NVIDIA Tegra K1 Preview & Architecture Analysis
by Brian Klug & Anand Lal Shimpi on January 6, 2014 6:31 AM ESTThe GPU
Despite the Denver surprise, the big story behind Tegra K1 is its GPU. Prior to K1, all previous Tegra designs implemented some derivative of what became known as the GeForce ULP core. This was a non-unified architecture that, at times, looked a lot like NV40. The design was never all that impressive from a performance or power efficiency standpoint. It was cost effective and often constrained by a narrow memory interface.
Going into Project Logan, which became Tegra K1, NVIDIA made the decision (around 3 years ago) to abandon the GeForce ULP roadmap and instead combine mobile and PC GPU roadmaps. Tegra K1 would be the first design to leverage a PC GPU, in this case Kepler. The bigger implication is that all future Tegra SoCs will integrate PC GPUs. The even crazier part of all of this is that all future NVIDIA GPUs will start out as mobile first designs (including Maxwell). Productization and market availability may happen in a different order, but all architectures will start as mobile designs and then be adopted to fit other, higher power segments. This is very much like Intel’s mobile-first realization of the mid-2000s with regards to notebook processors, but with NVIDIA and smartphone/tablet GPUs.
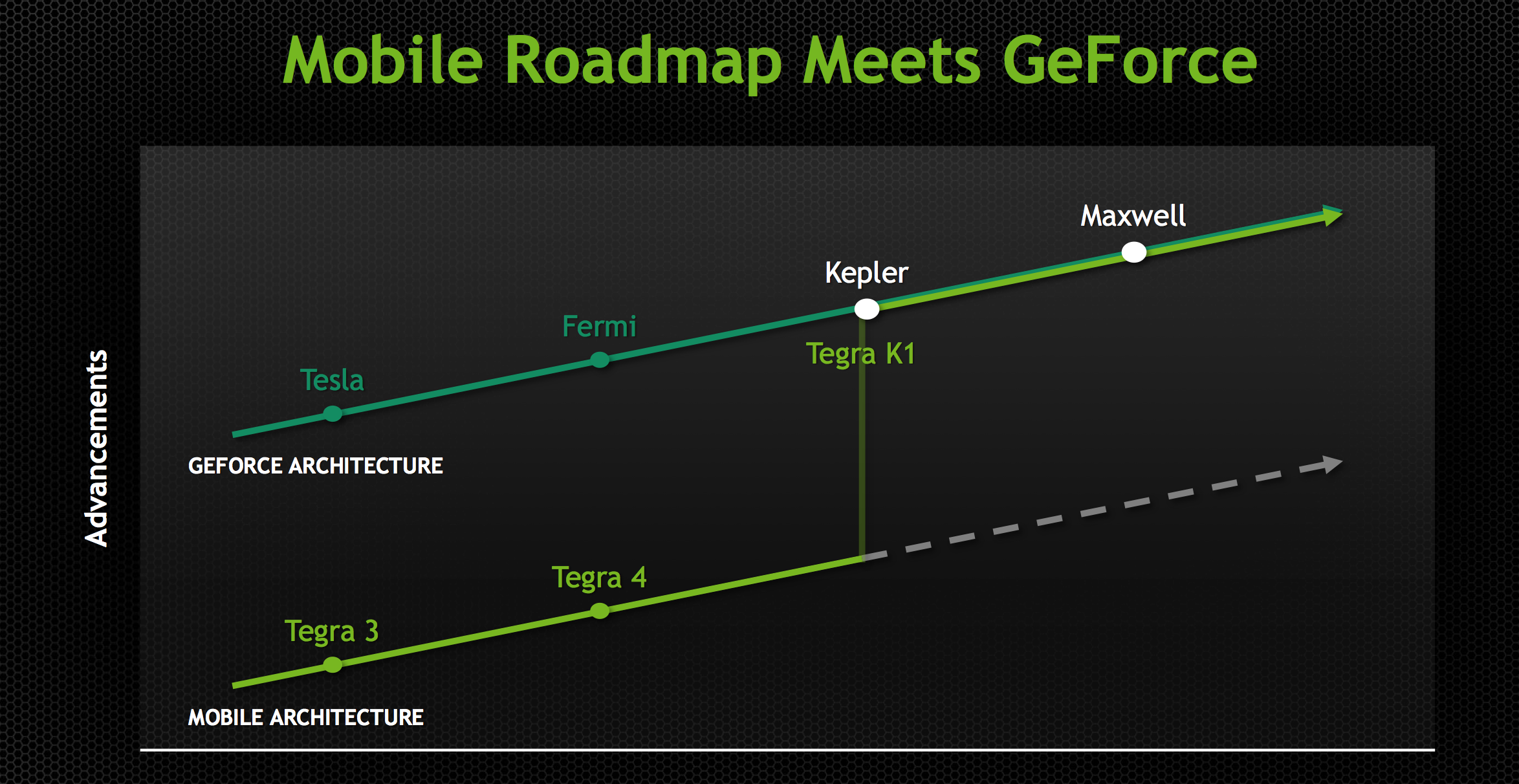
Kepler makes the move into mobile largely unchanged. This is a full Kepler implementation with the same size register file, shared L1 and is 100% ISA compatible with its big brother. It turns out that Kepler, as it was originally designed, was pretty good for mobile. If you take a GeForce 740M (2 SMX/384 CUDA core design), you’re looking at roughly a 19W GPU. Of that 19W, around 3W is memory IO, PCIe and other non-GPU things. You can subtract another 6W for leakage, bringing