Micron M600 (128GB, 256GB & 1TB) SSD Review
by Kristian Vättö on September 29, 2014 8:00 AM EST
Those that have been following the SSD industry for a couple of years are likely aware that Micron does not sell retail drives under its own brand (unlike for example Samsung and Intel). Instead Micron has two subsidiaries, Crucial and Lexar, with their sole purpose being the handling of retail sales. The Crucial side handles RAM and SSD sales, whereas Lexar is focused on memory cards and USB flash drives. The Micron crew is left with business to business sales, which consists of OEM sales as well as direct sales to some large corporations.
In the past the difference between Micron and Crucial branded SSDs has merely been the label and packaging. The M500 and M550 were the same for both brands and the Micron version of the Crucial m4 was simply called C400 instead. However, that strategy came to its end with the MX100, which was a retail (i.e. Crucial) only product. Micron decided to separate the product planning of Micron and Crucial drives and the branding was also made clearer: the M lineup is now strictly Micron; Crucial drives will be using the MX branding that was introduced with the MX100.
The main reason for the separation was the distinctive needs of the two markets. Products that are aimed towards OEMs tend to require longer validation cycles because of stricter quality requirements (a bad drive in a laptop will hurt the laptop's brand, not just the drive's brand) and PC OEMs generally do their own validation as well, which further increases the overall validation time. The retail market, on the other hand, is more focused around being the first and providing the best value, which frankly does not play very well with the long OEM validation cycles.

Since the Crucial MX100 was strictly for retail, the Micron M600 will in turn be OEM-only. The two have a lot in common as both are based on Micron's latest 128Gbit 16nm NAND, but unlike previous releases the two are not identical. The M600 comes in a variety of form factors and also includes a 1TB model, whereas the MX100 is 2.5" only and tops out at 512GB. It makes sense to offer more form factors for the OEM market because the PC laptop industry is moving more and more towards M.2 for space savings, but on the other hand the retail SSD market is still mostly 2.5" because people are upgrading older laptops and desktops that do not have mSATA or M.2 slots.
| Micron M600 Specifications | |||||
| Capacity | 128GB | 256GB | 512GB | 1TB | |
| Controller | Marvell 88SS9189 | ||||
| NAND | Micron 128Gbit 16nm MLC | ||||
| Form Factors | 2.5" 7mm, mSATA & M.2 2260/2280 | 2.5" 7mm | |||
| Sequential Read | 560MB/s | 560MB/s | 560MB/s | 560MB/s | |
| Sequential Write | 400MB/s | 510MB/s | 510MB/s | 510MB/s | |
| 4KB Random Read | 90K IOPS | 100K IOPS | 100K IOPS | 100K IOPS | |
| 4KB Random Write | 88K IOPS | 88K IOPS | 88K IOPS | 88K IOPS | |
| Idle Power (DevSleep/Slumber) | 2mW / 95mW | 2mW / 100mW | 2mW / 100mW | 3mW / 100mW | |
| Max Power | 3.6W | 4.4W | 4.7W | 5.2W | |
| Encryption | TCG Opal 2.0 & eDrive | ||||
| Endurance | 100TB | 200TB | 300TB | 400TB | |
| Warranty | Three years | ||||
Aside from the form factors and capacities, the M600 also brings something new and concrete. As I mentioned in the launch article, the M600 introduces pseudo-SLC caching to Micron's client SSDs, which Micron calls Dynamic Write Acceleration. I will talk a bit more about it in just a second but as an overview, Dynamic Write Acceleration increases the write performance at smaller capacities and also allows for higher endurance. As a result even the 128GB model is capable of 400MB/s sequential write and 88K IOPS random write and the endurance sees a boost from 72TB to 100TB despite the use of smaller lithography and higher capacity 128Gbit 16nm MLC. The endurance also scales with capacity and although the scaling is not linear, the 1TB model is rated at 400TB of host writes under typical client workloads.
Hardware encryption in the form of TCG Opal 2.0 and eDrive support has been a standard feature in Micron/Crucial client SSDs for a while now and the M600 continues that trend. Currently the M600 has not been certified by any third party software vendors (e.g. Wave and WinMagic), but Micron told us that the M600 is in the validation process as we speak and an official certification will come soon. The M600 lineup also has SKUs without any encryption support for regions where encryption is controlled by the government.
