AMD Radeon R9 285 Review: Feat. Sapphire R9 285 Dual-X OC
by Ryan Smith on September 10, 2014 2:00 PM ESTGCN 1.2: Geometry Performance & Color Compression
Instruction sets aside, Radeon R9 285 is first and foremost a graphics and gaming product, so let’s talk about what GCN 1.2 brings to the table for those use cases.
Through successive generations of GPU architectures AMD has been iterating on and improving their geometry hardware, both at the base level and in the case of geometry generated through tessellation. This has alternated between widening the geometry frontends and optimizing the underlying hardware, with the most recent update coming in the GCN 1.1 based Hawaii, which increased AMD’s geometry processor count at the high end to 4 processors and implemented some buffering enhancements.

For Tonga AMD is bringing that 4-wide geometry frontend from Hawaii, which like Hawaii immediately doubles upon Tahiti’s 2-wide geometry frontend. Not stopping there however, AMD is also implementing a new round of optimizations to further improve performance. GCN 1.2’s geometry frontend includes improved vertex reuse (for better performance with small triangles) and improved work distribution between the geometry frontends to better allocate workloads between them.
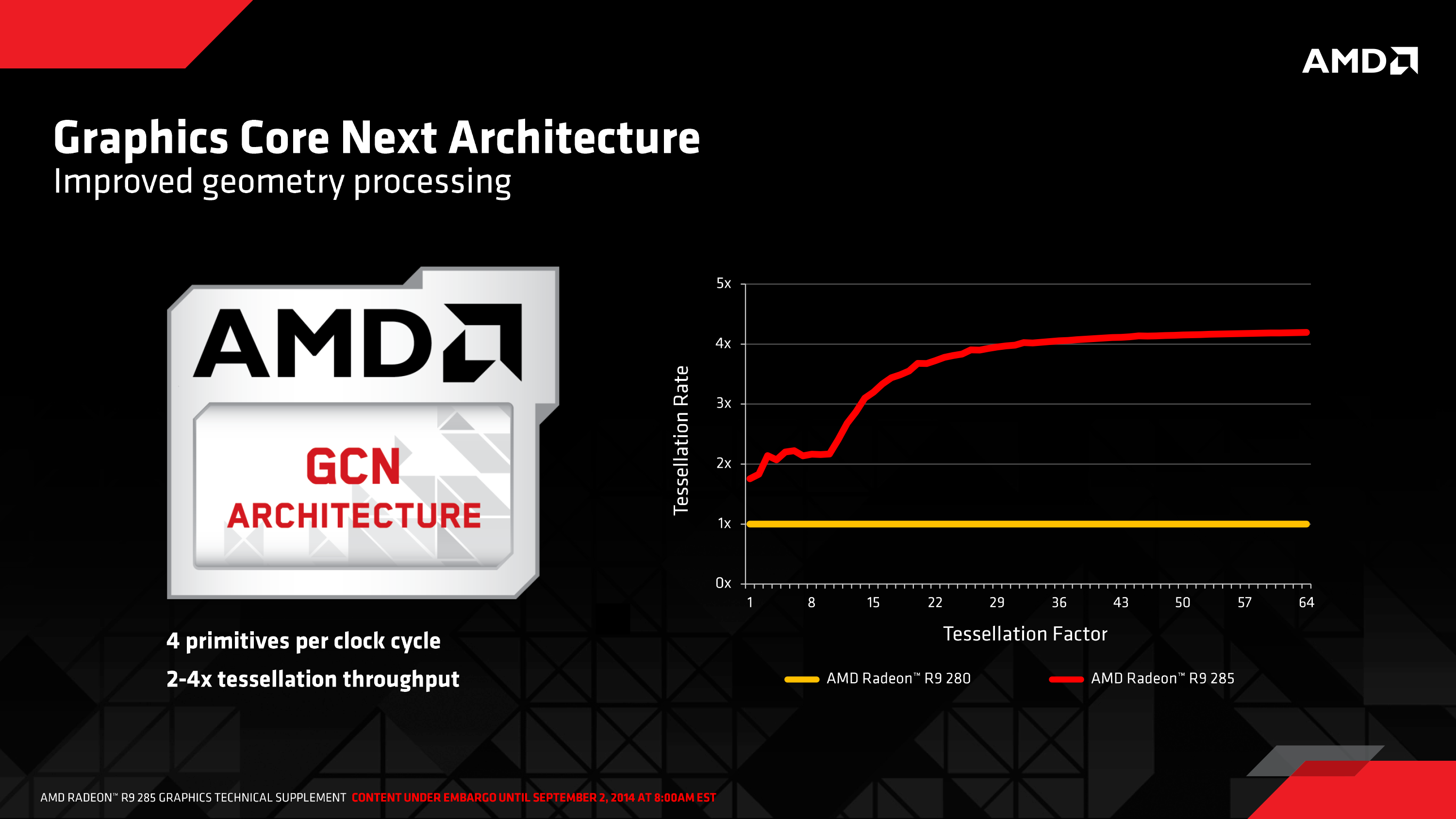
At the highest level Hawaii and Tonga should be tied for geometry throughput at equivalent clockspeeds, or roughly 2x faster than Tahiti. However in practice due to these optimizations Tonga’s geometry frontend is actually faster than Hawaii’s in at least some cases, as our testing has discovered.
Comparing the R9 290 (Hawaii), R9 285 (Tonga), and R9 280 (Tahiti) in TessMark at various tessellation factors, we have found that while Tonga trails Hawaii at low tessellation factors – and oddly enough even Tahiti – at high tessellation factors the tables are turned. With x32 and x64 tessellation, the Tonga based R9 285 outperforms both cards in this raw tessellation test, and at x64 in particular completely blows away Hawaii, coming close to doubling its tessellation performance.

At the x64 tessellation factor we see the R9 285 spit out 134fps, or equivalent to roughly 1.47B polygons/second. This is as compared to 79fps (869M Polys/sec) for the R9 290, and 68fps (748M Polys/sec) for the R9 280. One of the things we noted when initially reviewing the R9 290 series was that AMD’s tessellation performance didn’t pick up much in our standard tessellation benchmark (Tessmark at x64) despite the doubling of geometry processors, and it looks like AMD has finally resolved that with GCN 1.2’s efficiency improvements. As this is a test with a ton of small triangles, it looks like we’ve hit a great case for the vertex reuse optimizations.
