Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
The Silvermont Module and Caches
Like AMD’s Bobcat and Jaguar designs, Silvermont is modular. The default Silvermont building block is a two-core/two-thread design. Each core is equally capable and there’s no shared execution hardware. Silvermont supports up to 8-core configurations by placing multiple modules in an SoC.
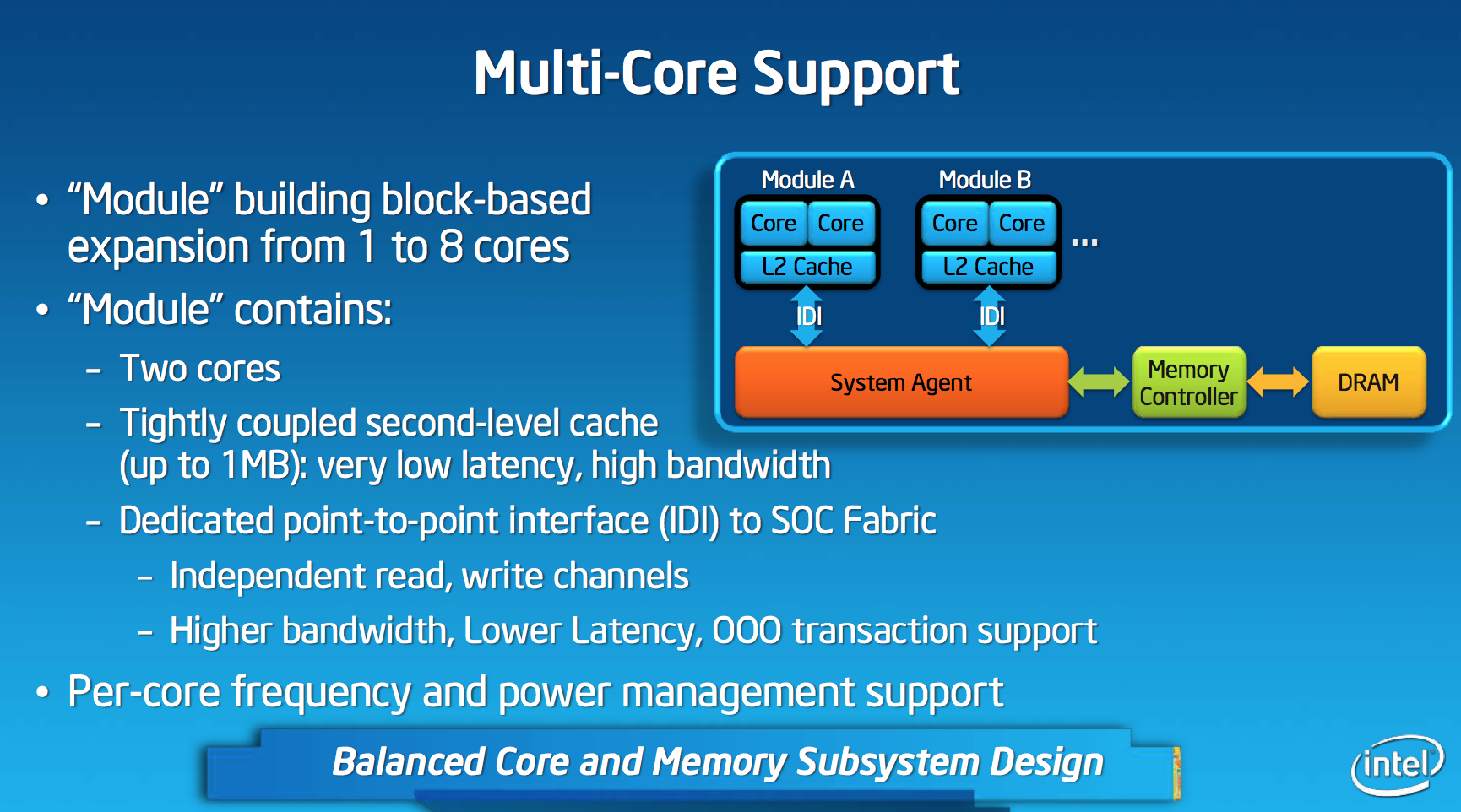
Each module features a shared 1MB L2 cache, a 2x increase over the core:cache ratio of existing Atom based processors. Despite the larger L2, access latency is reduced by 2 clocks. The default module size gives you clear indication as to where Intel saw Silvermont being most useful. At the time of its inception, I doubt Intel anticipated such a quick shift to quad-core smartphones otherwise it might’ve considered a larger default module size.
L1 cache sizes/latencies haven’t changed. Each Silvermont core features a 32KB L1 data cache and 24KB L1 instruction cache.
Silvermont Supports Independent Core Frequencies: Vindication for Qualcomm?
In all Intel Core based microprocessors, all cores are tied to the same frequency - those that aren’t in use are simply shut off (power gated) to save power. Qualcomm’s multi-core architecture has always supported independent frequency planes for all CPUs in the SoC, something that Intel has always insisted was a bad idea. In a strange turn of events, Intel joins Qualcomm in offering the ability to run each core in a Silvermont module at its own independent frequency. You could have one Silvermont core running at 2.4GHz and another one running at 1.2GHz. Unlike Qualcomm’s implementation, Silvermont’s independent frequency planes are optional. In a split frequency case, the shared L2 cache always runs at the higher of the two frequencies. Intel believes the flexibility might be useful in some low cost Silvermont implementations where the OS actively uses core pinning to keep threads parked on specific cores. I doubt we’ll see this on most tablet or smartphone implementations of the design.