Dynamic Write Acceleration
During the past year there has been an industry-wide trend to include a pseudo-SLC cache in client-grade SSDs. The driving force behind the trend has been the transition to TLC NAND as an SLC cache is used to compensate for the slower performance and lower endurance of TLC NAND. Despite sticking with MLC NAND, the M600 has also added a pseudo-SLC feature.

Micron's implementation differs from the others in the sense that the size of the SLC cache is dynamic. While Samsung's and SanDisk's SLC caches have a fixed capacity, the M600's SLC cache size is determined by how full the drive is. With an empty drive, almost all blocks will be run in SLC mode and as the drive is filled the cache size decreases. Micron claims that even when the drive is 90% full, Dynamic Write Acceleration offers higher acceleration capacity than competing technologies, although unfortunately Micron did not share any actual numbers with us.
At the wafer level, the 128Gbit 16nm die is the same as in the MX100, but there are some proprietary processes that are applied on the die before it is packaged that enable the use of Dynamic Write Acceleration. The SLC cache is not fixed to any specific location as the firmware and special NAND allow any block to be run in either SLC or MLC mode, which is different from SanDisk's nCache 2.0 where every NAND die has a portion of blocks set in SLC mode. As a result Dynamic Write Acceleration will move data from die to die when transferring data from SLC to MLC, so there is a bit more controller and NAND interface overhead compared to SanDisk's implementation. There is no predefined threshold as to when data starts to be moved from SLC to MLC as that depends on a variety of factors, but Micron did say that idle time will trigger the migration (Micron's definition of idle time is anything over 50ms).
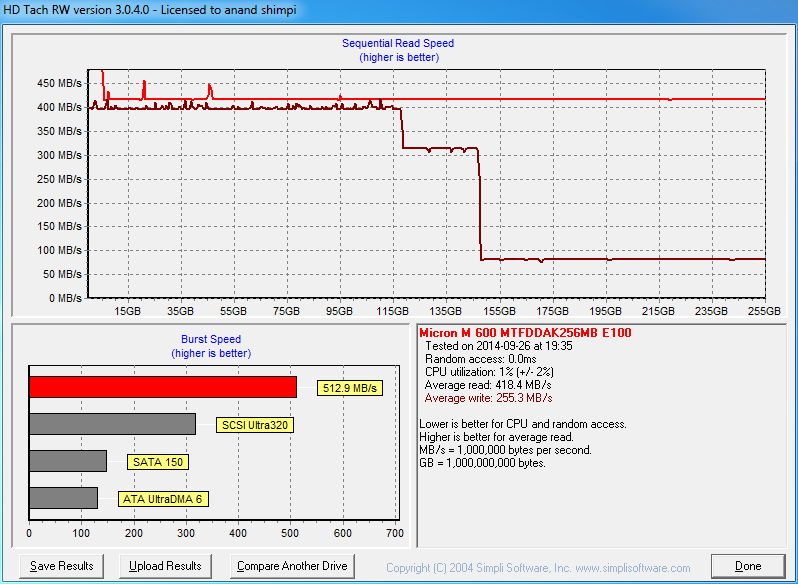
I ran HD Tach to see how the performance is affected when writing sequentially across all LBAs. You can clearly see that there are actually three stages. First writes go to SLC and performance is a steady 400MB/s, and it seems that an empty drive runs about 45% of its NAND in SLC mode. The first drop indicates that the drive is now switching to MLC NAND, hence the big difference between 128GB and 256GB models. The second drop, on the other hand, means that the drive is now moving data from SLC to MLC at the same time as it is taking in host writes, so there is significant overhead from the internal IOs that result in <100MB/s host write speeds.
Notice that Dynamic Write Acceleration is only enabled at 128GB and 256GB capacities (excluding mSATA/M.2, which have it enabled for 512GB too), so with the 512GB and 1TB models the write performance will be the same across all LBAs. The larger capacities have enough NAND for high parallelism, so DWA would not really bring any performance improvements due to SATA 6Gbps being the bottleneck.
Obviously, in real world client scenarios it is unlikely that one would constantly write to the drive like HD Tach does. Typically write bursts are no more than a few hundred megabytes at most, so all writes should hit the SLC portion at full speed. We will see how Dynamic Write Acceleration does in a more realistic scenarios in a moment.
