Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
Tablet Expectations
Intel is getting architectural details about Silvermont launch ahead of actual SoCs based on the CPU. Baytrail tablets based on Silvermont cores are currently in development and are expected to show up by the end of the year. The Silvermont story at the end of this year should be a lot better than Clovertrail last year. Windows 8 will be in its second major revision (codename Windows Blue) and Intel will launch with both Android and Windows tablet availability. The inclusion of Android is very important to hitting lower price points, something Clovertrail really didn’t have last year. We should see Baytrail based tablets span the gamut of Nexus 7 to iPad pricing, with Haswell picking up where Silvermont ends.
Form factors should be no thicker than Clovertrail based designs, although it will be possible to go thinner with Baytrail/Silvermont should an OEM decide to. Displays should also be a lot better this time around. Intel is working with some OEMs on color calibration, an important step forward as I’m hearing Qualcomm will be doing the same with Snapdragon 800. We’ll also finally see resolutions higher than 1366x768, including potentially some competition for the iPad with Retina Display. Silvermont’s new system agent should do a good job of prioritizing GPU access to main memory in these ultra high resolution scenarios.
Performance
With tablets still months away from being production ready, there’s nothing for us to publicly test. Intel did share some of its own numbers off of its Baytrail reference tablet however, and they are impressive.
All of the Intel comparisons report the geometric mean performance advantage over a spectrum of benchmarks. The benchmarks used include SPECint2K, CoreMark, SunSpider, web page load tests in IE/Chrome/Firefox, Linpack, AnTuTu and Quadrant (ugh) among others. The point here isn’t to demonstrate absolute peak performance in one benchmark, but to instead give us a general idea of the sorts of gains we should expect to see from