you down to 10W. Now that’s a 2 SMX design, so divide it in half and now you’re down to 5W. Drop the clock from 1GHz down to 900MHz, and the voltage as well, and now we’re talking around 2 - 3W for the GPU core and that’s without any re-architecting. Granted you can’t just subtract out things like leakage like that, but you get the point. Kepler wasn’t a bad starting point for a good mobile GPU design.

Tegra K1 features a single SMX (in a single GPC), which amounts to 192 CUDA cores. NVIDIA made the rookie mistake of calling Tegra K1 a 192-core processor, which made for some great headlines but largely does the industry a disservice.
Tessellation and geometry engines aren’t crippled compared to desktop Kepler. FP64 support is also present, at 1/24 the FP32 rate. There are 4 ROPs and 8 texture units, down from 16 in the PC version of Kepler. The big changes however are in the interconnects between all of the parts of the GPU.
The bigger implementations of Kepler have to be able to efficiently move data between multiple SMXes, ROPs and memory controllers. The interconnect fabric needed to do that doesn’t scale down well for mobile, where in many cases we’re dealing with one or two of those things instead of a dozen. By removing the complexity that exists in the bigger Kepler’s fabric you limit the ability for mobile Kepler to scale, but then again mobile Kepler is never going to scale to the sizes of big desktop GPUs so it’s not an issue. There are other changes outside of interconnect, with improved clock gating among other focuses on power efficiency.

NVIDIA updated the texture units to support ASTC, something that isn’t present in the desktop Kepler variants at this point. NVIDIA also hopes to use the GPU’s color compression features to reduce memory bandwidth requirements in UI rendering and not just 3D games.

