The Intel Xeon E7 v2 Review: Quad Socket, Up to 60 Cores/120 Threads
by Johan De Gelas on February 21, 2014 6:00 AM EST- Posted in
- IT Computing
- Intel
- Xeon
- Ivy Bridge EX
- server
- Brickland
Bandwidth Monster
Previous versions of Intel's flagship Xeon always came with very conservative memory configurations as RAM capacity and reliability was the priority. Typically, these systems came with memory extension buffers for increased capacity, but those memory buffers also increase memory latency. As a result, these quad- and octal-socket monsters had a hard time competing with the best dual-Xeon setups in memory intensive applications.
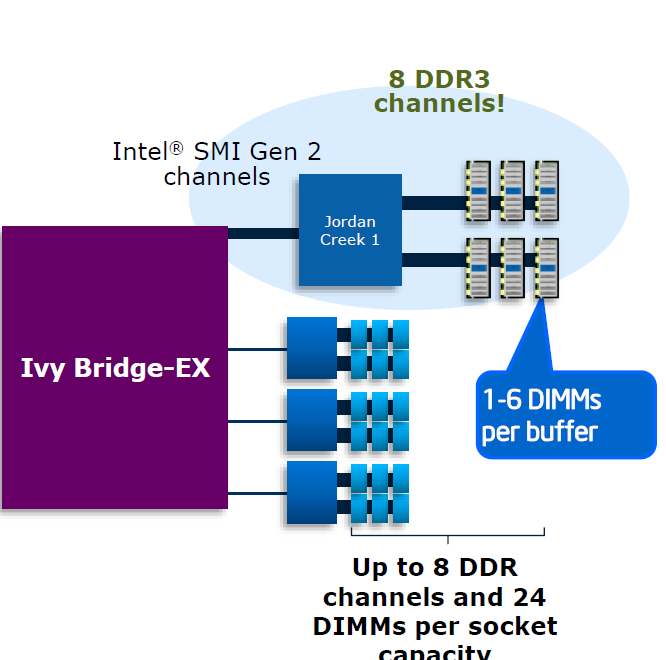
The new Xeon E7 v2 still has plenty of memory buffers (code named "Jordan Creek"), and it now supports three instead of two DIMMs per channel. The memory riser cards with two buffers now support 12 instead of eight DIMMs (Xeon Westmere-EX). Using relatively affordable 32GB DIMMs, this allows you to load a system machine up to 3TB RAM. If you break the bank and use 64GB LRDIMMs, 6TB RAM is possible.
With the previous platform, having eight memory channels only increased capacity and not bandwidth as they ran in lockstep. Each channel delivers half a cache line, then the Jordan Creek buffer combines those halves and sends off the result to the requesting memory controller. The high speed serial interface or scalable memory interconnect (SMI) channels must run at the same speed as the DDR3 channels. With Westmere-EX, this resulted in an SMI running at a maximum of 1066MHz. With the Xeon E7 v2, we get four SMI interconnects running at speeds up to 1600MHz. In lockstep, the system can survive a dual-device error. As result, the RAS (Reliability, Accessibility, Serviceability) is best in Lockstep.
With the Ivy Bridge EX version of the Xeon E7, the channels can also run independently. This mode is called performance mode and each channel can deliver one cache line. To cope with twice the amount of bandwidth, the SMI interconnect must run twice as fast as the memory channels. In this case, the SMI channel can run at 2667 MT/s while the two channels work at 1333 MT/s. That means in theory, the E7 v2 chip could deliver as much as 85GB/s (1333 * 8 channels * 8 bytes per channel) of bandwidth, which is 2.5x more than what the previous platform delivered. The disadvantage is that only a single device error can be corrected—more speed, less RAS.