The Truth About Micron's Power-Loss Protection
I want to begin by saying that I do not like calling out companies' marketing. I believe marketing should always be taken with a grain of salt and it is the glorified marketing that creates a niche for sites like us. I mean, if companies were truly honest and thorough in their marketing materials, you would not really need us because you could compare products by looking at the results the manufacturers publish. Hence I do not usually spend much time on how this and that feature are just buzzwords because I think it is fine as long as there is nothing clearly misleading.
But there is a limit. If a company manages to "fool" me with their marketing, then I think there is something seriously wrong. The case in point is Micron's/Crucial's client SSDs and their power-loss protection. Back when the M500 was launched a bit over a year ago, Micron introduced an array of capacitors to its client SSD and included power-loss protection as a feature in the marketing material.

I obviously assumed that the power-loss protection would provide the same level of protection as in the enterprise SSDs (i.e. all data that has entered the drive would be protected in case of a sudden power-loss) as Micron did not make any distinction between power-loss protection in client drives and power-loss protection in enterprise drives.

M500DC on the left, MX100 in the middle & M600 on the right
I got the first hint when I reviewed the M500DC. It had much larger and more expensive tantalum capacitors as the photo above shows, whereas the client drives had tiny ceramic capacitors. I figured that there must be some difference, but Micron did not really go into the details when I asked during the M500DC briefing, so I continued to believe that the client drives have power-loss protection as well, but maybe not just as robust as the enterprise drives.
In the MX100 review, I was still under the impression that there was full power-loss protection in the drive, but my impression was wrong. The client-level implementation only guarantees that data-at-rest is protected, meaning that any in-flight data will be lost, including the user data in the DRAM buffer. In other words the M500, M550 and MX100 do not have power-loss protection -- what they have is circuitry that protects against corruption of existing data in the case of a power-loss.
So, what are the capacitors there for then? To understand the technical details, I need to introduce some new terminology. Lower and upper pages stand for the two bits that are programmed to each cell in MLC NAND. Basically, lower page is the first bit and upper page is the second -- and with TLC there would be a middle page as well. Do not confuse lower and upper page terms with the typical 'page' term, though, which is used to refer to the smallest amount of data that must be written at once (usually 16KB with the currently available NAND).
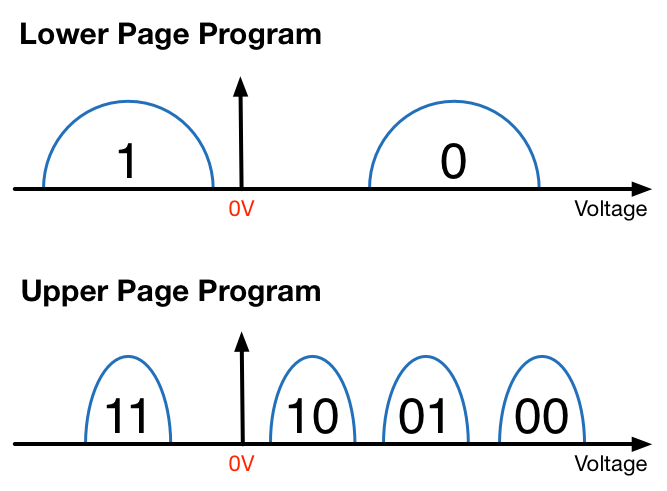
MLC NAND programming is done in two steps by programming the lower and upper pages separately, where lower page programming is essentially like SLC NAND program. If the bit of the lower page is '1', then the cell will remain empty (i.e. no charge stored). But if it is '0', then the threshold voltage is increased until it reaches the '0' state.
Once the lower page has been programmed, the upper page i.e. the second bit can be programmed to the cell. This is done by fine tuning the cell voltage to the required state because the bit of the lower page already limits the possible bit outputs to two. In other words, if the lower bit is '0', then the possible bit outputs can be either '01' or '00'. Given that the cell is already charged to '0' state during lower page programming, only a minor change is needed to tune the cell voltage to either '01" or '00' state.
The bit of the lower page being '1' does not really change anything either. If the upper page is '1' too, then the cell will remain in erased state and the bit output will be '11'. If the upper page is '0', then the cell will be charged to '10' state. Both the '1' and '0' states are more like intermediate states because the upper page will define the final cell voltage and I suspect that pseudo-SLC works by only programming the lower pages.
