Gigabyte GA-7PESH1 Review: A Dual Processor Motherboard through a Scientist’s Eyes
by Ian Cutress on January 5, 2013 10:00 AM EST- Posted in
- Motherboards
- Gigabyte
- C602
For the purpose of this review, I delved into C++ AMP as a natural extension to my GPU programming experience. For users wanting to go down the GPU programming route, C++ AMP is a great way to get involved. As a high level language it is easy enough to learn, and the book on sale as well as the MSDN blogs online are also very helpful, moreso perhaps than CUDA.
Part of the available code online for C++ AMP revolves around n-body simulations, as the basis of an n-body simulation maps nicely to parallel processors such as multi-CPU platforms and GPUs. For this review, I was able to strip out the code from the n-body example provided and run some numbers. Many thanks to Boby George and Jonathan Emmett from Microsoft for their help.
The n-Body Simulation
When a series of heavy mass elements are in space, they interact with each other through the force of gravity. Thus when a star cluster forms, the interaction of every large mass with every other large mass defines the speed at which these elements approach each other. When dealing with millions and billions of stars on such a large scale, the movement of each of these stars can be simulated through the physical theorems that describe the interactions.
n-Body simulation is a large field of calculation with many different computational methods optimized for speed, memory usage or bus transfer – this is on top of the different algorithms that can be used to represent such a scenario. Typically one might expect the running time of a simulation be O(n^2) as each particle in the simulation has to interact gravitationally with every other particle, but some computational methods can be used to reduce this as the effect of gravity is inversely proportional to the square of the distance, and thus only the localized area needs to be known. Other complex solutions deal with general relativity. I am neither an expert in gravity simulations or relativity, but the solution used today is the full O(n^2) solution.
The code provided detects whether the processor is SSE2 or SSE4 capable, and implements the relative code. Here is an example of the multi-CPU code, using the PPL library, and the non-SSE enabled function:
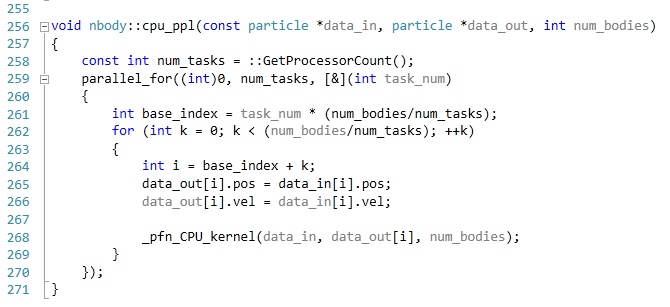

This code is run using a simulation of 10240 particles of equal mass. The output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.

In the case of our dual processor system, disabling HyperThreading gives a modest 6% boost, suggesting that the cache sizes of the processors used are slightly too small. Note that for this simulation, the data of every particle is stored in as low cache as possible, then read by each particle, and the main write is pushed out to main memory. Then for the next step, a copy of main memory is again made to the L3 cache of each processor and the process repeated. For this type of task, the dual processor systems are ideal, but like the Brownian motion simulation, moving them onto a GPU gets an even better result (700 GFLOPs on a GTX560).








64 Comments
View All Comments
JonnyDough - Tuesday, January 8, 2013 - link
I don't know if I speak for everyone, but I would really love to see some gaming benchmarks.I realize that this system is not designed or optimized for gaming, but it would be interesting nonetheless to see what two processors does, or does not do for gaming. :)
npcomplete - Tuesday, January 8, 2013 - link
...it just gets to the meat of computing!Thanks for this article. It woke up the scientist in me.
esung - Wednesday, January 9, 2013 - link
I'm very curious as the result. Have you tried to bench 1 2690 vs 2 2690s? It almost like the benchmark are limited by CPU frequency instead of threads/cores it has.CodeToad - Saturday, January 19, 2013 - link
Ian - I really enjoyed reading your effort here. There is a large, and I think underserved, community of scientific users who need this kind of information. Digging through IEEE/ASM communications is often just too much. Doing the work here - or anywhere - is a real help.I'm a retired economist (PhD Chicago, '81) and (in my case) thankfully haven't done physical, much less computational, chemistry since undergrad. Never the less, we have similar technical needs.
I've become a huge fan of open source software. In my "home lab," which my wife calls The Frat House, some grad students and I have been diligently working with the R Language (statistics), nascent risk and optimization tools, and a mash-up of database, data warehouse, and "business intelligence" tools, all open source. The goal someday -- beat SAS silly and obviate that $100-300K price tag!
The more demure and do-able daily work is just cleaning up and optimizing open source code, contributing that back as individual packages. The "hits" and email indicates a good adoption rate.
Ian, CUDA is of big interest to the people we're in communication with, and I have to admit some real fascination personally. As you have real-world experience, how about a series of articles. I hope ANDATECH would support that work!!
Very best to you - hope to be "reading" you soon!!