The IBM POWER8 Review: Challenging the Intel Xeon
by Johan De Gelas on November 6, 2015 8:00 AM EST- Posted in
- IT Computing
- CPUs
- Enterprise
- Enterprise CPUs
- IBM
- POWER
- POWER8
Floating Point: C-ray
Shifting over from integer to floating point benchmarks we have C-ray. C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing. That is not the kind of benchmark we like to use for the evaluations of server CPUs, but since our first efforts to port some of our favorite applications to OpenPOWER failed, we settled for something easier. We knew we would have the POWER8 system only for a few weeks, so we had to play it safe.
First we compiled the C-ray multi-threaded version with -O3 -ffast-math. To understand the CPU performance better, we limited C-ray with taskset to one or two threads (CPU 0 and 18) on the Haswell-based Xeon and one to eight threads on the POWER8. We also kept the output resolution at 768x432 to keep the render times in check. The "sphfract" file was used as input.
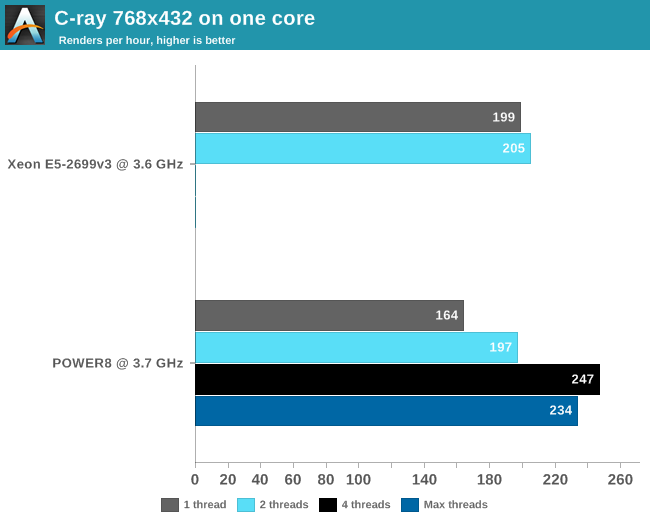
Real floating point intensive applications tend to put the memory subsystem under pressure, and running a second thread makes it only worse. So we are used to seeing that many HPC applications performe worse with multi-threading on. But since C-ray runs mostly out of the L1-cache, we get different behavior. Still, 8 threads of floating action seem to be too much: the POWER8 delivers the best FP performance at 4 threads. At this point, the POWER8 core is able to deliver 20% higher floating point performance than the Haswell Xeon.
Next we used all 160 (20 x 8 threads SMT) or 72 (36 x 2 threads SMT) threads and increased the resolution to 3840x2160.
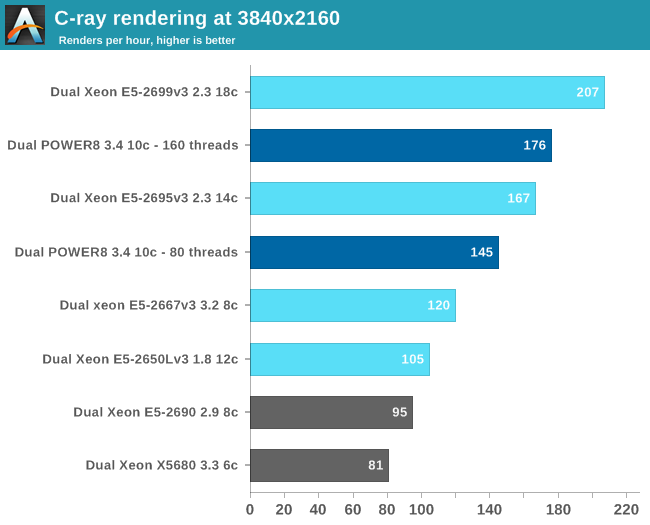
With a core count that is 80% higher, there is nothing stopping the Xeon E5-2699 v3 from taking the top spot. Still, the POWER8 delivers solid performance and outperforms the slower Xeon E5-2695 v3 by 5%. Although the real world relevance of this benchmark is small, we now have an idea of how good the "basic FP" performance is. Otherwise in real world applications, the use of AVX-2/VSX and the available bandwidth will play a role.