Silvermont/Baytrail tablets vs the competition. It’s an admirable effort and honestly the right way to do things (short of actually giving us a pre-production tablet to test that is). We’ll start with a comparison to Saltwell, the previous-generation 32nm Atom core. The Saltwell results are listed as STW while Silvermont is abbreviated SLM:
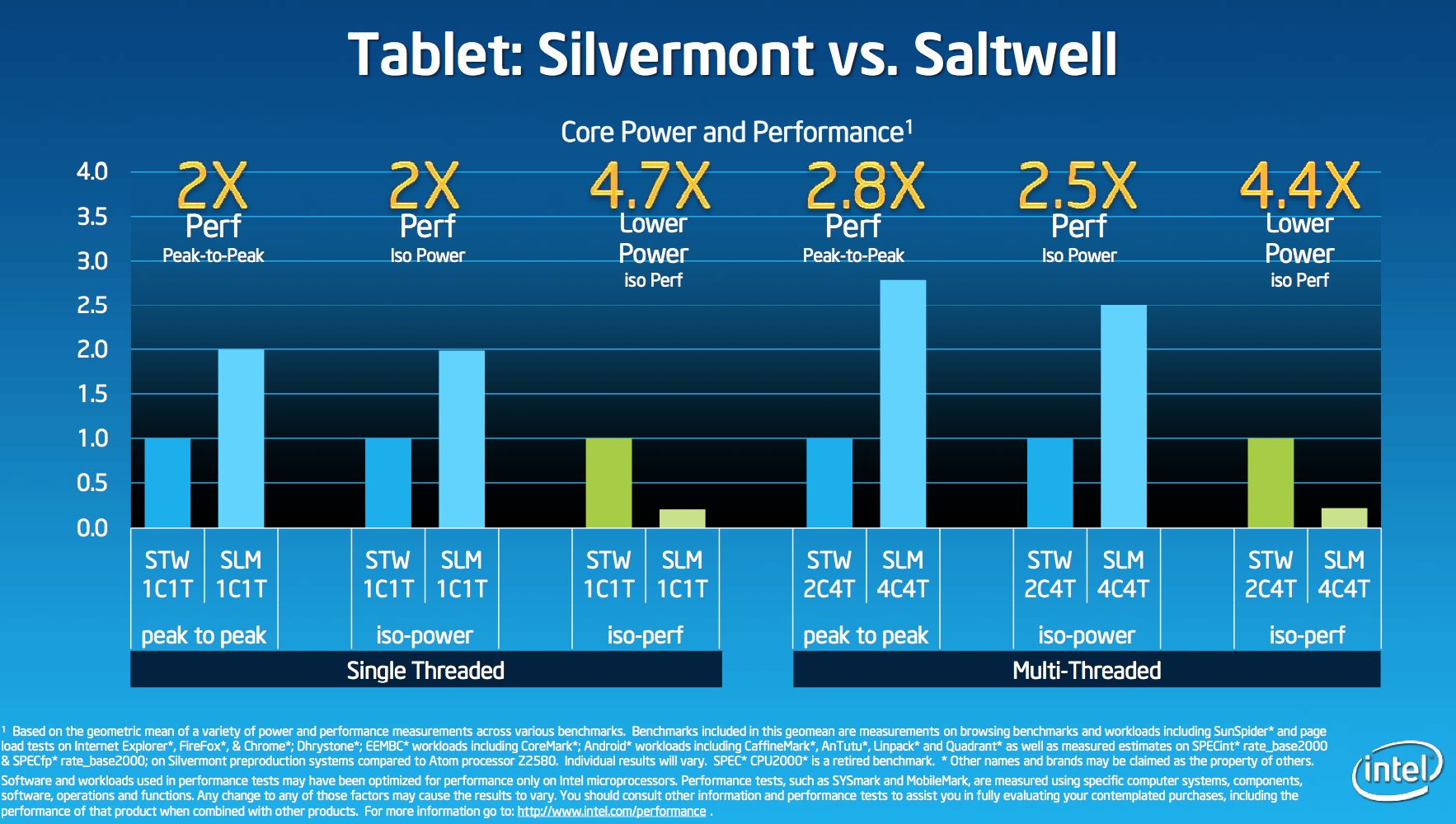
In terms of absolute performance, Silvermont’s peak single threaded performance is 2x that of Saltwell. This 2x gain includes IPC and clock frequency gains (only 50% is from IPC, the rest is due to IDI, system agent and frequency). Given that Saltwell is competitive with existing architectures from ARM and Qualcomm (except for the Cortex A15), a 2x increase in single threaded performance should put Silvermont in a leadership position when it arrives later this year.
The next set of bars is just as important. At the same power levels (Intel didn’t disclose specifically at what power), Silvermont delivers 2x the performance of Saltwell. Finally, at the same performance level, Silvermont uses 4.7x lower power. Given that Saltwell wasn’t terrible on power to begin with, this is very impressive. Without knowing the specific power and performance levels however, I wouldn’t draw too many conclusions based on this data though.
The multithreaded advantages are obviously even greater as Silvermont will be featured in quad-core configurations while Saltwell topped out at dual-core (4 threads) in tablets.
In the next two slides, Intel did some competitive analysis with Silvermont vs. the ARM based competition. The benchmarks are the same, but now we have specifics about power usage. In the first test Intel is comparing to three competitors all with quad-core designs. Intel claims to have estimated performance gains based on what is expected to be in the market by the end of this year. Intel’s performance modeling group is very good at what it does, but as with any estimate you always have to exercise some caution in buying the data until we have physical hardware in hand.
