The NVIDIA GeForce GTX 980 Ti Review
by Ryan Smith on May 31, 2015 6:00 PM ESTCompute
Shifting gears, we have our look at compute performance. Since GTX Titan X has no compute feature advantage - no fast double precision support like what's found in the Kepler generation Titans - the performance difference between the GTX Titan X and GTX 980 Ti should be very straightforward.
Starting us off for our look at compute is LuxMark3.0, the latest version of the official benchmark of LuxRender 2.0. LuxRender’s GPU-accelerated rendering mode is an OpenCL based ray tracer that forms a part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
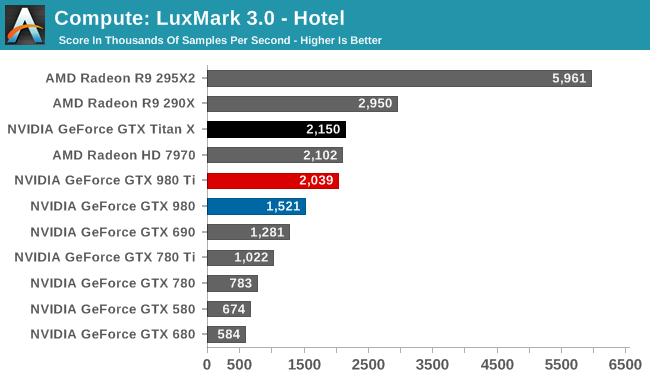
With the pace set for GM200 by GTX Titan X, there’s little to say here that hasn’t already been said. Maxwell does not fare well in LuxMark, and while GTX 980 Ti continues to stick very close to GTX Titan X, it none the less ends up right behind the Radeon HD 7970 in this benchmark.
For our second set of compute benchmarks we have CompuBench 1.5, the successor to CLBenchmark. CompuBench offers a wide array of different practical compute workloads, and we’ve decided to focus on face detection, optical flow modeling, and particle simulations.
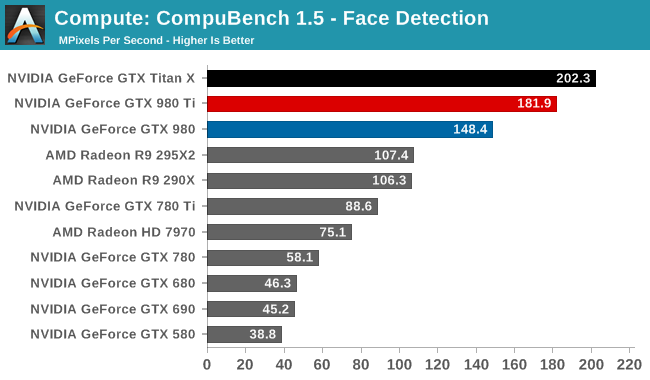
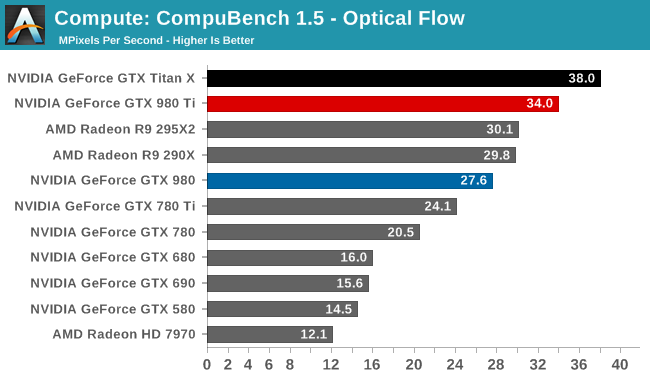
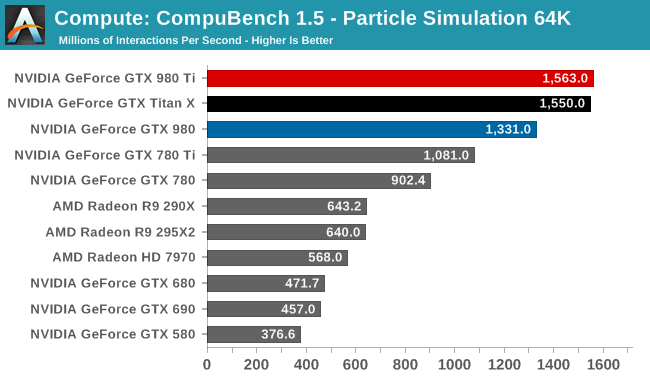
Although GTX T980 Ti struggled at LuxMark, the same cannot be said for CompuBench. Though taking the second spot in all 3 sub-tests - right behind GTX Titan X - there's a bit wider of a gap than normal between the two GM200 cards, causing GTX 980 Ti to trail a little more significantly than in other tests. Given the short nature of these tests, GTX 980 Ti doesn't get to enjoy its usual clockspeed advantage, making this one of the only benchmarks where the theoretical 9% performance difference between the cards becomes a reality.
