The Intel Xeon E7-8800 v3 Review: The POWER8 Killer?
by Johan De Gelas on May 8, 2015 8:00 AM EST- Posted in
- CPUs
- IT Computing
- Intel
- Xeon
- Haswell
- Enterprise
- server
- Enterprise CPUs
- POWER
- POWER8
Haswell Architecture Improvements
We have discussed the advantages that the Haswell core brings here in more detail. In a nutshell:
- The core can sustain about 10% more integer instructions per clock cycle than its predecessor, Ivy Bridge.
- Virtualized applications should perform slightly better thanks to the lower VM exit/entry latency.
- HPC applications could/should benefit much more if they are recompiled to make use of the improved AVX2 and Fused Multiply Add (FMA) support
- Database transactional applications should benefit more thanks to the lower synchronization latency.
- In-memory databases should benefit if they are adapted to make use of the AVX-2 256 bit integer vector operations.
Again, the same is true about the Xeon E5-2600v3. So what makes the E7 special?
Transactional Synchronization Extensions: I'll be back
There is one "new" - or rather "now working" - feature: TSX or the famous Transactional Synchronization eXtensions. These extensions are all about making locking more "optimistic" (you let the CPU handle the bookkeeping to maintain consistency). TSX is quite powerful, but also can be a liability in the wrong use case. Developers will need a deep understanding of the locking and parallel programming to be able to make good use of TSX, as
- ... you still have to rewrite your code (inserting hints)
- TSX may reduce performance in some situations: if indeed a pessimistic lock was necessary, the transaction has to be re-executed with a "traditional" conservative way of locking. You could call it a "lock misprediction".
Introducing TSX in software requires assessing the different locks in application, using different libraries and quite a bit of of tuning. SAP and Intel did this for the expensive in-memory data mining SAP HANA software.
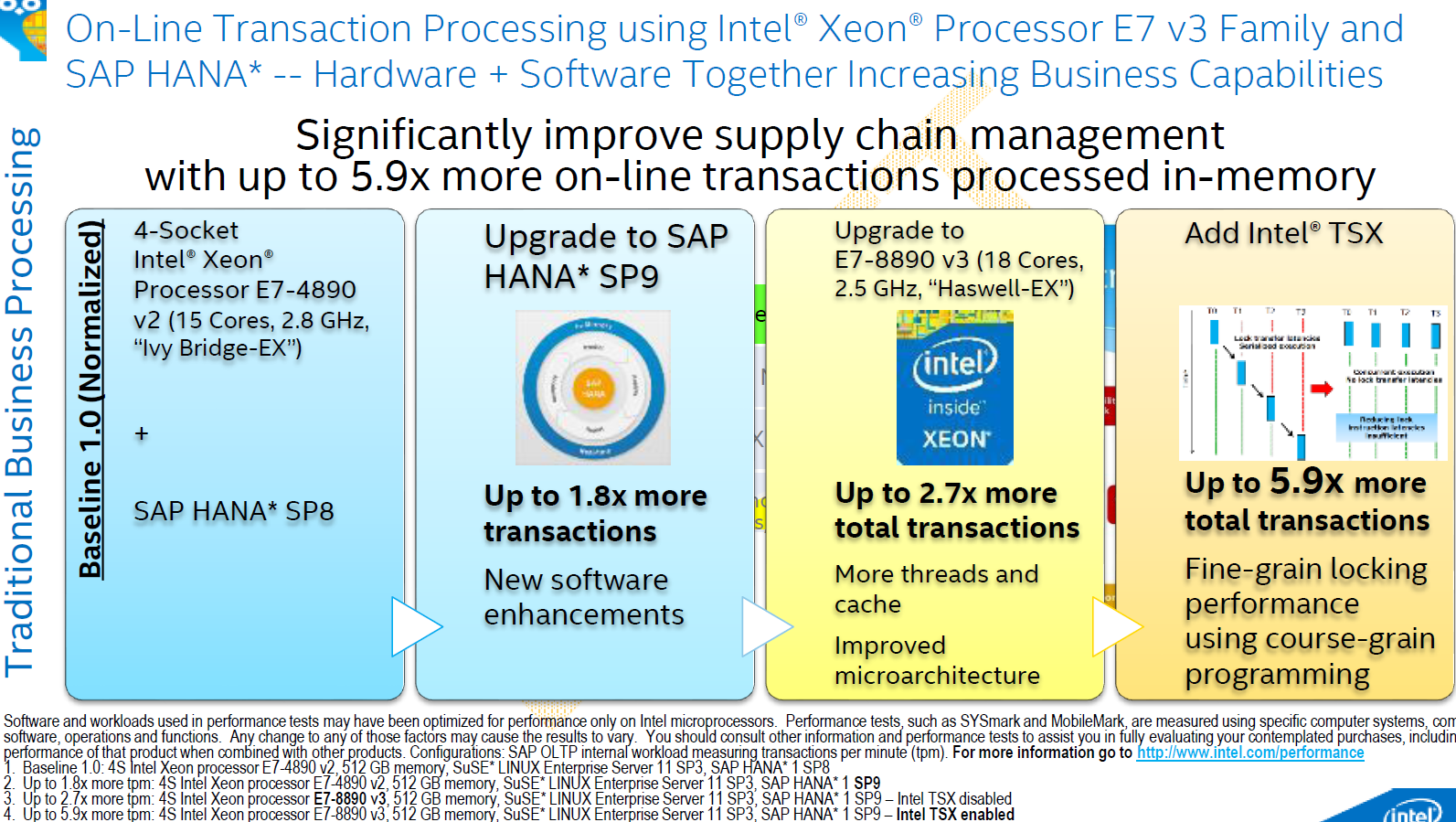
The upgrade from "Ivy Bridge EX" to "Haswell-EX" yielded 50% performance, while introducing TSX roughly doubled performance. So in TSX enabled data mining software, Haswell-EX has the potential to reduce the waiting time by a factor of 3 and more.








