Intel SSD 750 PCIe SSD Review: NVMe for the Client
by Kristian Vättö on April 2, 2015 12:00 PM ESTRandom Read Performance
One of the major changes in our 2015 test suite is the synthetic Iometer tests we run. In the past we used to test just one or two queue depths, but real world workloads always contain a mix of different queue depths as shown by our Storage Bench traces. To get the full scope in performance, I'm now testing various queue depths starting from one and going all the way to up to 32. I'm not testing every single queue depth, but merely how the throughput scales with the queue depth. I'm using exponential scaling, meaning that the tested queue depths increase in powers of two (i.e. 1, 2, 4, 8...).
Read tests are conducted on a full drive because that is the only way to ensure that the results are valid (testing with an empty drive can substantially inflate the results and in reality the data you are reading is always valid rather than full of zeros). Each queue depth is tested for three minutes and there is no idle time between the tests.
I'm also reporting two metrics now. For the bar graph, I've taken the average of QD1, QD2 and QD4 data rates, which are the most relevant queue depths for client workloads. This allows for easy and quick comparison between drives. In addition to the bar graph, I'm including a line graph, which shows the performance scaling across all queue depths. To keep the line graphs readable, each drive has its own graph, which can be selected from the drop-down menu.
I'm also plotting power for SATA drives and will be doing the same for PCIe drives as soon as I have the system set up properly. Our datalogging multimeter logs power consumption every second, so I report the average for every queue depth to see how the power scales with the queue depth and performance.
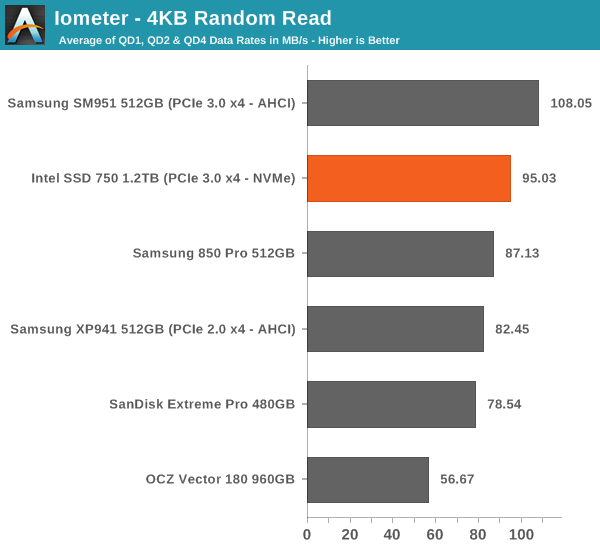
Despite having NVMe, the SSD 750 doesn't bring any improvements to low queue depth random read performance. Theoretically NVMe should be able to improve low QD random read performance because it adds less overhead compared to the AHCI software stack, but ultimately it's the NAND performance that's the bottleneck, although 3D NAND will improve that by a bit.
 |
|||||||||
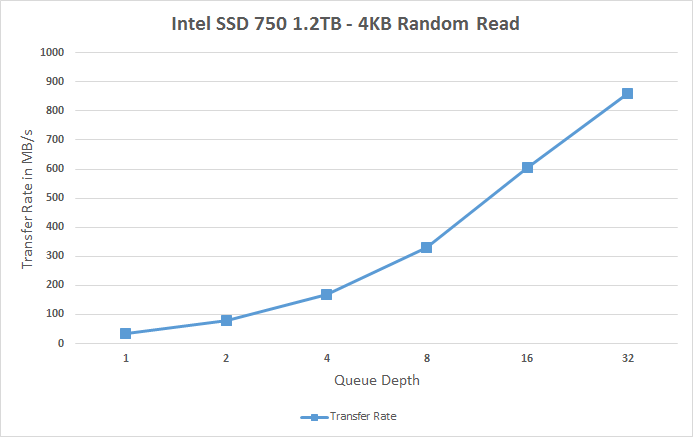
The performance does scale nicely, though, and at queue depth of 32 the SSD 750 is able to hit over 200K IOPS. It's capable of delivering even more than that because unlike AHCI, NVMe can support more than 32 commands in the queue, but since client workloads rarely go above QD32 I see no point in test higher queue depths just for the sake of high numbers.
Random Write Performance
Write performance is tested in the same way as read performance, except that the drive is in a secure erased state and the LBA span is limited to 16GB. We already test performance consistency separately, so a secure erased drive and limited LBA span ensures that the results here represent peak performance rather than sustained performance.