Meanwhile AMD’s other GCN 1.2 graphics-centric optimization comes at the opposite end of the rendering pipeline, where the ROPs and memory controllers lie. As we mentioned towards the start of this article, one of the notable changes between the R9 280 and R9 285 is that the latter utilizes a smaller 256-bit memory bus versus the R9 280’s larger 384-bit memory bus, and as a result has around 27% less memory bandwidth than the R9 280. Under most circumstances such a substantial loss in memory bandwidth would result in a significant performance hit, so for AMD to succeed Tahiti with a smaller memory bus, they needed a way to be able to offset that performance loss.

The end result is that GCN 1.2 introduces a new color compression method for its ROPs, to reduce the amount of memory bandwidth required for frame buffer operations. Color compression itself is relatively old – AMD has had color compression in some form for almost 10 years now – however GCN 1.2 iterates on this idea with a color compression method AMD is calling “lossless delta color compression.”
Since AMD is only meeting us half-way here we don’t know much more about what this does. Though the fact that they’re calling it delta compression implies that AMD has implemented a further layer of compression that works off of the changes (deltas) in frame buffers, on top of the discrete compression of the framebuffer. In this case this would not be unlike modern video compression codecs, which between keyframes will encode just the differences to reduce bandwidth requirements (though in AMD’s case in a lossless manner).
AMD’s own metrics call for a 40% gain in memory bandwidth efficiency, and if that is the average case it would more than make up for the loss of memory bandwidth from working on a narrower memory bus. We’ll see how this plays out over our individual games over the coming pages, but it’s worth noting that even our most memory bandwidth-sensitive games hold up well compared to the R9 280, never losing anywhere near the amount of performance that such a memory bandwidth reduction would imply (if they lose performance at all).