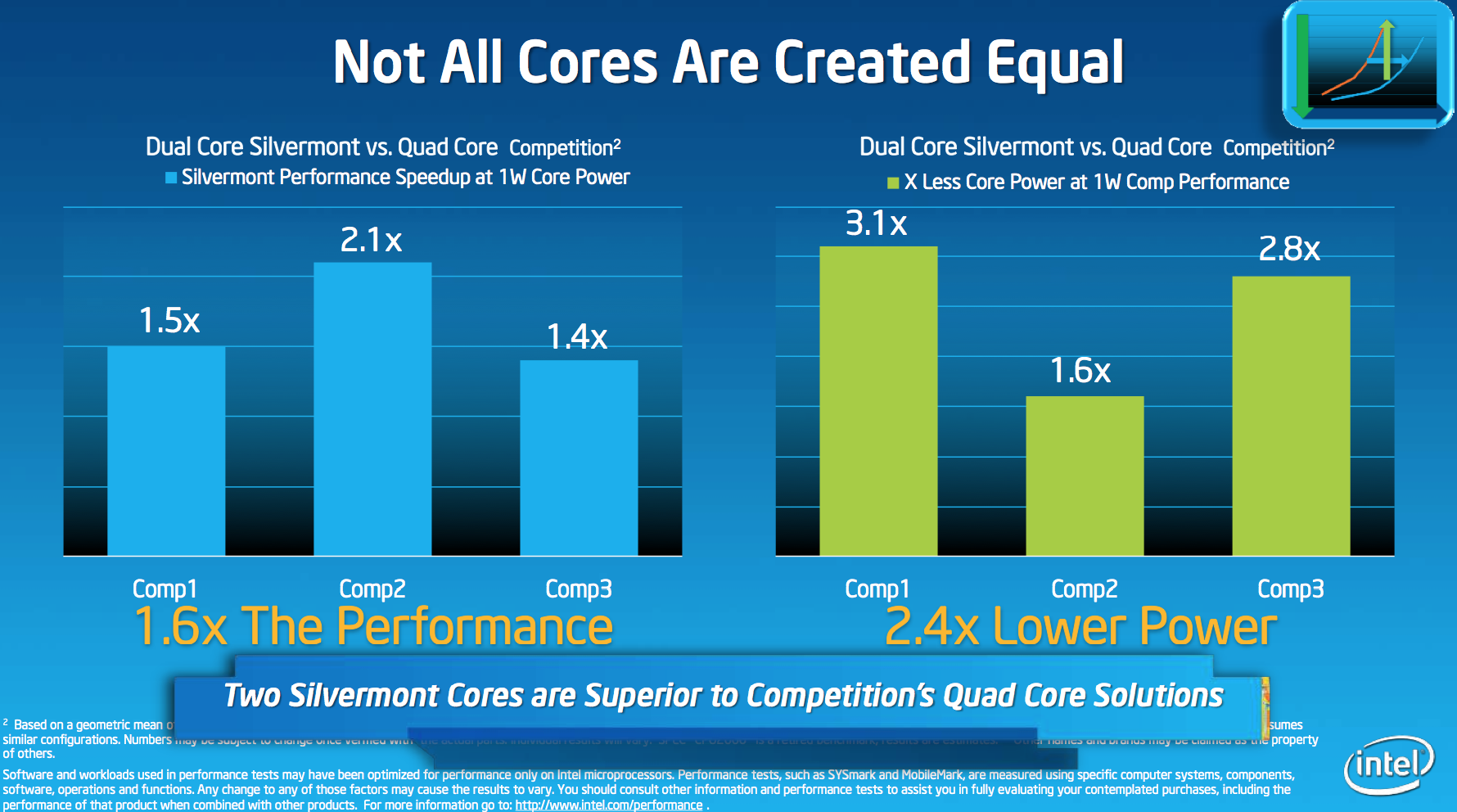
Intel isn’t naming the three competitors in this chart, but there are only a finite number of quad-core ARM players shipping in decent tablet designs these days. The chart on the left compares performance of a dual-core Silvermont to quad-core ARM based designs at a 1W core power level. This comparison is extremely important because it’s effectively demonstrating the type of advantage Intel hopes to have in smartphones next year.
The chart on the right fixes performance and shows the reduction in core power. Do keep in mind that there can be a big difference between core and device level power, although Intel does expect to be very competitive on battery life this round.
The final performance comparison slide increases max core power to 1.5W and compares quad-core Silvermont to the quad-core competition. You’ll note the arrival of a new competitor here. One of the bars is a dual-core SoC with its performance scaled to four cores. I’m less confident about that particular estimation simply because it assumes Apple won’t significantly update architectures in its next generation of iPads.
