The AMD Radeon R9 295X2 Review
by Ryan Smith on April 8, 2014 8:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- Radeon 200
Compute
Our final set of performance benchmarks is compute performance, which for dual-GPU cards is always a mixed bag. Unlike gaming where the somewhat genericized AFR process is applicable to most games, when it comes to compute the ability for a program to make good use of multiple GPUs lies solely in the hands of the program’s authors and the algorithms they use.
At the same time while we’re covering compute performance for completeness, the high price and unconventional cooling apparatus for the 295X2 is likely to deter most serious compute users.
In any case, our first compute benchmark is LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
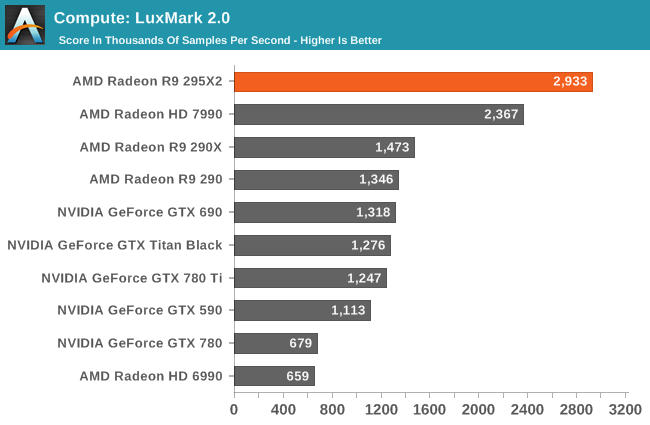
As one of the few compute tasks that’s generally multi-GPU friendly, ray tracing is going to be the best case scenario for compute performance for the 295X2. Under LuxMark AMD sees virtually perfect scaling, with the 295X2 nearly doubling the 290X’s performance under this benchmark. No other single card is currently capable of catching up to the 295X2 in this case.
Our second compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
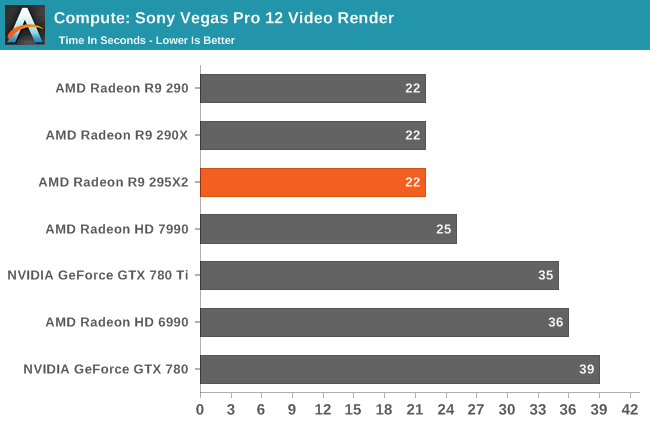
Sony Vegas Pro on the other hand sees no advantage from multiple GPUs. The 295X2 does just as well as the other Hawaii cards at 22 seconds, sharing the top of the chart, but the second GPU goes unused.
Our third benchmark set comes from CLBenchmark 1.1. CLBenchmark contains a number of subtests; we’re focusing on the most practical of them, the computer vision test and the fluid simulation test. The former being a useful proxy for computer imaging tasks where systems are required to parse images and identify features (e.g. humans), while fluid simulations are common in professional graphics work and games alike.
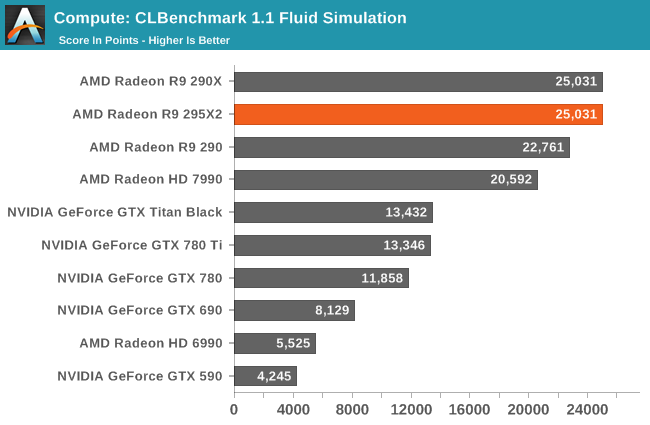
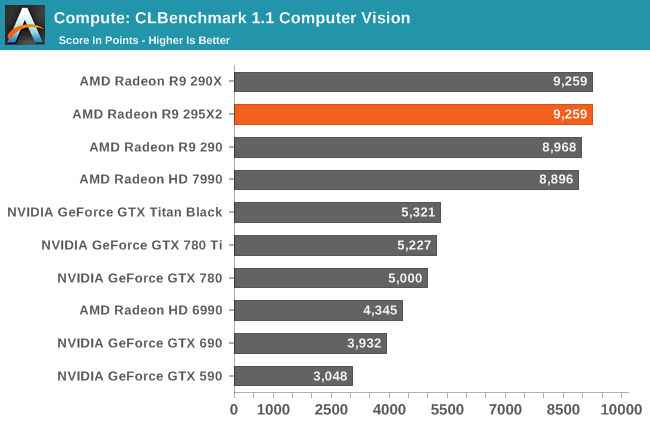
Like Vegas Pro, the CLBenchmark sub-tests we use here don't scale with additional GPUs. So the 295X2 can only match the performance of the 290X on these benchmarks.