With the changes NVIDIA made to the design, Kepler ends up being a < 2W GPU perfect for mobile. NVIDIA provided us with some data showing SoC + DRAM power while running GFXBench 3.0 (Manhattan), an OpenGL ES 3.0 test:
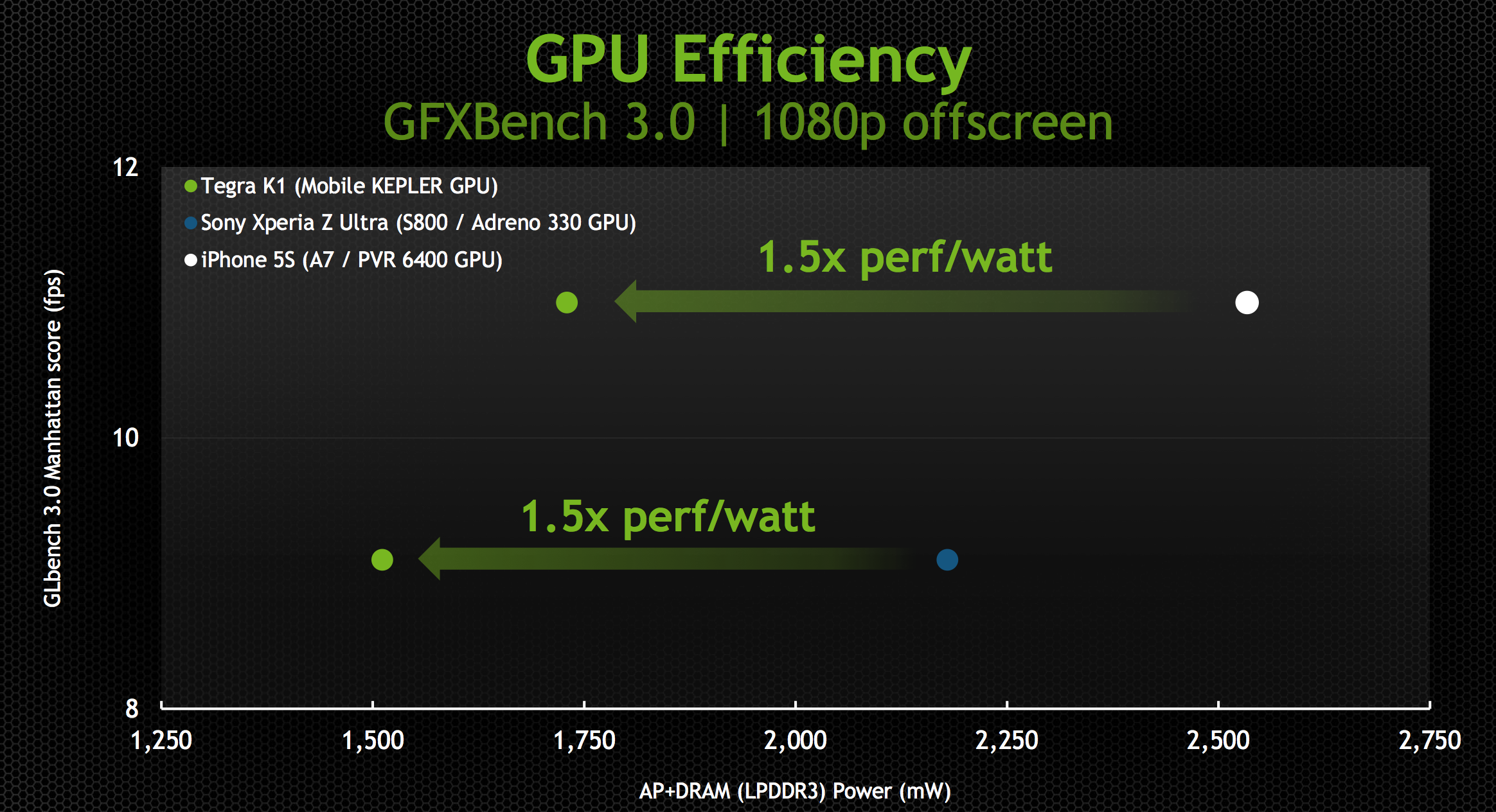
The data is presented in NVIDIA’s usual way where we’re not looking at peak performance but rather how Tegra K1 behaves when normalized to the performance of Apple’s A7 or Qualcomm’s Snapdragon 800. In both cases NVIDIA is claiming the ability to deliver equal performance at substantially better power efficiency.
