Gigabyte GA-7PESH1 Review: A Dual Processor Motherboard through a Scientist’s Eyes
by Ian Cutress on January 5, 2013 10:00 AM EST- Posted in
- Motherboards
- Gigabyte
- C602
For the purpose of this review, I delved into C++ AMP as a natural extension to my GPU programming experience. For users wanting to go down the GPU programming route, C++ AMP is a great way to get involved. As a high level language it is easy enough to learn, and the book on sale as well as the MSDN blogs online are also very helpful, moreso perhaps than CUDA.
Part of the available code online for C++ AMP revolves around n-body simulations, as the basis of an n-body simulation maps nicely to parallel processors such as multi-CPU platforms and GPUs. For this review, I was able to strip out the code from the n-body example provided and run some numbers. Many thanks to Boby George and Jonathan Emmett from Microsoft for their help.
The n-Body Simulation
When a series of heavy mass elements are in space, they interact with each other through the force of gravity. Thus when a star cluster forms, the interaction of every large mass with every other large mass defines the speed at which these elements approach each other. When dealing with millions and billions of stars on such a large scale, the movement of each of these stars can be simulated through the physical theorems that describe the interactions.
n-Body simulation is a large field of calculation with many different computational methods optimized for speed, memory usage or bus transfer – this is on top of the different algorithms that can be used to represent such a scenario. Typically one might expect the running time of a simulation be O(n^2) as each particle in the simulation has to interact gravitationally with every other particle, but some computational methods can be used to reduce this as the effect of gravity is inversely proportional to the square of the distance, and thus only the localized area needs to be known. Other complex solutions deal with general relativity. I am neither an expert in gravity simulations or relativity, but the solution used today is the full O(n^2) solution.
The code provided detects whether the processor is SSE2 or SSE4 capable, and implements the relative code. Here is an example of the multi-CPU code, using the PPL library, and the non-SSE enabled function:
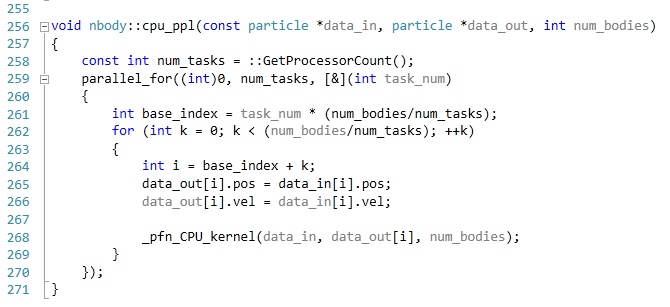

This code is run using a simulation of 10240 particles of equal mass. The output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.

In the case of our dual processor system, disabling HyperThreading gives a modest 6% boost, suggesting that the cache sizes of the processors used are slightly too small. Note that for this simulation, the data of every particle is stored in as low cache as possible, then read by each particle, and the main write is pushed out to main memory. Then for the next step, a copy of main memory is again made to the L3 cache of each processor and the process repeated. For this type of task, the dual processor systems are ideal, but like the Brownian motion simulation, moving them onto a GPU gets an even better result (700 GFLOPs on a GTX560).