Moving on, our fouth compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, as Folding @ Home has moved exclusively to OpenCL this year with FAHCore 17.
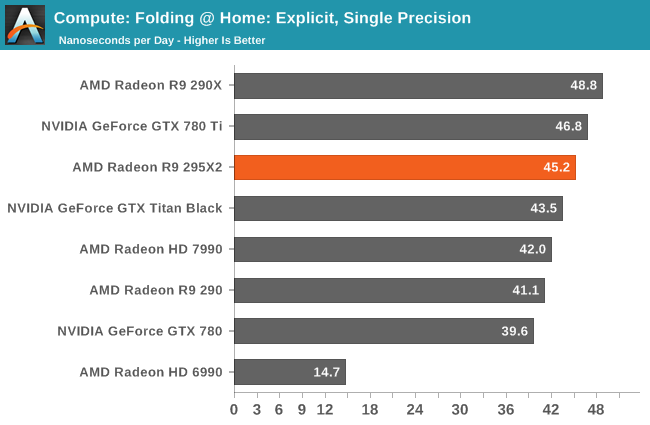
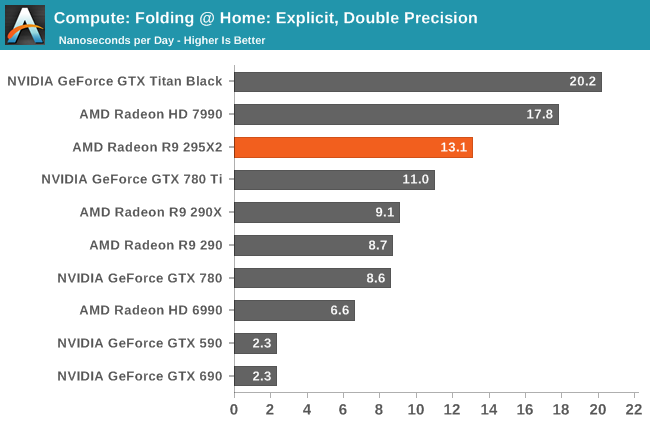
Unlike most of our compute benchmarks, Folding@Home does see some degree of multi-GPU scaling. However the outcome is really a mixed bag; single-precision performance ends up being a wash (if not a slight regression) while double-precision is seeing sub-50% scaling.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, as described in this previous article, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.

Our final compute benchmark has the 295X2 and 290X virtually tied once again, as this is another benchmark that doesn’t scale up with multiple GPUs.








131 Comments
View All Comments
mpdugas - Wednesday, April 9, 2014 - link
Time for two power supplies in this kind of build...rikm - Wednesday, April 9, 2014 - link
huh?, no giveaway? why do I read this stuff?ok, seriously, love these reviews, but the thing I never understand is when they say Titan is better, but the charts seem to say the opposite, at least for compute.
lanskywalker - Wednesday, April 9, 2014 - link
That card is a sexy beast.jimjamjamie - Thursday, April 10, 2014 - link
Great effort from AMD, I wish they would focus on efficiency though - I feel with the changing computing climate and the shift to mobile that power-hungry components should be niche, not the norm.Basically, a dual-750ti card would be lovely :)
IUU - Saturday, April 12, 2014 - link
The sad thing about all this, is that the lowest resolution for these cards is considered to be the 2560x1440 one(for those who understand).Bigger disappointment yet, that after so many years of high expectations, the gpu still stands as a huge piece of silicon inside the pc that's firmly chained by the IT industry to serve gamers only.
Whatever the reason for no such consumer applications,thiis is a crime, mildly put.
RoboJ1M - Thursday, May 1, 2014 - link
The 4870 stories that were written here by Anand were my most memorable and favourite.That and the SSD saga.
Everybody loves a good Giant Killer story.
But the "Small Die Strategy" has long since ended?
When did that end?
Why did that end? I mean, it worked so well, didn't it?
patrickjp93 - Friday, May 2, 2014 - link
People should be warned: the performance of this card is nowhere close to what the benchmarks or limited tests suggest. Even on the newest Asrock Motherboard the PCI v3 lanes bottleneck this about 40%. If you're just going to sequentially transform the same data once it's on the card, yes, you have this performance, which is impressive for the base cost, though entirely lousy for the Flop/Watt. But, if you're going to attempt to be moving 8GB of data to and from the CPU and GPU continuously, this card performs marginally better than the 290. The busses are bridge chips are going to need to get much faster for these cards to be really useful for anything outside purely graphical applications in the future. It's pretty much a waste for GPGPU computing.patrickjp93 - Friday, May 2, 2014 - link
*The busses AND bridge chips...* Seriously what chat forum doesn't let you edit your comments?Gizmosis350k - Sunday, May 4, 2014 - link
I wonder if Quad CF works with theseBlitzninjasensei - Saturday, July 12, 2014 - link
I'm trying to imagine what kind of person would have 4 of these and why, maybe EyeFinity with 4k? Even then your CPU would bottleneck way before that, you would need some kind of motherboard with dual CPU slots and a game that can take advantage of it.