NVIDIA shared some live demos that echoed the data above. Peak performance was capped to that of the A7 or Snapdragon 800, but SoC level power was always lower. It remains to be seen what power consumption looks like in a shipping configuration (which is almost always optimized for peak performance not equal performance at lower power), but it’s safe to say that concerns about Kepler being too power hungry for mobile are overrated.
The most compelling argument in favor of putting Kepler in a mobile SoC actually has to do with its API support. In one swift move NVIDIA goes from being disappointing in API support to industry leading. Since this is a full Kepler implementation (just a lower power/performing version) Tegra K1 maintains full API compatibility with NVIDIA’s flagship GeForce products. OpenGL ES 3.0 is supported but so are full OpenGL 4.4, DX11 and CUDA 6.0.

NVIDIA made it a point to say that high-end games developed for the PC or even current generation consoles could be ported over to Tegra K1 without issue. It’s perhaps over reaching a bit to claim the latter given the delta in performance (which NVIDIA hopes to make up in 4 generations!), but you can definitely argue that titles built for the previous generation of consoles (Xbox 360/PS3) could easily be ported to Tegra K1.
At its CES press conference NVIDIA teased the idea that Tegra K1 is actually more powerful than the last generation of consoles. The slide below attempts to drive that point home:
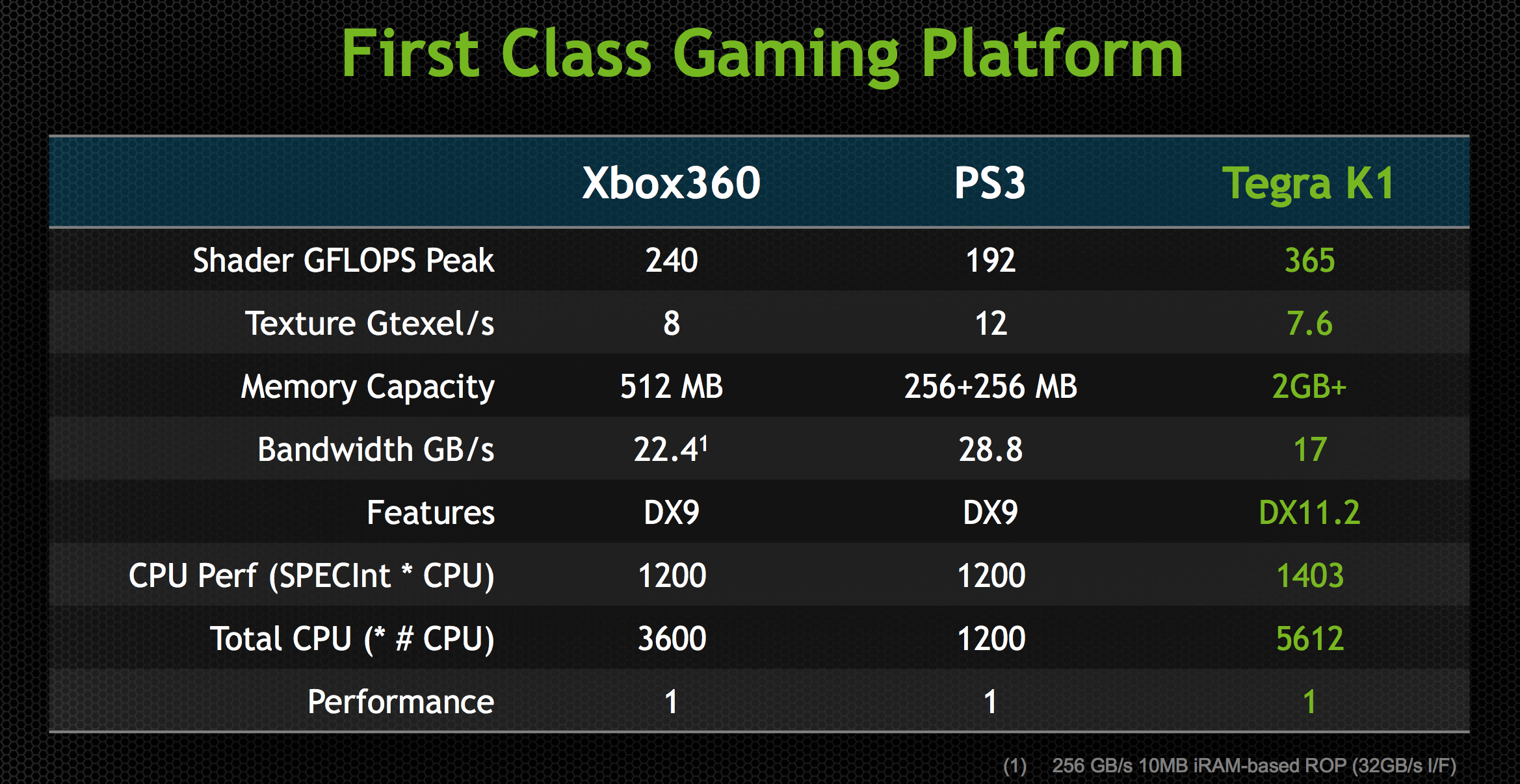
With a GPU clock of 950MHz (admittedly, a bit on the high end), NVIDIA can deliver substantially more raw horsepower than either previous generation console (192 CUDA cores * 2 FLOPS per core * 950MHz). Peak texture filtering performance and more importantly, memory bandwidth are lower than what was possible on these consoles but the numbers we’re talking about here aren’t substantial enough to prevent porting from happening. There may be some optimization needed but it definitely looks like Tegra K1 is the first mobile platform that can more or less run Xbox 360/PS3 titles, at least from a performance standpoint.
In pursuit of making porting and game development as simple as possible, NVIDIA demonstrated its NSight Tegra plugins for Visual Studio. Without changing the IDE that developers are used to, NSight Tegra allows developers to use the NDK toolchain all within Visual Studio. I’m not enough of a developer to know whether or not NVIDIA’s efforts in this space truly make life easy enough to port Xbox 360/PS3 games over to Android, but its VS integration demos looked convincing at least.