Our 3rd compute benchmark is Sony Vegas Pro 13, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
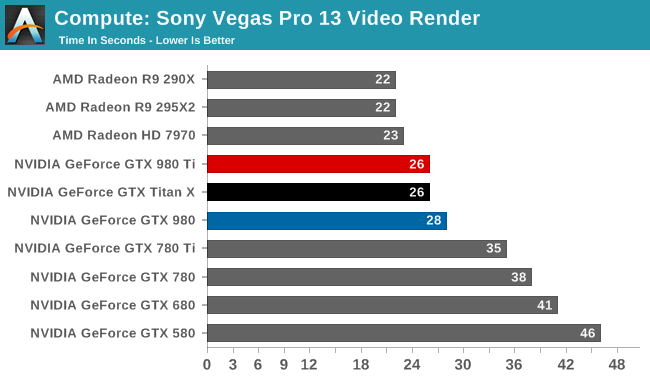
Traditionally a benchmark that favors AMD, GTX 980 Ti fares as well as GTX Titan X, closing the gap some. But it's still not enough to surpass Radeon HD 7970, let alone Radeon R9 290X.
Moving on, our 4th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, utilizing the OpenCL path for FAHCore 17.
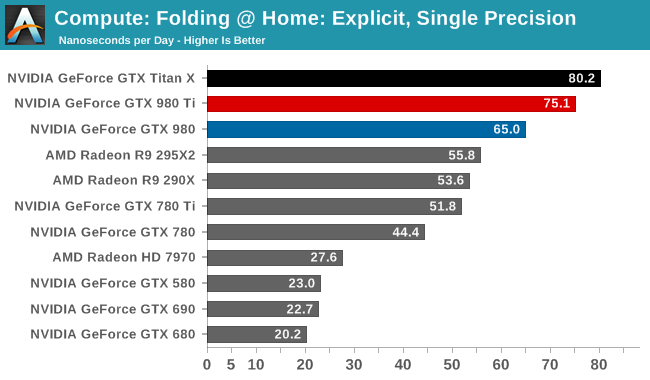
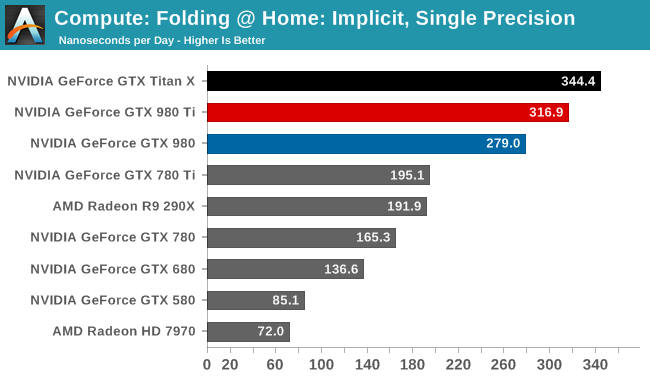
Folding @ Home’s single precision tests reiterate GM200's FP32 compute credentials. Second only to GTX Titan X, GTX 980 Ti fares very well here.