64 Comments
View All Comments
nevertell - Sunday, January 6, 2013 - link
The K version may not, but the standard i7-3770 does in fact support VT-D, TXT and ECC memory from the get go. Vt-D has to be also supported by the motherboard, which may be problematic on consumer motherboards. I have a i5-2400 myself, and Vt-d is a pain to setup and to this day I still haven't found out whether is it that I am unable to set up Xen properly or just that my cheap motherboard worn't support VT-d, to properly assign a video card to a virtual machine.KAlmquist - Sunday, January 6, 2013 - link
The 3770K lacks those features, but that doesn't invalidate my point.Using ECC memory improves system availability, and likely decreases the probability of undetected errors resulting in incorrect computations. If these are important to you, then you should be thinking about full double or triple redundancy. Why not buy three 3770K based systems and run the same simulation on all of them? Most of the time you will get identical results on all three systems, but on rare occasions one of the systems will die during the run. No problem; you have the simulation results from the other two systems. On even rarer occasions, one of the systems will produced an incorrect result due to an undetected bit error. Again no problem; you take the results from the two simulations that agree.
With full redundancy it doesn't matter where in the system the error occurs because full redundancy addresses faults anywhere in the system. This makes it superior to ECC memory, which only addresses faults in the memory subsystem. So the only reason to go with ECC memory instead of full triple redundancy is if the ECC memory approach costs less. Based on the numbers I posted, you aren't going to get a lower cost based on hardware costs alone. Possibly you could get there by including administrative costs and the like.
I'm not saying that the system Ian tested wouldn't make sense under *any* circumstances. My point is that the system has a poor price performance ratio, so it only makes sense when a lot of things are working in its favor.
The second feature you mention is VT-D, which makes it more efficient to emulate device hardware in virtual machines. I don't have any benchmarks, but my guess is that the performance improvement from VT-D is fairly small. In any case, if you want VT-D you can buy the 3770 rather than the 3770K. You can't overclock the 3770, but my comments about the 3770K offering "similar performance" were based primarily on the performance of the 3770K at stock frequency. If you assume that everyone is going to take the time to find an optimal overclock for their CPU, then the E5-2690 (which cannot be overclocked) looks even worse.
I suppose it's off topic to debate the merits of "trusted execution technology" here, so I will simply note that if for whatever reason you want a processor that supports it, the solution is the same as for VT-D: get the 3770 instead of the 3770K.
Kevin G - Saturday, January 5, 2013 - link
A very well written article that sticks toward its purpose: scientific computing. Really pleased to see articles like this on the site even if I have a few minor quibbles.On page 2 "To those unfamiliar with server boards, of note is the connector just to the right of center of the picture above." is either oddly worded to describe the front panel connector at the bottom the board (which is indeed right of center but not in the center of the picture) or describing a connector that isn't even documented in the manual. For clarification I'm looking at the connector just right of the top PCI-E 16x slot (above and to the left of the battery). Actually, what is that connector labeled as? I've seen it on other Xeon boards but have never seen it used.
The last paragraph on page 2 should read omits the possibility of nonbuffered ECC memory and implies the usage of unbuffered non-ECC memory. I haven't found confirmation that this board can accept unbuffered, non-ECC memory (opposed to the possibility of an ECC requirement as some server vendors enforce).
A couple of notes on the little processor talk on page 6. Dealing with cache thrashing between L3 and L2 is possible but when dealing with a high number of threads general coherency becomes a bigger factor. The overhead is beginning to exceed the benefit of having the additional hardware to run them. If you're lucky to be dealing with an algorithm that doesn't need such coherency overhead, then chances are it is very ideal for GPU compute (and memory capacity isn't a factor). A minor nicety would have been to see some more testing without Hyperthreading on the i7-3770k, i7-3930k, and i7-3960X to better indicate scaling with/without Hyperthreading. I suspect that those single socket processors would have been able to show some small gains with Hyperthreading where the dual socket system did not.
An extension to the L2/L3 cache talk on page 6 is the move to dual sockets and NUMA. There is a performance penalty due to latency for having one thread access memory that is found on a remote socket. Memory mirroring between sockets can eliminate that remote penalty while increasing RAS but at the cost of halving effective memory capacity. The manual isn't clear if mirroring mode or the lockstep mode is across different sockets (it can be done across memory channels as well).
I'd also would have loved to have heard some comparisons with the Gigabyte GA-X79S-UP5. While the name implies an X79 chipset, it uses the C606 chipset. It'll support ECC memory with socket 2011 Xeons and plenty of over clocking features (for the daring). Comparing the GA-7PESH1 to the GA-X79S-UP5 would have been able to answer if the move to dual sockets would have been worth the extra cost.
Hakon - Saturday, January 5, 2013 - link
Somehow does read like an anonymous peer review :-)Kevin G - Sunday, January 6, 2013 - link
A little bit. :)Part of my criticism isn't about the article itself but rather the general state of massively multithreaded hardware and software. The hardware portion is quickly running into software limitation that were never expected to be reached in the professional space. A decade ago who thought that a scientist could purchase a 240 simultaneous thread processor that would fit on a mere expansion card? In some cases we don't reach Amdal's Law before hitting an artificial barrier due to scheduling or coherency overhead.
I just noticed that the system was using Win 7 Professional which has a limit of 64 concurrent threads per process. A quad socket LGA 2011 config would actually be at the very limit of what Window 7 (or rather 2008R2 since professional only scales to two sockets) can handle. OpenMP can handle more than 64 concurrent threads but on Windows it has to submit this limitation.
psyq321 - Sunday, January 6, 2013 - link
As for the GA-X79S-UP5 Clocking features are only working for 1P Xeons, which are basically similar to HEDT i7 (36xx) line. With those, customer has an advantage of ECC RAM support and still some overclocking headroom.Clocking 2P/4P Xeons E5 (sadly, these are the only 8-core parts so far) is next to impossible due to the lack of ICC configuration data allowing changing BCLK ratios. These Xeons can only be bumped by direct BCLK increase, which is dangerous above few MHz. At most, 5-6 MHz is feasible as tested on ASUS Z9PE-D8-WS and EVGA SR-X boards.
Memory overclocking is another matter, completely. I have excellent results with Samsung's 1.35v ("low voltage") ECC RAM. It is not just the cheapest 16 GB ECC option (~$160 for the 16 GB ECC stick last time I checked, I got mine for 140 EUR in Germany 7 months ago), but it is the fastest while still keeping the low voltage. This RAM can be overclocked to 2133 MHz by a simple voltage bump to 1.55v, which is still within Xeon's VSa limits.
Kevin G - Sunday, January 6, 2013 - link
Weird that Intel doesn't provide the ICC configuration data. The 'gear ratio' change is something I'd still expect to change on true X79 boards regardless of processors (I can see Intel crippling this on C600 series). Then again, I've heard some weird situations with LGA 2011 Xeons in desktop boards. There are some scattered reports of unlocked chips but as the internet goes there are lots of speculation and rumors but little real confirmation.Those Samsung 16 GB ECC sticks are registered? I thought that the GA-X79S-UP5 didn't registered DIMMs.
As for the ability to overclock those low voltage DIMMs, not really surprised as they've historically been impressive in that regards. I have some older 4 GB 1.35v DDR3-1333 rated sticks that can go to 1866 Mhz at 1.5v. :) The timings had to be changed but still impressive.
PEPCK - Saturday, January 5, 2013 - link
Worth noting that the three miniSAS connectors yield 8 SAS and 4 SATA connectors in the specification table.krumme - Sunday, January 6, 2013 - link
For this article Ian get the über nerds Gold Award only given ones in a centurylowenz - Sunday, January 6, 2013 - link
A brilliant article.More of these, please.