The reason why MLC programming is done in two steps is to reduce floating gate coupling i.e. cell-to-cell interference. I covered cell-to-cell interference in more detail in our Samsung SSD 850 Pro review, but in a nutshell the neighboring cells introduce capacitive coupling to each other and the strength of this coupling depends on the charge of the cell. Going from empty to '00' state would present such a large change in the coupling that the state of the neighboring cells might change, which in turn would corrupt the bit value.
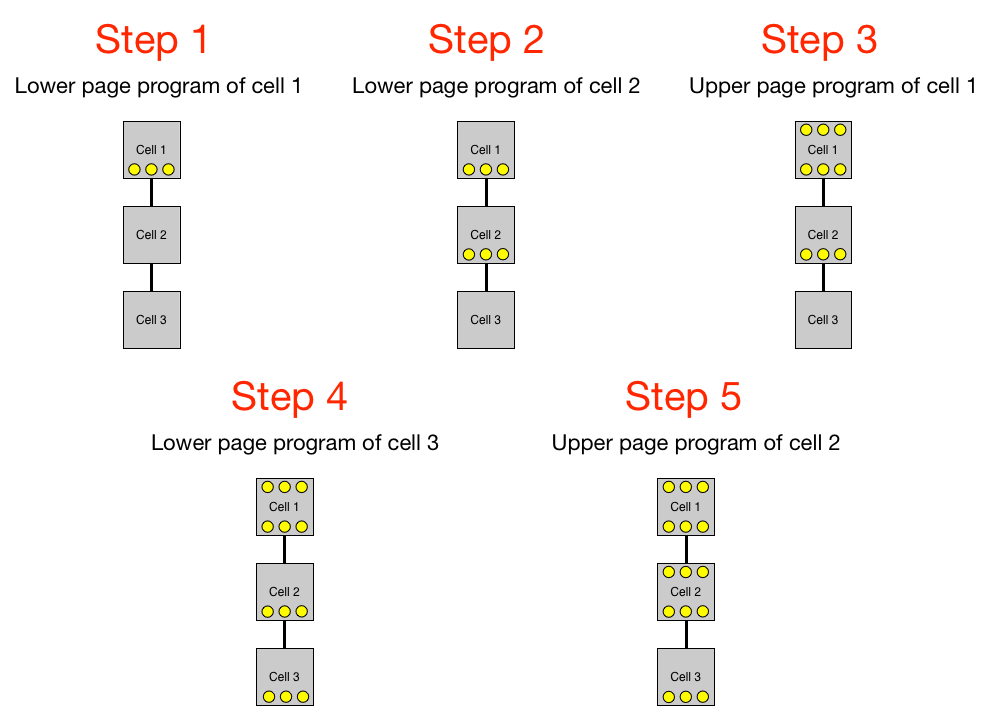
The graph above should give you a general idea of the programming algorithm. Simply put, the lower pages of neighbor cells are programmed first because lower pages have larger voltage distributions as shown above, which means that when the upper page of a neighbor cell is programmed the change in coupling is not significant enough to alter the state of the lower page.
It is time to connect this with Micron's power-loss protection. I hope everyone is still following me as that was a long and technical explanation, but I wanted to be thorough to ensure that what I say next makes sense. If power is lost during upper page program, the bit associated with the lower page of that cell may be lost. Because lower and upper page programs are not necessarily sequential, the data in the lower page might have been written earlier and would be considered data-at-rest. Thus a sudden power-loss might corrupt old data and the function of the capacitors is to ensure that the lower page data is safe. Any ongoing upper page program will not be completed and obviously all data in the DRAM buffer will be lost, but old data will be safe.
I want to apologize for spreading misinformation. I know some readers have opted for the MX100 and other Micron/Crucial drives because we said the drives feature full power-loss protection, but I hope this is not a deal-breaker for anyone. It was not Micron's or our intention to "fool" anyone into believe that the clients drives have full power-loss protection and after talking to Micron we reached an agreement that the marketing material needs to be revised to be more clear on the fact that only data-at-rest protection is guaranteed.
