The IBM POWER8 Review: Challenging the Intel Xeon
by Johan De Gelas on November 6, 2015 8:00 AM EST- Posted in
- IT Computing
- CPUs
- Enterprise
- Enterprise CPUs
- IBM
- POWER
- POWER8
Floating Point: C-ray
Shifting over from integer to floating point benchmarks we have C-ray. C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing. That is not the kind of benchmark we like to use for the evaluations of server CPUs, but since our first efforts to port some of our favorite applications to OpenPOWER failed, we settled for something easier. We knew we would have the POWER8 system only for a few weeks, so we had to play it safe.
First we compiled the C-ray multi-threaded version with -O3 -ffast-math. To understand the CPU performance better, we limited C-ray with taskset to one or two threads (CPU 0 and 18) on the Haswell-based Xeon and one to eight threads on the POWER8. We also kept the output resolution at 768x432 to keep the render times in check. The "sphfract" file was used as input.
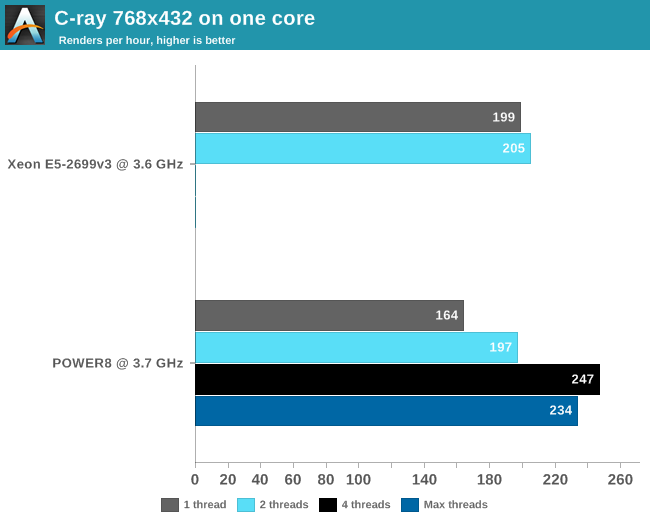
Real floating point intensive applications tend to put the memory subsystem under pressure, and running a second thread makes it only worse. So we are used to seeing that many HPC applications performe worse with multi-threading on. But since C-ray runs mostly out of the L1-cache, we get different behavior. Still, 8 threads of floating action seem to be too much: the POWER8 delivers the best FP performance at 4 threads. At this point, the POWER8 core is able to deliver 20% higher floating point performance than the Haswell Xeon.
Next we used all 160 (20 x 8 threads SMT) or 72 (36 x 2 threads SMT) threads and increased the resolution to 3840x2160.
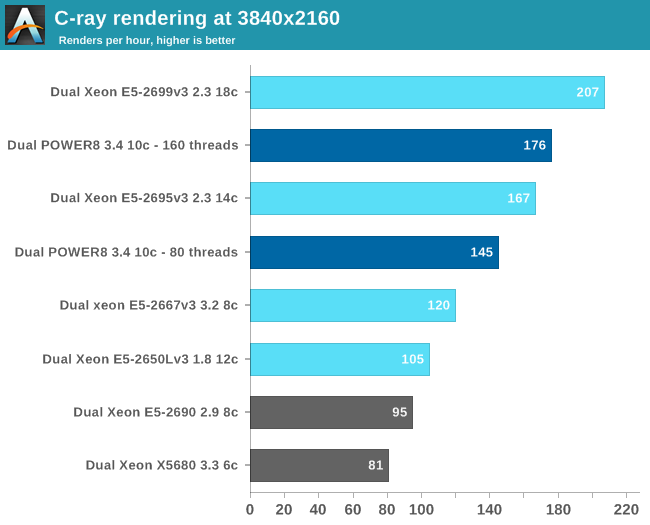
With a core count that is 80% higher, there is nothing stopping the Xeon E5-2699 v3 from taking the top spot. Still, the POWER8 delivers solid performance and outperforms the slower Xeon E5-2695 v3 by 5%. Although the real world relevance of this benchmark is small, we now have an idea of how good the "basic FP" performance is. Otherwise in real world applications, the use of AVX-2/VSX and the available bandwidth will play a role.








146 Comments
View All Comments
jesperfrimann - Monday, November 9, 2015 - link
Well, I think you should kick Franz Bourlet, for not hooking you up with with a IBM technical Advocate who actually knew the technology. Such a person could have shown you the robes and helped you understand the kit better. Again Franz is a sales guy.IMHO selecting Ubuntu as the Linux distro, did not help you. It's new to the POWER platform and does not have the same robustness as for example SLES which have been around for 10+ years on POWER.
The fact that you are getting better results using gcc generated code rather than xLC, shows me that something is not right.
