The IBM POWER8 Review: Challenging the Intel Xeon
by Johan De Gelas on November 6, 2015 8:00 AM EST- Posted in
- IT Computing
- CPUs
- Enterprise
- Enterprise CPUs
- IBM
- POWER
- POWER8
Floating Point: C-ray
Shifting over from integer to floating point benchmarks we have C-ray. C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing. That is not the kind of benchmark we like to use for the evaluations of server CPUs, but since our first efforts to port some of our favorite applications to OpenPOWER failed, we settled for something easier. We knew we would have the POWER8 system only for a few weeks, so we had to play it safe.
First we compiled the C-ray multi-threaded version with -O3 -ffast-math. To understand the CPU performance better, we limited C-ray with taskset to one or two threads (CPU 0 and 18) on the Haswell-based Xeon and one to eight threads on the POWER8. We also kept the output resolution at 768x432 to keep the render times in check. The "sphfract" file was used as input.
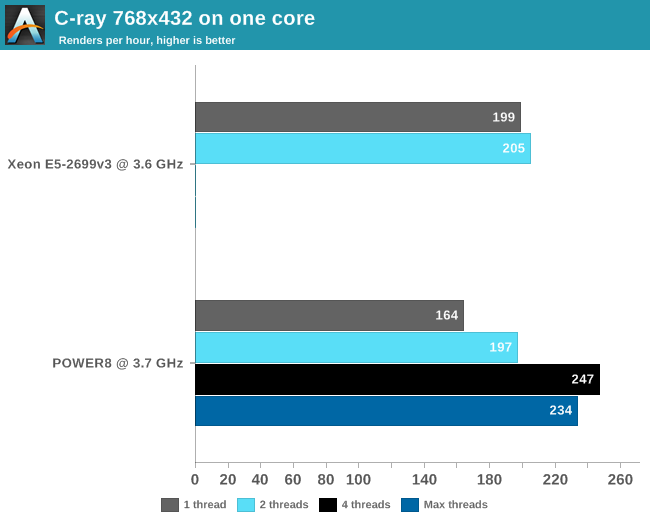
Real floating point intensive applications tend to put the memory subsystem under pressure, and running a second thread makes it only worse. So we are used to seeing that many HPC applications performe worse with multi-threading on. But since C-ray runs mostly out of the L1-cache, we get different behavior. Still, 8 threads of floating action seem to be too much: the POWER8 delivers the best FP performance at 4 threads. At this point, the POWER8 core is able to deliver 20% higher floating point performance than the Haswell Xeon.
Next we used all 160 (20 x 8 threads SMT) or 72 (36 x 2 threads SMT) threads and increased the resolution to 3840x2160.
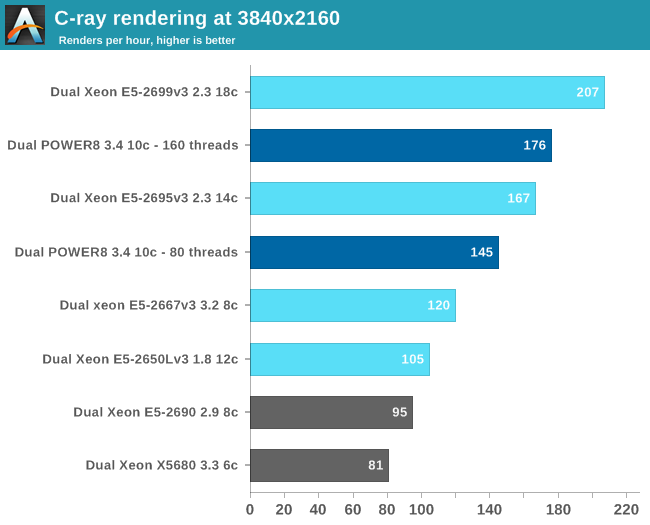
With a core count that is 80% higher, there is nothing stopping the Xeon E5-2699 v3 from taking the top spot. Still, the POWER8 delivers solid performance and outperforms the slower Xeon E5-2695 v3 by 5%. Although the real world relevance of this benchmark is small, we now have an idea of how good the "basic FP" performance is. Otherwise in real world applications, the use of AVX-2/VSX and the available bandwidth will play a role.








146 Comments
View All Comments
FunBunny2 - Friday, November 6, 2015 - link
"The z10 processor was co-developed with and shares many design traits with the POWER6 processor, such as fabrication technology, logic design, execution unit, floating-point units, bus technology (GX bus) and pipeline design style, i.e., a high frequency, low latency, deep (14 stages in the z10), in-order pipeline." from the Wiki.Yes, the z continues the CISC ISA from the 360 (well, sort of) rather than hardware RISC, but as Intel (amongst others) has demonstrated, CISC ISA doesn't have to be in hardware. In fact, the 360/30 (lowest tier) was wholly emulated, as was admitted then. Today, we'd say "micro-instructions". All those billions of transistors could have been used to implement X86 in hardware, but Intel went with emulation, sorry micro-ops.
What matters is the underlying fab tech. That's not going anywhere.
FunBunny2 - Friday, November 6, 2015 - link
^^ should have gone to KevinG!!Kevin G - Saturday, November 7, 2015 - link
The GX bus in the mainframes was indeed shared by POWER chips as that enabled system level component sharing (think chipsets).However, attributes like the execution unit and the pipeline depth are different between the POWER6 and z10. At a bird's eye view, they do look similar but the implementation is genuinely different.
Other features like SMT were introduced with the POWER5 but only the most recent z13 chip has 2 way SMT. Features like out-of-order execution, SMT, SIMD were once considered too exotic to validate in the mainframe market that needed absolute certainty in its hardware states. However, recent zArch chips have implemented these features, sometimes decades after being introduced in POWER.
The other thing is that IBM has been attempting to get get more and more of the zArch instruction set to be executed by hardware and no microcode. Roughly 75% to 80% of instructions are handled by microcode (there is a bit of a range here as some are conditional to use microcode).
JohanAnandtech - Saturday, November 7, 2015 - link
I believe that benchmark uses about 8 threads and not very well either? Secondly, it is probably very well optimized for SSE/AVX. So you can imagine that the POWER8 will not be very good at it, unless we manually optimize it for Altivec/VSX. And that is beyond my skills :-)UrQuan3 - Monday, December 21, 2015 - link
I'm sure no one is still reading this as I'm posting over a month later, but...I tested handbrake/x264 on a bunch of cross-platform builds including Raspberry Pi 2. I found it would take 24 RPi2s to match a single i5-4670K. That was a gcc compiled handbrake on Raspbian vs the heavily optimized DL copy for Windows. Not too bad really. Also, x264 seems to scale fairly well with the number of cores. Still, POWER8 unoptimized would be interesting, though not a fair test.
BTW, I'd encourage you to use a more standard Linux version than 6-month experimental little-endian version of Ubuntu. The slides you show advertise support for Ubuntu 14.04 LTS, not 15.04. For something this new, you may need the latest, but that is often not the case.
stun - Friday, November 6, 2015 - link
@Johan You might want to fix "the platform" hyperlink at the bottom of page 4. It is invalid.JohanAnandtech - Friday, November 6, 2015 - link
Thanks and fixed.Ahkorishaan - Friday, November 6, 2015 - link
Couldn't read past the graphic on page 1. It's 2015 IBM, time to use a font that doesn't look like a toddler's handwriting.xype - Sunday, November 8, 2015 - link
To be fair, it seems that the slide is meant for management types… :PJtaylor1986 - Friday, November 6, 2015 - link
Using decimals instead of commas to denote thousands is jarring to your North American readers.