From FSB to IDI
Atom and all of its derivatives have a nasty secret: they never really got any latency benefits from integrating a memory controller on die. The first implementation of Atom was a 3-chip solution, with the memory controller contained within the North Bridge. The CPU talked to the North Bridge via a low power Front Side Bus implementation. This setup should sound familiar to anyone who remembers Intel architectures from the late 90s up to the mid 2000s. In pursuit of integration, Intel eventually brought the memory controller and graphics onto a single die. Historically, bringing the memory controller onto the same die as the CPU came with a nice reduction in access latency - unfortunately Atom never enjoyed this. The reasoning? Atom never ditched the FSB interface.
Even though Atom integrated a memory controller, the design logically looked like it did before. Integration only saved Intel space and power, it never granted it any performance. I suspect Intel did this to keep costs down. I noticed the problem years ago but completely forgot about it since it’s been so long. Thankfully, with Silvermont the FSB interface is completely gone.
Silvermont instead integrates the same in-die interconnect (IDI) that is used in the big Core based processors. Intel’s IDI is a lightweight point to point interface that’s far lower overhead than the old FSB architecture. The move to IDI and the changes to the system fabric are enough to improve single threaded performance by low double digits. The gains are even bigger in heavily threaded scenarios.
Another benefit of moving away from a very old FSB to IDI is increased flexibility in how Silvermont can clock up/down. Previously there were fixed FSB:CPU ratios that had to be maintained at all times, which meant the FSB had to be lowered significantly when the CPU was running at very low frequencies. In Silvermont, the IDI and CPU frequencies are largely decoupled - enabling good bandwidth out of the cores even at low frequency levels.
The System Agent
Silvermont gains an updated system agent (read: North Bridge) that’s much better at allowing access to main memory. In all previous generation Atom architectures, virtually all memory accesses had to happen in-order (Clover Trail had some minor OoO improvements here). Silvermont’s system agent now allows reordering of memory requests coming in from all consumers/producers (e.g. CPU cores, GPU, etc...) to optimize for performance and quality of service (e.g. ensuring graphics demands on memory can regularly pre-empt CPU requests when necessary).








174 Comments
View All Comments
Homeles - Monday, May 6, 2013 - link
Yay confirmation bias!R0H1T - Tuesday, May 7, 2013 - link
Nay, you fanboi(Intel's) much ?powerarmour - Monday, May 6, 2013 - link
Have to agree, starting to get tired of these almost Intel PR based previews. No mention to how poor Intel's graphics drivers have consistently been over many many years.Homeles - Monday, May 6, 2013 - link
"You can't make the ridiculous claims of 1.6x performance."Sure you can. It was already a close race between a 5 year old architecture and a brand new one. The floodgates have opened -- this is 5 years of pent up performance gains from the largest R&D spender in the industry, on top of being on a significantly superior process for mobile devices.
Wilco1 - Monday, May 6, 2013 - link
Absolute performance of Silvermont cannot be higher than A15 or Bobcat, it's just 2-way OoO, has a single-issue in-order memory pipeline (no speculative execution of memory operations or dual issue of load-store like A15/Bobcat) and fairly small buffers in general. All in all it is more like A9 than A15 or Bobcat/Jaguar.althaz - Monday, May 6, 2013 - link
Except that it certainly can (dependent on a lot of other factors)...That said, I suspect it will only be faster at the same power level, not at the same frequency.
beginner99 - Tuesday, May 7, 2013 - link
That's covered in the article but I must admit I don't fully understand it. Anyway Anand writes about macro-op fusion and clearly states that because of this the 2-wide is misleading when directly comparing to ARM. My interpretation being that ARM doesn't have this and if your 2-wide CPU is running macro-ops with 2 instructions in them it's actually like 4-wide (but I guess this naive viewpoint of mine is completely wrong.Wilco1 - Tuesday, May 7, 2013 - link
No, macro-ops don't make your CPU magically wider. For example Silvermont cannot actually execute 2 load+op instructions every cycle, and cannot even execute 1 read-modify-write every cycle...Also note that most ARM CPUs do have similar capabilities, for example Cortex-A9 can execute 2 shifts and 2 ALU instructions every cycle, and loads and stores can have base update for free. So Anand is quite wrong claiming this is an advantage to Atom.
As I mentioned, the big bottleneck of Silvermont is it's single load/store unit. Typical code contains many loads and stores, and Cortex-A15 can execute these twice as fast as Silvermont.
Jaybus - Wednesday, May 8, 2013 - link
It can, however, execute 1 load and 1 store simultaneously, and that is its saving grace. That fits very well with code being executed in OoO fashion and why I doubt very much A15 is twice as fast executing typical code.Wilco1 - Thursday, May 9, 2013 - link
No Silvermont can only execute 1 load or 1 store per cycle. A15 won't be twice as fast on typical code, but it will beat Silvermont on memory intensive code due to its single memory pipeline bottleneck.