NVIDIA had a port of Serious Sam 3 running on Tegra K1 demo hardware just fine. Any games that are prepped for Steam OS are very easy to port over to Android. Once you make the move to OpenGL, the rest is allegedly fairly simple. The Serious Sam 3 port apparently took a matter of a couple of weeks to get ported over, with the bulk of the effort going into mapping controls to an Android environment.








88 Comments
View All Comments
jerrylzy - Tuesday, January 7, 2014 - link
Exactly. I don't see Loki726's point of gamers paying extra $ for Double Precision. AMD Cards are generally much cheaper at the same performance level, though at the cost of power consumption.Loki726 - Tuesday, January 7, 2014 - link
I mean compared to a world where AMD decided to rip out the double precision units. There are obviously many (thousands) other factors that do into the efficiency of a GPU.jerrylzy - Tuesday, January 7, 2014 - link
Unfortunately, instead of using VLIW 5, Qualcomm implemented new scalar architecture way back in adreno 320.Loki726 - Tuesday, January 7, 2014 - link
Yep, the have improved on it, but they started with the AMD design. My point was that the Qualcomm GPU is a better comparison point to a Tegra SoC than an AMD desktop part.ddriver - Wednesday, January 8, 2014 - link
The decision to chose Qualcomm in favor of Tegra would be based entirely on the absence of OpenCL support in Tegra. Exclusive cuda? Come on, who would want to invest into writing a parallel accelerated high performance routine that only works on like no more than 5% of the hardware-capable to run it devices? Not me anyway.The mention of the radeon was regarding a completely different point - that nvidia sacks DP performance even where it makes no sense to, and is IMO criminal to do so - the "gain" of such a terrible DP implementation is completely diminished by the loss of potential performance and possibility of accelerating a lot of professional workstation software. And for what, so the only spared parts - the "professional" products can have their ridiculous prices better "justified"? Because it is such a sweet deal to make a product 10% more expensive to make and ask 5000% more money for it.