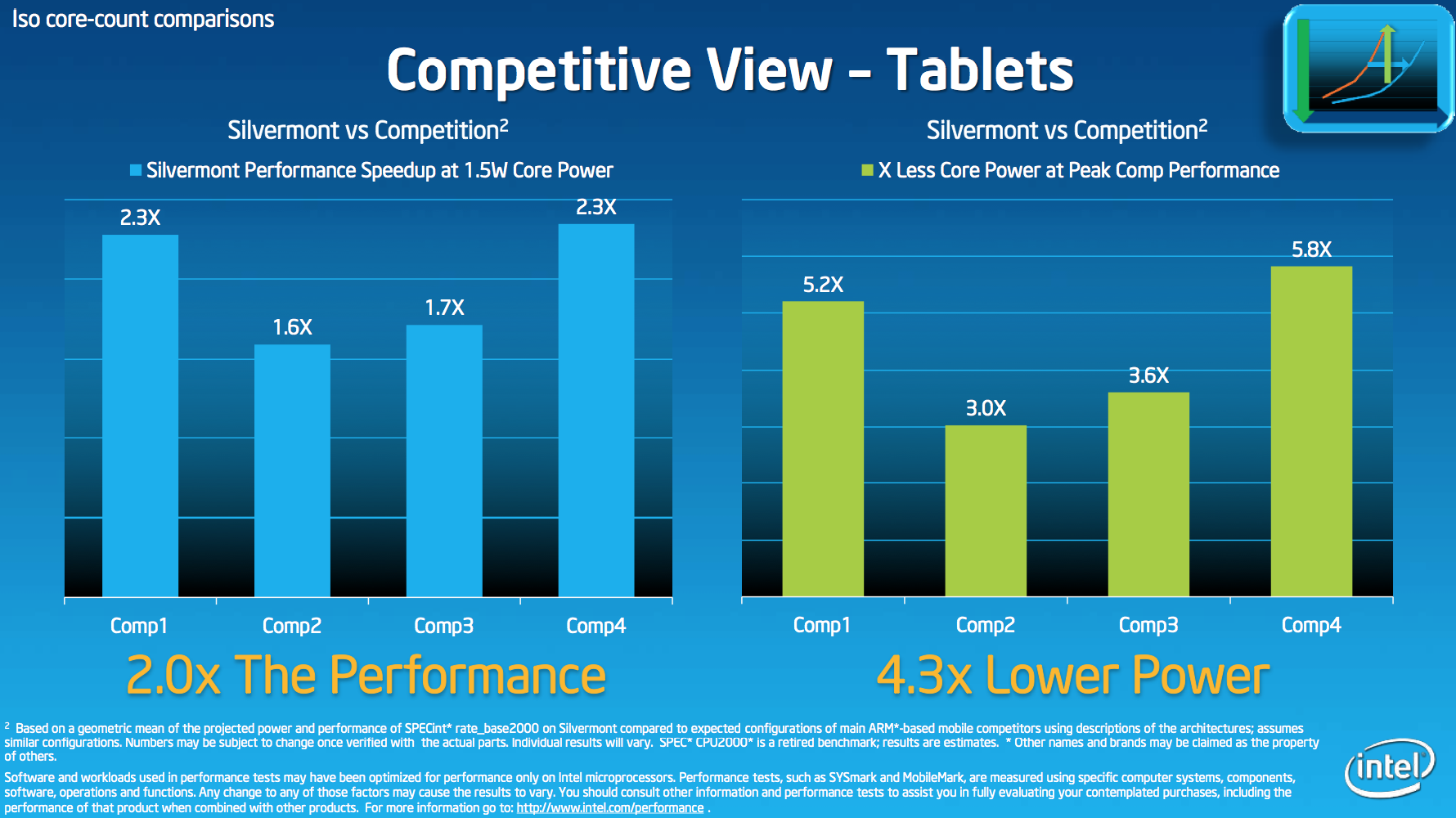
The performance deltas here are huge. If we assume that at least one of these bars represents a Cortex A15 based design, Silvermont looks very good.
That’s the end of the Intel data, but I have some thoughts to add. First of all, based on what I’ve seen and heard from third parties working on Baytrail designs - the performance claims of being 2x the speed of Clovertrail are valid. Compared to the two Cortex A15 designs I’ve tested (Exynos 5250, dual-core A15 @ 1.7GHz and Exynos 5410 quad-core A15 @ 1.6GHz), quad-core Silvermont also comes out way ahead. Intel’s claims of a 60% performance advantage, at minimum, compared to the quad-core competition seems spot on based on the numbers I’ve seen. Power is the only area that I can’t validate based on what I’ve seen already (no one has given me a Baytrail tablet to measure power on). Given what we know about Silvermont’s architecture and the gains offered by Intel’s 22nm process, I do expect this core to do better on power than what we’ve seen thus far from ARM’s Cortex A15.
