have been finished, so there's no sense in not discharging Knights Mill on calendar. The key parts of the Nervana Engine would have been incorporated into Knights Mill. With best regards, https://www.ukassignment.co.uk/