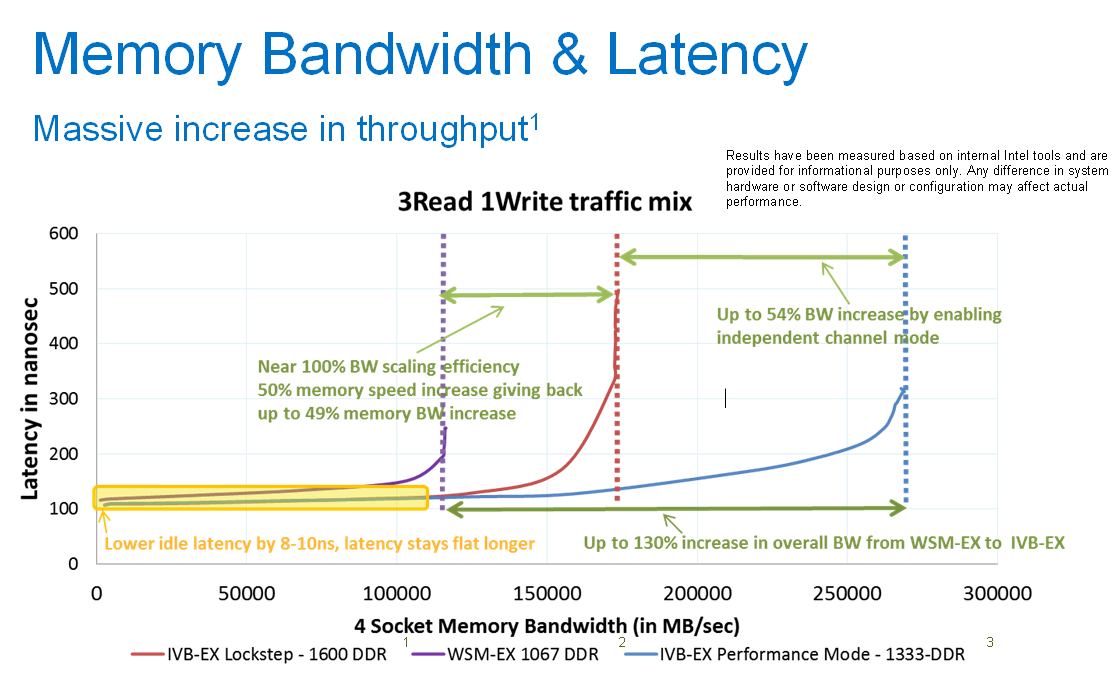
According to Intel, both latency and bandwidth are improved tremendously compared to the Westmere-EX platform. As a result, the new quad Xeon E7 v2 platform should perform a lot better in memory intensive HPC applications.








125 Comments
View All Comments
Kevin G - Friday, February 21, 2014 - link
And a quick addition:There will indeed be a quick adoption to Haswell-EX not because of AVX2 or DDR4 but rather transactional memory support (TSX). For the large databases and applications these systems are targeted at, TSX should prove to be helpful.
TiGr1982 - Friday, February 21, 2014 - link
I agree, TSX should make a lot of sense for these E7's - they have a huge core count and huge shared memory at the same time.Schmide - Friday, February 21, 2014 - link
I think your L3 latency numbers are off. I think typical Intel L3 latencies are 30-40 clocks ~3-4ns.Schmide - Friday, February 21, 2014 - link
Oops my bad i miss used the calculator. Ignore.dylan522p - Friday, February 21, 2014 - link
No power consumption numbers?JohanAnandtech - Saturday, February 22, 2014 - link
Coming...we had to run lots of test in parallel, so it was not possible to make sure all systems were similar. Also we should test with workloads that require a lot more memory to get an idea.mslasm - Friday, February 21, 2014 - link
Note that E7-8857 v2 has 12 cores but no HT, so only has 12 threads as well (see http://ark.intel.com/products/75254/Intel-Xeon-Pro... Thus it is not equivalent to a 3Ghz E7-4860V2, as 4860 has HT for a total of 24 threadsAlso, there must be a typo either in the graph or in the text on the "single thread" integer performance test: "Opteron ... at 2.4GHz would deliver about 2481 MIPs", while - according to the graph - it already delivers 2636 @ 2.3Ghz.
JohanAnandtech - Saturday, February 22, 2014 - link
Good point. There is little gain from HT in OpenFoam, but it will influence the LZMA benchmarks. So the Openfoam findings are still valid, but not the LZMA. The kernel compile is somewhat in between.JohanAnandtech - Saturday, February 22, 2014 - link
I will rerun the benchmarks without HT to check.mslasm - Saturday, February 22, 2014 - link
Thanks! I did not mean to imply HT matters "a lot", but it may influence some (and I admit I don't know much about how your benchmarks behave, other than parallel LZMA which I worked a lot with) - so it just does not sound right to outright call it equivalent, and I wish AT only has statements anyone can just trust :)