There is something we aren’t taking into account though. As of now, the only Cortex A15 based SoCs that we’ve seen have been very leaky designs optimized for high frequency. Should an SoC vendor choose to optimize for power consumption instead, we could see a narrower gap between the power consumption of Cortex A15 and Silvermont. Obviously you give up performance when you do that, so it may not ultimately change anything - but the power story might be less of a blowout.








174 Comments
View All Comments
xTRICKYxx - Tuesday, May 7, 2013 - link
You're right. Intel has nothing to show at all.... Its not like they have the most powerful mobile and desktop consumer processors available.R0H1T - Tuesday, May 7, 2013 - link
Yeah, now sit & watch that market(x86) die a slow death at the hands of mobile/tablets that are powered by "good enough" ARM which doesn't need teraflop level of performance to sell their stuff unlike Intel !misaki - Monday, May 6, 2013 - link
Wow, clearly you are a new reader. This is an architecture overview, not a performance article, which means the information HAS to come from Intel. They have done these type of articles with every architecture redesign since the 90's.When chips are available to test that is when the real world performance articles will come out.
Ortanon - Monday, May 6, 2013 - link
SERIOUSLY.kyuu - Monday, May 6, 2013 - link
Yes, but a lot of performance claims are being made in the article, and Anand really seemed to just be taking Intel's marketing speak for gospel. That's how it read, at least.xTRICKYxx - Tuesday, May 7, 2013 - link
Not really. He clearly states to take the graphs cautiously. Also Intel may be slightly misleading, but nothing in the graphs are lies. They chose the best possible scenario for the greatest advantage.R0H1T - Tuesday, May 7, 2013 - link
Like how they(AT) claimed Intel's "SDP" was superior after stress testing an Exynos Octa, yup loved that fairytale !Kevin G - Monday, May 6, 2013 - link
The article mentions that the IDI is similar to internal bus found on the Nehalem and later desktop processor. IDI here is mentioned as a point-to-point interconnect where as everything is linked via a ring bus in recent Core processors. Of course you can loop multipe point-to-point interfaces into a loop but the article's wording allows for other topologies.For example, each Silvermont module could have its down dedicated point-to-point link to the system agent. In Nehalem, the system against logically appears as another hop in the internal ring bus.
Exophase - Monday, May 6, 2013 - link
Small correction:"Remember that with the first version of Atom, Intel enabled the fusion of load-op-store and load-op-execute instructions. Instead of these instruction combinations decoding into three and two micro-ops respectively, they would be fused post-fetch and treated like single operations throughout the entire pipeline."
Atom (the current one anyway) doesn't have instruction (macro-op) fusion. It does handle load + op and load + op + store are one issue down the pipeline but they still came from single instructions that are a natural part of the x86 ISA. While these may be considered fused micro-ops in Intel's other CPUs that terminology doesn't fit Atom.
These operations do need multiple instructions on most more RISCy ISAs like ARM. But the same is true the other way around (notably, 3 address arithmetic). I very much doubt you'll find typical x86 programs only need 2 instructions for every 3 ARM instructions on average, or at least any papers I've seen that measure micro-ops vs instructions on high-end CPUs are nowhere close to 1.5 (and a uop isn't generally more powerful than an ARM instruction, sometimes less when you consider two are needed for a store). But there are lots of other places that caused stalls on Atom that weren't related to decode, that it's easy to see how you could still gain a lot of perf/MHz without increasing it - as Bobcat and Jaguar have shown. All the details here do seem to point to a Bobcat-like design only with a much lower L2 cache latency and branch mispredict penalty which can only help more.
Anand Lal Shimpi - Monday, May 6, 2013 - link
Er you're very correct. Atom doesn't break these instructions down further, they're treated like single ops throughout the pipeline. I've updated the section. Thank you!