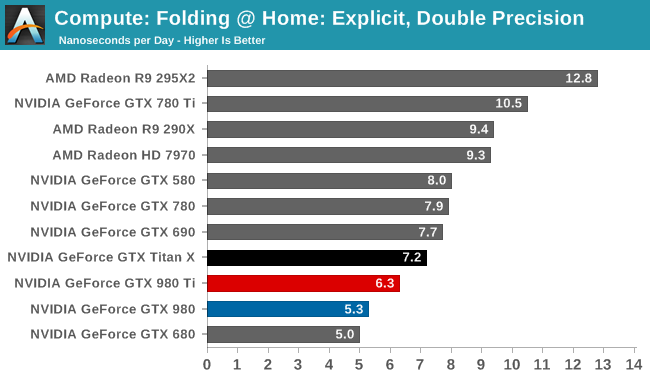
Meanwhile Folding @ Home’s double precision test reiterates GM200's poor FP64 compute performance. At 6.3ns/day, it, like the GTX Titan X, occupies the lower portion of our benchmark charts, below AMD's cards and NVIDIA's high-performnace FP64 cards.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
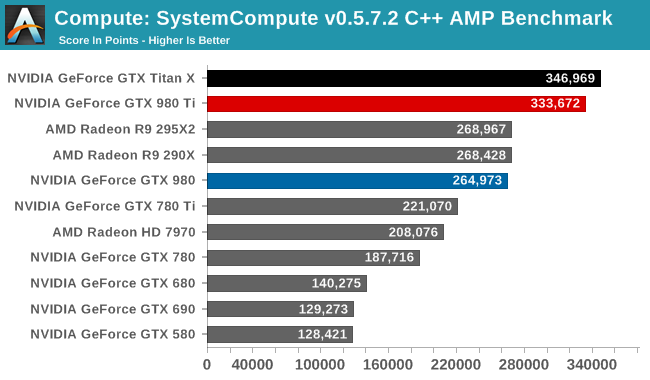
We end up ending our benchmarks where we started: with the GTX 980 Ti slightly trailing the GTX Titan X, and with the two GM200 cards taking the top two spots overall. So as with GTX Titan X, GTX 980 Ti is a force to be reckoned with for FP32 compute, which for a pure consumer card should be a good match for consumer compute workloads.








290 Comments
View All Comments
xenol - Monday, June 1, 2015 - link
Transistor count means nothing. The GTX 780 Ti has 2.8 billion transistors. The GTX 980 has around 2 billion transistors, and yet the GTX 980 can dance with the GTX 780 Ti in performance.As the saying goes... it's not the size that matters, only how you use it.
Niabureth - Monday, June 1, 2015 - link
Don't want to sound like a messer schmitt but thats 2,8K cuda cores for GK110, and 2K for the GM204. The GK110 has 7.1 billion transistors.jman9295 - Tuesday, June 2, 2015 - link
In this very article they list the transistor count of those two cards in a giant graph. The 980 has 5.2 billion transistors and the 780ti 7.1 billion. Still, your point is the same, they got more performance out of less transistors on the same manufacturing node. All 28nm means is how small the gap is between identical components, in this case the CUDA cores. Each Maxwell CUDA is clearly more efficient than each Kepler. Also helping is the double VRAM size which probably allowed them to also double the ROP count which greatly improved transistor efficiency and performance.Mithan - Sunday, May 31, 2015 - link
It matters because we are close to .16/20nm GPU's, which will destroy these.dragonsqrrl - Sunday, May 31, 2015 - link
"we are close to .16/20nm GPU's"People said the same thing when the 750Ti launched. I'll give give you one thing, we are closer than we were, but we are not "close".
Kevin G - Monday, June 1, 2015 - link
The difference now is that there are actually 20 nm products on the market today, just none of them are GPUs. It seems that without FinFET, 20 nm looks to be optimal only for mobile.felicityc - Tuesday, January 11, 2022 - link
What if I told you we are on 8nm now?LemmingOverlord - Monday, June 1, 2015 - link
@SirMaster - The reason people care about the process node is because that right now - in mid-2015 - this is an extremely mature (ie: old but well-rehearsed) manufacturing process, which has gone through several iterations and can now yield much better results (literally) than the original 28nm process. This means that it's much cheaper to produce because there are less defective parts per wafer (ie: higher yield). Hence ComputerGuy2006 saying what he said.Contrary to what other people say "smaller nm" does NOT imply higher performance. Basically when a shrink comes along you can expect manufacturers to do 1 of two things:
a) higher transistor count in a similar die size, with similar power characteristics when compared to its ancestor - and therefore higher performance
b) same transistor count in a much smaller die size, therefore better thermals/power characteristics
Neither of these factor in architectural enhancements (which sometimes are not that transparent, due to their immaturity).
So ComputerGuy2006 is absolutely right. Nvidia will make a killing on a very mature process which costs them a below-average amount of money to manufacture.
In this case Nvidia is using "defective" Titan X chips to manufacture 980 Ti. Simple as that. Their Titan X leftovers sell for $350 less and you still get almost all the performance a Titan would give you.
royalcrown - Wednesday, June 3, 2015 - link
I take issue with point b) " same transistor count in a much smaller die size, therefore better thermals/power characteristics"I disagree because the same die shrink can also cause a rise in power density, therefore WORSE characteristics (especially thermals).
Gasaraki88 - Monday, June 1, 2015 - link
Smaller nm, bigger e-peen.