146 Comments
View All Comments
Kevin G - Saturday, November 7, 2015 - link
If all you do is just mount the network volume to use the data, then likely nothing at all. While binaries do have to be modified, the file systems themselves are written to store data in a single consistent manner. If you're wondering more if there would be some overhead in translating from LE to BE to work in memory, conceptually the answer is yes but I'd predict it be rather small and dwarfed by the time to transfer data over a network. I'd be curious to see the results.Ultiamtely I'd be more concerned with kernel modules for various peripherals when switching between LE and BE versions. Considering that POWER has been BE for a few generations and you did your initial testing using LE, availability shouldn't be an issue. You've been using the version which should have had the most problems in this regard.
spikebike - Friday, November 6, 2015 - link
So basically power is somewhat competitive with intel's WORST price/perf chips which also happen to have the worst memory bandwidth/CPU. Seems nowhere close for the more reasonable $400-$650 xeons like the D-1520/1540 or the E5-2620 and E5-2630. Sure IBM has better memory bandwidth than the worst intels, but if you want more memory bandwidth per $ or per core then get the E5-2620.JohanAnandtech - Saturday, November 7, 2015 - link
It is definitely not an alternative for applications where performance/watt is important. As you mentioned, Intel offers a much better range of SKUs . But for transactional databases and data mining (traditional or unstructured), I see the POWER8 as very potent challenger. When you are handling a few hundreds of gigabytes of data, you want your memory to be reliable. Intel will then steer you to the E7 range, and that is where the POWER8 can make a difference: filling the niche between E5 and E7.nils_ - Wednesday, November 11, 2015 - link
Especially if you're running software that doesn't easily scale out very well these are very competitive. And nowadays even MySQL will scale-up nicely to many, many cores.Gigaplex - Friday, November 6, 2015 - link
"Less important, but still significant is the fact that IBM uses SAS disks, which increase the cost of the storage system, especially if you want lots of them."The Dell servers I've used had SAS controllers, and every SAS controller I've dealt with supported using SATA drives. I'm pretty sure SATA compatibility is in the SAS specification. In fact, the Dell R730 quoted in this review supports SAS drives. There shouldn't be anything stopping you from using the same drives in both servers.
JohanAnandtech - Saturday, November 7, 2015 - link
You are absolutely right about SATA drives being compatible with a SAS controller. However, afaik IBM gives you only the choice between their own rather expensive SAS drives and SSDs. And maybe I have looked over it, but in general DELL let you only chose between SATA and SSDs. And this has been the trend for a while: SATA if you want to keep costs low, SSDs for everything else.TomWomack - Sunday, November 8, 2015 - link
And mounting a storage server made out of commodity hardware over a couple of lanes of 10Gbit Ethernet if you don't want to pay the exotic-hardware-supplier's markup on disc.Gunbuster - Friday, November 6, 2015 - link
SAP and IBM AIX servers... I guess if you want to blow out your entire IT budget in once easy decision...Jake Hamby - Friday, November 6, 2015 - link
I forgot to mention: VMX is better known as AltiVec (it's also called "Velocity Engine" by Apple). It's a very nice SIMD extension that was supported by Apple's G4 (Motorola/Freescale 7400/7450) and G5 (IBM PPC 970) Macs, as well as the PPC game consoles.It would be interesting to compare the Linux VMX crypto acceleration to code written to use the newer native AES & other instructions. In x86 terms, it'd be like SSE-optimized AES vs. the AES-NI instructions.
Oxford Guy - Saturday, November 7, 2015 - link
I had a dual 450 MHz G4 system and AltiVec was quite amazing in iTunes when doing encoding. Between the second processor and the AltiVec putting things into ALAC was very fast (in comparison with other machines at the time like the G3 and the AMD machines I had).