146 Comments
View All Comments
Brutalizer - Tuesday, May 12, 2015 - link
Again, Hana is a clustered RAM database. And as I have shown above with the Oracle TenTimes RAM database, these are totally different from a normal database. In Memory DataBases can never replace a normal database, as IMDB are optimized for reading data (analysis), not modifying data.Regarding SGI UV300H, it is a 16 socket server, i.e. scale-up server. It is not a huge scale-out cluster. And therefore UV300H might be good for business software, but I dont know the performance of SGI's first(?) scale-up server. Anyway, 16 socket servers are different from SGI UV2000 scale out clusters. And UV2000 can not be used for business software. As evidenced by non existing SAP benchmarks.
ats - Wednesday, May 13, 2015 - link
No, you haven't shown anything. You quote some random whitepaper on the internet like it is gospel and ignore the fact that in memory dbs are used daily as the primary in OLTP, OLAP, BI, etc workloads.And you don't understand that a significant number of the IMDBs are actually designed directly for the OLTP market which is precisely the DB workload that is modifying the most data and is the most complex and demanding with regard to locks and updates.
There is no architecural difference between the UV300 and the UV2k except slightly faster interconnect. And just an fyi, UV300 is like SGI's 30th scale up server. After all, they've been making scale up server for longer than Sun/Oracle.
questionlp - Monday, May 11, 2015 - link
HP Superdome X is a 16-socket x86 server that will probably end up replacing the Itanium-based Superdome if HP can scale the S/X to 32 sockets.Brutalizer - Monday, May 11, 2015 - link
HP will face great difficulties if they try to mod and go beyond 8 sockets on the old Superdome. Heck, even 8 sockets have scaling difficulties on x86.Kevin G - Monday, May 11, 2015 - link
Except that you can you buy a 16 socket Superdome X *today*.http://h20195.www2.hp.com/V2/getpdf.aspx/4AA5-6149...
The interconnect they're using for the Superdome X is from the old Poulson Itaniums that use QPI which can scale to 64 sockets.
rbanffy - Wednesday, May 13, 2015 - link
You talk "serious business workloads". Of course, there are organizations that use technology that does not scale horizontally, where adding more machines to share the workload does not work because the workload was not designed to be shared. For those, there are solutions that offer progressively less performance per dollar for levels of single-box performance that are unattainable on high-end x86 machines, but that is just because those organizations are limited by the technology they chose.There is nothing in SAP (except its design) or (non-rel) databases that preclude horizontal scaling. It's just that the software was designed in an age when horizontal scaling was not in fashion (even though VAXes have been doing clustering since I was a young boy) and now it's too late to rebuild it from scratch.
mapesdhs - Friday, May 8, 2015 - link
Good point, I wonder why they've left it at only 2/core for so long...name99 - Friday, May 8, 2015 - link
It's not easy to ramp up the number of threads. In particular POWER8 uses something I've never seen any other CPU do --- they have a second tier register file (basically an L2 for registers) and the system dynamically moves data between the two register files as appropriate.It's also much easier for POWER8 to decode 8 instructions per cycle (and to do the multiple branch prediction per cycle to make that happen). Intel could maybe do that if they reverted to a trace cache, but the target codes for this type of CPU are characterized by very large I-footprints and not much tight looping, so trace caches, loop caches, micro-op caches are not that much help. Intel might have to do something like a dual-ported I-cache, and running two fetch streams into two independent sets of 4-wide decoders.
xdrol - Saturday, May 9, 2015 - link
Another register file is just a drop in the ocean. The real problem is the increasing L1/2/.. cache pressure; what can only be mitigated by increasing cache size; what in turn will make your cache access slower, even when you use only one of the SMT threads.Also, you need to have enough unused execution capacity (pipeline ports) for another hardware thread to be useful; the 2 threads in Haswell can already saturate the 7 execution ports with quite high probability, so the extra thread can only run in expense of the other, and due to the cache effects, it's probably faster to just get the 2 tasks executed sequentially (within the same thread). This question could be revisited if the processor has 14 execution port, 2x issue, 2x cache, 2x everything, so it can have 4T/1C, but then it's not really different from 2 normal size cores with 4T..
iAPX - Friday, May 8, 2015 - link
It's because this is the same architecture (mainly) that is used on desktop, laptops, and now even mobility!With this market share, I won't be surprised that Intel decided to create a new architecture (x86-64 based) for future server chips, much more specialized, dropping AVX for cloud servers, having 4+ threads per core with simpler decoder and a lot of integer and load/store units!
That might be complemented by a Xeon Phi socketable for floating-point compute intensive tasks and workstations, but it's unclear even if Intel announced it far far ago! ;)