Which is the reason AMD offers so much more value, while limp and non-competitive in the CPU performance, the place where computation is really needed - professional workstation software can greatly benefit from parallelization, and the much cheaper desktop enthusiast product actually delivers more raw computational power than the identical, but more conservatively clocked fireGL analog. Surely, fireGL still has its perks - ECC, double the memory, but those advantages shine in very rare circumstances, in most of the professional computation demanding software the desktop part is still an incredibly lucrative investment, something you just don't get with nvidia because of what they decided to do the last few years, coincidentally the move to cripple DP performance to 1/24 coincided with the re-pimping of the quadros into the tesla line. I think it is rather obvious that nvidia decided to shamelessly milk the parallel supercomputing professional market, something that will backfire in their face, especially stacking with the downplay-ment of OpenCL in favor of a vendor exclusive API to use the hardware.
Loki726 - Wednesday, January 8, 2014 - link
Agreed with the point about code portability, but that's an entirely different issue. I'd actually take the point further and say that OpenCL is too vendor specific -> it only runs on a few GPUs and has shaky support on mobile. Parallel code should be a library like pthreads, C++ (or pick your favorite language) standard library threads, or MPI. Why program in a new language that is effectively C/C++, except that it isn't?I personally think that if a company artificially inflates the price of specific features like double precision, then they leave themselves open to being undercut by a competitor and they will either be forced to change it or go out of business. As I said, AMD's design choice penalizes gamers, but helps users who want compute features, and NVIDIA's choice benefits gamers, but penalizes desktop users who want the best value for some compute features like double precision.
I have a good understanding of circuit design and VLSI implementation of floating point units and I can say that the area and power overheads of adding in 768 extra double precision units to a Kepler GPU or 896 double precision units to a GCN GPU would be noticeable, even if you merged pairs of single precision units together and shared common logic (which would create scheduling hazards at the uArch level that could further eat into perf, and increase timing pressure during layout).
Take a look at this paper from Mark Horowitz (an expert) that explores power and area tradeoffs in floating point unit design if you don't believe me. It should be easy to verify. http://www.cpe.virginia.edu/grads/pdfs/August2012/... . Look at the area and power comparisons in Table 1, scale them to 28nm, and multiply them by ~1000x (to get up to 1/2 or 1/4 of single precision throughput).
Double precision units are big, and adding a lot of them adds a lot of power and area.
Krysto - Saturday, January 11, 2014 - link
I want to believe OpenCL was left out because they've been trying to squeeze so much in this time-frame already. But since they fully ported everything in one swoop, I still find it hard to believe they didn't omit it on purpose. Hopefully, they'll support OpenCL 2.0 in Maxwell, because OpenCL 2.0 also offers some great parallelism features, which Maxwell could take advantage of.Andromeduck - Wednesday, January 8, 2014 - link
Isn't that what the GTX Titan is for?Jon Tseng - Monday, January 6, 2014 - link
Sounds very interesting. The Q for me though as you allude to at the end is whether they can recruit devs to utilise this. Especially when mobile games are a freemium dominated world the temptation is to code for lowest common denominator/max audience, probably with a Samsung label on it (I'm not complaining - its whats enabled me to run World of Tanks happily on my Bay Trail T100!).World beating GPU tech no use unless people are utilising it. Interesting thought about getting MSFT on board though - I guess the downer is that Windows Phone is a minority sport still, and tablet wise it would have to be Windows RT... :-x
nicolapeluchetti - Monday, January 6, 2014 - link
The processing power might be the same as the X-Box 360-PS 3 but using Direct X doesn't incur in a performance Hit?