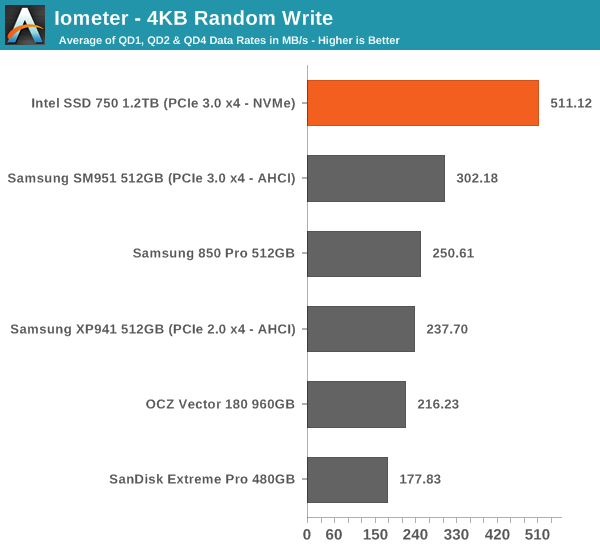
In random write performance the SSD 750 dominates the other drives. It seems Intel's random IO optimization really shows up here because the SM951 doesn't even come close. Obviously the lower latency of NVMe helps tremendously and since the SSD 750 features full power loss protection it can also cache more data in DRAM without the risk of data loss, which yields substantial performance gains.
 |
|||||||||
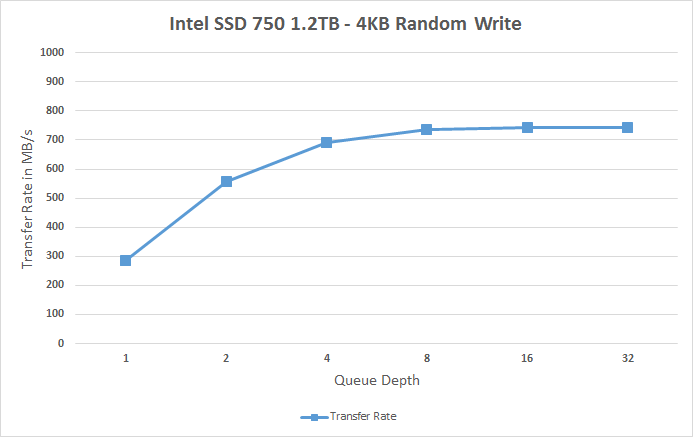
The SSD 750 also scales very efficiently and doesn't stop scaling until queue depth of 8. Note how big the difference is at queue depths of 1 and 2 -- for any random write centric workload the SSD 750 is an absolute killer.








132 Comments
View All Comments
Kristian Vättö - Friday, April 3, 2015 - link
As I explained in the article, I see no point in testing such high queue depths in a client-oriented review because the portion of such IOs is marginal. We are talking about a fraction of a percent, so while it would show big numbers it has no relevance to the end-user.voicequal - Saturday, April 4, 2015 - link
Since you feel strongly enough to levy a personal attack, could you also explain why you think QD128 is important? Anandtech's storage benchmarks are likely a much better indication of user experience unless you have a very specific workload in mind.d2mw - Friday, April 3, 2015 - link
Guys why are you cutpasting the same old specs table and formulaic article? For a review of the first consumer NVMe I'm sorely disappointed you didn't touch on latency metrics: one of the most important improvements with the NVMe busKristian Vättö - Friday, April 3, 2015 - link
There are several latency graphs in the article and I also suggest that you read the following article to better understand what latency and other storage metrics actually mean (hint: latency isn't really different from IOPS and throughput).http://www.anandtech.com/show/8319/samsung-ssd-845...
Per Hansson - Friday, April 3, 2015 - link
Hi Kristian, what evidence do you have that the firmware in the SSD 750 is any different from that found in the DC P3600 / P3700?According to leaked reports released before they have the same firmware: http://www.tweaktown.com/news/43331/new-consumer-i...
And if you read the Intel changelog you see in firmware 8DV10130: "Drive sub-4KB sequential write performance may be below 1MB/sec"
http://downloadmirror.intel.com/23931/eng/Intel_SS...
Which was exactly what you found in the original review of the P3700:
http://www.anandtech.com/show/8147/the-intel-ssd-d...
http://www.anandtech.com/bench/product/1239
Care to retest with the new firmware?
I suspect you will get identical performance.
Per Hansson - Saturday, April 4, 2015 - link
I should be more clear: I mean that you retest the P3700.And obviously the performance of the 750 wont match that, as it is based of the P3500.
But I think you get what I mean anyway ;)
djsvetljo - Friday, April 3, 2015 - link
I am unclear of which connector will this use. Does it use the video card PCI-E port?I have MSI Z97 MATE board that has one PCI-E gen3 x16 and one PCI-E gen2 x 4. Will I be able to use it and will I be limited somehow?
DanNeely - Friday, April 3, 2015 - link
if you use the 2.0 x4 slot your maximum throughput will top out at 2gb/sec. For client workloads this probably won't matter much since only some server workloads can hit situations where the drive can exceed that rate.djsvetljo - Friday, April 3, 2015 - link
So it uses the GPU express port although the card pins are visually shorter ?eSyr - Friday, April 3, 2015 - link
> although in real world the maximum bandwidth is about 3.2GB/s due to PCIe inefficiencyWhat does this phrase mean? If you're referring to 8b10b encoding, this is plainly false, since PCIe gen 3 utilized 128b130b coding. If you're referring to the overheds related to TLP and DLLP headers, this is depends on device's and PCIe RC's maximum transaction size. But, even with (minimal) 128 byte limit it would be 3.36 GB/s. In fact, modern PCIe RCs support much larger TLPs, thus eliminating header-related overheads.