86 Comments
View All Comments
mczak - Wednesday, September 10, 2014 - link
This is only partly true. AMD cards nowadays can stay at the same clocks in multimon as in single monitor mode though it's a bit more limited than GeForces. Hawaii, Tonga can keep the same low clocks (and thus idle power consumption) up to 3 monitors, as long as they all are identical (or rather more accurately probably, as long as they all use the same display timings). But if they have different timings (even if it's just 2 monitors), they will clock the memory to the max clock always (this is where nvidia kepler chips have an advantage - they will stay at low clocks even with 2, but not 3, different monitors).Actually I believe if you have 3 identical monitors, current kepler geforces won't be able to stick to the low clocks, but Hawaii and Tonga can, though unfortunately I wasn't able to find the numbers for the geforces - ht4u.net r9 285 review has the numbers for it, sorry I can't post the link as it won't get past the anandtech forum spam detector which is lame).
Solid State Brain - Thursday, September 11, 2014 - link
A twin monitor configuration where the secondary display is smaller / has a lower resolution than the primary one is a very common (and logic) usage scenario nowadays and that's what AMD should sort out first. I'm positively surprised that on newer Tonga GPUs if both displays are identical frequencies remain low (according to the review you pointed out), but I'm not going to purchase a different display (or limit my selection) to get advantage of that when there's no need to with equivalent NVidia GPUs.mczak - Thursday, September 11, 2014 - link
Fixing this is probably not quite trivial. The problem is if you reclock the memory you can't honor memory requests for display scan out for some time. So, for single monitor, what you do is reclock during vertical blank. But if you have several displays with different timings, this won't work for obvious reasons, whereas if they have identical timings, you can just run them essentially in sync, so they have their vertical blank at the same time.I don't know how nvidia does it. One possibility would be a large enough display buffer (but I think it would need to be in the order of ~100kB or so, so not quite free in terms of hw cost).
PEJUman - Thursday, September 11, 2014 - link
I used multimonitor with AMD & NVIDIA cards. I would take that 30W hit if it means working well.NVIDIA: too aggressive with low power mode, if you have video on one screen & game on the other, it will remain at the clock speed of the 1st event (if you start the video before the game loading, it will be stuck at the video clocks).
I used 780TI currently, R9 290x I had previously works better where it will always clock up...
hulu - Wednesday, September 10, 2014 - link
The conclusions section of Crysis: Warhead seems to be copy-pasted from Crysis 3. R9 285 does not in fact trail GTX 760.thepaleobiker - Wednesday, September 10, 2014 - link
@Ryan - A small typo on the last page, last line of first paragraph - "Functionally speaking it’s just an R9 285 with more features"It should be R9 280, not 285. Just wanted to call it out for you! :)
Bring on more Tonga, AMD!
FriendlyUser - Wednesday, September 10, 2014 - link
I would like to note that if memory compression is effective, it should not only improve bandwidth but also reduce the need for texture memory. Maybe 2GB with compression is closer to 3GB in practice, at least if the ~40% compression advantage is true.Obviously, there is no way to predict the future, but I think your conclusion concerning 2GB boards should take compression in account.
Spirall - Wednesday, September 10, 2014 - link
If GCN1.2 (instead of a GCN 2.0) is what AMD has to offer as the new arquitecture for their next year cards, Maxwell (based in 750Ti x 260X tests), will punch hard AMD in terms of performance per watt and production cost (not price) so their net income.shing3232 - Wednesday, September 10, 2014 - link
750ti use a better 28nm process call HPM while rest of the 200 series use HPL , that's the reason why maxwell are so efficient.Spirall - Wednesday, September 10, 2014 - link
I'm afraid this won't be enough (but hope it does). Anyway, as Nvidia is expected to launch their Maxwell 256 bits card nearby, we'll have the answer soon.