And that the IBM JDK isn't working is well also an indicator that something is now right.
IMHO selecting Ubuntu, did not make Things easier for you Guys.
And for really optimized code you need to install and use High performance math libraries for POWER (MASS), which is an addon math library.
And AFAIR having 8 memory modules, only enables half the memory bandwidth of the system.
So IMHO IBM didn't help you make their system look good.
But again that is what you get when you get rid of all the clever people :)
// Jesper
nils_ - Wednesday, November 11, 2015 - link
You can always rent a box at OVH, they offer a huge chunk of an OpenPower System, albeit virtualized through Runlabs.stefstef - Sunday, November 8, 2015 - link
compared to the pentium 4 the mips r16k with loads of l3 cache was a bzip2 beast, outperforming the pentium 4 which ran at twice the clock speed and more. despite that the usage of zip programs is what these server processors are build.mapesdhs - Tuesday, November 10, 2015 - link
Just curious, do you know of any comparative results anywhere for bzip2 on old MIPS vs. other CPUs? It's not something I've seen mentioned before, at least not with respect to SGIs, but perhaps I can run som tests the next time I obtain a quad-R16K/1GHz (16MB L2) Tezro. Best I have at is only an R16K/900MHz (8MB L2) single-CPU Fuel and various configs of Tezro and Onyx350 from 4 to 16x 700MHz with 8MB L2. Just a pity SGI never got to employ multi-core MIPS (it was planned, but alas never happened).Oddly, back when current, MIPS' real strength was fp. Over time it fell behind badly for general int, though for SGI's core markets that didn't really matter ("It's the bandwidth, stupid!" - famous quote from Mashey IIRC). MIPS could have caught up with MDMX and MIPS V ISA, especially with the initially intended merged Cray vector stuff, but again that all fell away once the design talent moved to Intel in 1996/7.
Ian.
Freen the merciless - Sunday, November 8, 2015 - link
Heh! Sparc T5 eats Xeon and power for breakfast.kgardas - Monday, November 9, 2015 - link
I guess you mean T7 with SPARC M7 inside and not T5. If so, then yes, M7 looks quite capable, but unfortunately provides horrible price/performance ratio. POWER8 box starts at ~6.5k $ while T7-1 on ~40k $. So on SPARC front we'll need to see if Oracle is going to change that with Sonoma chip.Michael Bay - Monday, November 9, 2015 - link
In parallel only.aryonoco - Tuesday, November 10, 2015 - link
Thank you Johan for this amazingly well written and well researched article.I have to agree with a few people here that question your choice of using LE Ubuntu to test. Traditionally people who use Linux on POWER use SUSE, and some use RHEL, but Ubuntu? Nothing against them, and I love apt, but it's just not a mature platform.
Try with something more representative such as BE SLES and you will find a vastly different types ecosystem maturity.
But thanks again, and also thanks to AT for caring about such subjects and publishing these tests.
JohanAnandtech - Wednesday, November 11, 2015 - link
Thank you for taking the time to write up some constructive feedback. I have years of experience with ubuntu and linux and I wanted to play it safe. Running benchmarks on "new" hardware with a new ISA (from my perspective) is pretty complex. C-ray and 7-zip are the only exceptions, but most real server apps (NAMD, ElasticSearch, Spark) depends on many layers of software.In theory the OS/ distro is more important to get applications working than the ISA. In practice, it might have been better to bet on the distro with the most maturity and adapt our scripts and installation procedures to Suse.
But as soon as I get the chance, I'll try out BE suse or redhat on a POWER system.
mapesdhs - Tuesday, November 10, 2015 - link
Johan,A minor point, please note my home page for C-ray is here:
http://www.sgidepot.co.uk/c-ray.html
Blinkenlights is just a mirror, and not the primary mirror either (that would be the vintagecomputers site).
Btw, it's a pity you didn't use the same image sizes & settings as used on the main c-ray site, because then I could have included the results on my page (ie. 'sphfract' at 800x600, 1024x768 with 8X oversampling, and 7500x3500), or did you just use the same settings that Phoronix employs?
Also, John Tsiombikas, the guy who wrote C-ray, told me some interesting things about the test and how it works (info included on the page), most especially that it is highly vulnerable to compiler optimisations which can produce results that are even less realistic than real life workloads. I'm glad thought that you did at least use the sphfract test, since at a sensible resolution or with oversampling it easily pushes the test out of just L1 (the 'scene' test is much smaller). But yeah, overall, c-ray was never intended to be used as a benchmark, it's just taken off somehow, perhaps because the scanline method of threading makes it scale very well.
Hmm, I really must sort out the page formatting one of these days, and move the most complex test tables to the top. Never seem to find the time...
Thanks!!
Ian.
PS. I always obtained the best results by having more threads than the no. of cores/CPUs, or is this something which doesn't work with non-MIPS systems?