On the positive side, what Micron/Crucial is doing is still something that the others are not. I have not seen any other client SSDs that had capacitors to protect against lower page corruption, although there may be alternative methods to work around that (e.g. ECC). Anyway, I did not want this to come out as too negative because the capacitors still provide vital protection against data corruption -- there was just a gap between our and Micron's comprehension that lead to some misunderstandings, but that gap no longer exists.
Test Systems
For AnandTech Storage Benches, performance consistency, random and sequential performance, performance vs transfer size and load power consumption we use the following system:
| CPU | Intel Core i5-2500K running at 3.3GHz (Turbo & EIST enabled) |
| Motherboard | ASRock Z68 Pro3 |
| Chipset | Intel Z68 |
| Chipset Drivers | Intel 9.1.1.1015 + Intel RST 10.2 |
| Memory | G.Skill RipjawsX DDR3-1600 4 x 8GB (9-9-9-24) |
| Video Card | Palit GeForce GTX 770 JetStream 2GB GDDR5 (1150MHz core clock; 3505MHz GDDR5 effective) |
| Video Drivers | NVIDIA GeForce 332.21 WHQL |
| Desktop Resolution | 1920 x 1080 |
| OS | Windows 7 x64 |
Thanks to G.Skill for the RipjawsX 32GB DDR3 DRAM kit
For slumber power testing we used a different system:
| CPU | Intel Core i7-4770K running at 3.3GHz (Turbo & EIST enabled, C-states disabled) |
| Motherboard | ASUS Z87 Deluxe (BIOS 1707) |
| Chipset | Intel Z87 |
| Chipset Drivers | Intel 9.4.0.1026 + Intel RST 12.9 |
| Memory | Corsair Vengeance DDR3-1866 2x8GB (9-10-9-27 2T) |
| Graphics | Intel HD Graphics 4600 |
| Graphics Drivers | 15.33.8.64.3345 |
| Desktop Resolution | 1920 x 1080 |
| OS | Windows 7 x64 |
- Thanks to Intel for the Core i7-4770K CPU
- Thanks to ASUS for the Z87 Deluxe motherboard
- Thanks to Corsair for the Vengeance 16GB DDR3-1866 DRAM kit, RM750 power supply, Hydro H60 CPU cooler and Carbide 330R case








56 Comments
View All Comments
Kristian Vättö - Monday, September 29, 2014 - link
I thought I had that there, but looks like I forgot to add it in a hurry. Anyway, I've added it now :)MarcHFR - Tuesday, September 30, 2014 - link
Shodanshok,In fact DWA is not better for endurance, it's worst.
- Writting random writes in sequential form is already done on all SSD by write combining.
- DWA increase write amplification since the data is first wrote in "SLC" mode then rewrote in "MLC mode".
For 2 bit of data :
- 2 cells are used for SLC mode
- then 1 cell is used for MLC mode
vs
- 1 cell is used for MLC mode w/o DWA
Since write speed is rarely a problem in daily usage and since there is counterpart, i don't understand the positive reception for TurboWrite, nCache 2, Dynamic Write Acceleration, etc...
shodanshok - Tuesday, September 30, 2014 - link
Hi,it really depends on how the Write Acceleration is implemented. While it is true that badly designed WA caches can have a bad effect of flash endurance, a good designed one (and under a favorable workload) can lessen the load on the flash as a whole.
Micron is not discussing their pSLC implementation in detail, so let speak about Sandisk NCache which is more understood at the moment.
NCache works by reserving a fixed amount of NAND die to pSLC. This pSLC slice, while built on top of MLC cells, is good for, say, 10X the cycles of standard MLC (so ~30.000 cycles). The reason is simple: by using them as SLC, you have much higher margin for voltage drop.
Now, lets follow a write down to the flash. When a write arrive to the disk, it places the new data to the pSLC array. After that we have two possibilities:
1. no new write for the same LBA arrives in short time, so the pSLC array is flushed to the main MLC portion. Total writes with WA: 2 (1 pSLC / 1 MLC) - without WA: 1 (MLC)
2. if a new write is recorder for the same LBA _before_ the pSLC array is flushed, the new write will overwrite the data stored in the pSLC portion. After some idle time, the pSLC array is flushed to the MCL one. Total writes with WA: 3 (2 pSLC / 1 MLC) - without WA: 2 (MLC)
In the rewrite scenario (n.2) the MLC portion see only a single write vs the two MLC writes of the no-WA drive. While it is true that the pSLC portion sustain increased stress, its longevity is much longer than the main MLC array so it should not be a problem is their cycles are "eaten" faster. On the other hand, the MLC array is much more prone to flash wearing, so any decrease in writes are very welcomed.
This rewrite behavior is the exact reason behind SanDisk's quoted write amplification number, which is only 0.8: without Write Acceleration, a write amplification less then 1.0 can be achieved only using come compression/deduplication scheme.
Regards.
MarcHFR - Tuesday, September 30, 2014 - link
As you said it's really depend on the workload for nCache 2, write vs rewrite.But another point of view is that for example a 120 GB Ultra II with 5 GB nCache 2.0 could be a 135 GB Ultra II without NAND die reserved to nCache 2.0.
shodanshok - Tuesday, September 30, 2014 - link
True, but rewrite is quite pervasive.For example, any modern, journaled filesystem will constantly rewrite an on-disk circular buffer.
Databases use a similar concept (double-write) with another on-disk circular buffer.
The swapfile is constantly rewritten
...
Anyway, it surely remain a matter of favorable vs unfavorable workload.
Regards.
Cerb - Tuesday, September 30, 2014 - link
Only some FSes, usually with non-default settings, will double-write any file data, though. What most do is some form of meta-data journaling, where new writes preferably go into free space (one more reason not to fill your drives all the way up!), and the journal logs the writing of the new state. But, the data itself is not in the journal. EXT3/4 can be set write twice, but don't by default. NTFS, JFS, and XFS, among others, simply don't have such a feature at all. So, the additional writing is pretty minimal, being just metadata. You're not likely to be writing GBs/day to the FS journal.Databases generally should write everything twice, though, so that they never are in an unrecoverable state, if the hardware is functioning correctly.
AnnonymousCoward - Monday, September 29, 2014 - link
I have yet to get an answer to this question: what's the point of doing purely synthetic and relative-performance tests, and how does that tell the reader the tangible difference of these drives?You don't test video cards in terms of IOPS or how fast they pound through a made-up suite. You test what matters: fps.
You also test what matters for CPUs: encoding time, gaming fps, or CAD filter time.
With phones, you test actual battery time or actual page loading time.
With SSDs, why would you not test things like how fast Windows loads, program load time, and time to transfer files? That matters more than any of the current tests! Where am I going wrong, Kristian?
Kristian Vättö - Monday, September 29, 2014 - link
Proper real world testing is subject to too many variables to be truly reproducible and accurate. Testing Windows boot time and app load time is something that can be done, but the fact is that in a real world scenario you will be having more than one app running at a time and a countless number of Windows background processes. Once more variables are introduced to the test, the results become less accurate unless all variables can be accurately measured, which cannot really be done (at least not without extensive knowledge of Windows' architecture).The reasoning is the same as to why we don't test real-time or multiplayer gaming performance. It's just that the test scenarios are not fully reproducible unless the test is scripted to run the exact same scenario over and over again (like the built-in game benchmarks and our Storage Benches).
That said, I've been working on making our Storage Bench data more relevant to real world usage and I already have a plan on how to do that. It won't change the limitations of the test (it's still trace-based with no TRIM available, unfortunately), but I hope to present the data in a way that is more relevant than just pure MB/s.
AnnonymousCoward - Tuesday, September 30, 2014 - link
Thanks for your reply.You said it yourself: boot time and app load time can be done. These are 2 of the top 5 reasons people buy SSDs. To get around the "uncontrolled" nature, just do multiple trials and take the average.
Add a 3rd test: app load time while heavy background activity is going on, such as copying a 5GB file to an HDD.
4th test: IrfanView batch conversion; time to re-save 100 JPEG files.
All of those can be done on a fresh Windows install with minimal variables.
AnnonymousCoward - Tuesday, September 30, 2014 - link
To expand on my 3rd test: kick off a program that scans your hard drive (like anti-spyware or anti-virus) and then test app load time.You might be overestimating the amount of disk transfers that go on during normal computer usage. Right now, for example, I've got 7 programs open, and task manager shows 0% CPU usage on all 4 cores. It takes the same time to launch any app now as when I have 0 other programs open. So I think the test set I described would be quite representative of real life, and a massive benefit over what you're currently testing.