Gigabyte GA-7PESH1 Review: A Dual Processor Motherboard through a Scientist’s Eyes
by Ian Cutress on January 5, 2013 10:00 AM EST- Posted in
- Motherboards
- Gigabyte
- C602
For the purpose of this review, I delved into C++ AMP as a natural extension to my GPU programming experience. For users wanting to go down the GPU programming route, C++ AMP is a great way to get involved. As a high level language it is easy enough to learn, and the book on sale as well as the MSDN blogs online are also very helpful, moreso perhaps than CUDA.
Part of the available code online for C++ AMP revolves around n-body simulations, as the basis of an n-body simulation maps nicely to parallel processors such as multi-CPU platforms and GPUs. For this review, I was able to strip out the code from the n-body example provided and run some numbers. Many thanks to Boby George and Jonathan Emmett from Microsoft for their help.
The n-Body Simulation
When a series of heavy mass elements are in space, they interact with each other through the force of gravity. Thus when a star cluster forms, the interaction of every large mass with every other large mass defines the speed at which these elements approach each other. When dealing with millions and billions of stars on such a large scale, the movement of each of these stars can be simulated through the physical theorems that describe the interactions.
n-Body simulation is a large field of calculation with many different computational methods optimized for speed, memory usage or bus transfer – this is on top of the different algorithms that can be used to represent such a scenario. Typically one might expect the running time of a simulation be O(n^2) as each particle in the simulation has to interact gravitationally with every other particle, but some computational methods can be used to reduce this as the effect of gravity is inversely proportional to the square of the distance, and thus only the localized area needs to be known. Other complex solutions deal with general relativity. I am neither an expert in gravity simulations or relativity, but the solution used today is the full O(n^2) solution.
The code provided detects whether the processor is SSE2 or SSE4 capable, and implements the relative code. Here is an example of the multi-CPU code, using the PPL library, and the non-SSE enabled function:
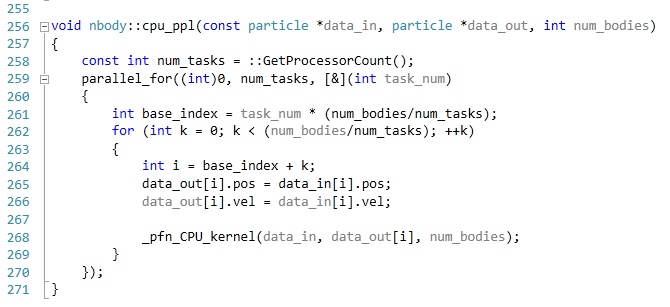

This code is run using a simulation of 10240 particles of equal mass. The output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.

In the case of our dual processor system, disabling HyperThreading gives a modest 6% boost, suggesting that the cache sizes of the processors used are slightly too small. Note that for this simulation, the data of every particle is stored in as low cache as possible, then read by each particle, and the main write is pushed out to main memory. Then for the next step, a copy of main memory is again made to the L3 cache of each processor and the process repeated. For this type of task, the dual processor systems are ideal, but like the Brownian motion simulation, moving them onto a GPU gets an even better result (700 GFLOPs on a GTX560).








64 Comments
View All Comments
mayankleoboy1 - Saturday, January 5, 2013 - link
Ian :How much difference do you think Xeon Phi will make in these very different type of Computations?
Will buying a Xeon Phi "pay itself out" as you said in the above comments ? (or is xeon phi linux only ?)
IanCutress - Saturday, January 5, 2013 - link
As far as we know, Xeon Phi will be released for Linux only to begin with. I have friends who have been able to play with them so far, and getting 700 GFlops+ in DGEMM in double precision.It always comes down to the algorithm with these codes. It seems that if you have single precision code that doesn't mind being in a 2P system, then the GPU route may be preferable. If not, then Phi is an option. I'm hoping to get my hands on one inside H1 this year. I just have to get my hands dirty with Linux as well.
In terms of the codes used here, if I were to guess, the Implicit Finite Difference would probably benefit a lot from Xeon Phi if it works the way I hope it does.
Ian
mayankleoboy1 - Saturday, January 5, 2013 - link
Rather stupid question, but have you tried using PGO builds ?Also, do you build the code with the default optimizations, or use the MSVC equivalent switch of -O2 ?
IanCutress - Saturday, January 5, 2013 - link
Using Visual Studio 2012, all the speed optimisations were enabled including /GL, /O2, /Ot and /fp:fast. For each part I analysed the sections which took the most time using the Performance Analysis tools, and tried to avoid the long memory reads. Hence the Ex-FD uses an iterative loading which actually boosts speed by a good 20-30% than without it.Ian
Klimax - Sunday, January 6, 2013 - link
Interesting. Why not Ox (all optimisations on)BTW: Do you have access to VTune?
IanCutress - Wednesday, January 9, 2013 - link
In case /Ox performs an optimisation for memory over speed in an attempt to balance optimisations. As speed is priority #1, it made more sense to me to optimise for that only. If VS2012 gave more options, I'd adjust accordingly.Never heard of VTune, but I did use the Performance Analysis tools in VS2012 to optimise certain parts of the code.
Ian
Beenthere - Saturday, January 5, 2013 - link
Business and mobo makers do not use 2P mobos to get high benches or performance bragging rights per se. These systems are build for bullet-proof reliability and up time. It does no good for a mobo/system to be 3% faster if it crashes while running a month long analysis. These 2P mobos are about 100% reliability, something rarely found in a enthusiasts mobo.Enterprise mobos are rarely sold by enthusiast marketeers. Newegg has a few enterprise mobos listed primarily because they have started a Newegg Biz website to expand their revenue streams. They don't have much in the line of true enterprise hardware however. It's a token offering because manufacturers are not likely to support whoring of the enterprise market lest they lose all of their quality vendors who provide customer technical product support.
psyq321 - Sunday, January 6, 2013 - link
Actually, ASUS Z9PE-D8 WS allows for some overclocking capabilities.CPU overclocking with 2P/4P Xeon E5 (2600/4600 sequence) is a no-go because Intel explicitly did not store proper ICC data so it is impossible to manipulate BCLK meaningfully (set the different ratios). Oh, and the multipliers are locked :)
However, Z9PE D8 WS allows memory overclocking - I managed to run 100% 24/7 stable with the Samsung ECC 1600 DDR3 "low voltage" RAM (16 GB sticks) - just switching memory voltage from 1.35v to 1.55v allows overclocking memory from 1600 MHz to 2133 MHz.
Why would anyone want to do that in a scientific or b2b environment? The only usage I can see are applications where memory I/O is the biggest bottleneck. Large-scale neural simulations are one of such applications, and getting 10 GB/s more of memory I/O can help a lot - especially if stable.
Also, low-latency trading applications are known to benefit from overclocked hardware and it is, in fact, used in production environment.
Modern hardware does tend to have larger headrooms between the manufacturer's operating point and the limits - if the benefit from an overclock is more benefitial than work invested to find the point where the results become unstable - and, of course, shorter life span of the hardware - then, it can be used. And it is used, for example in some trading scenarios.
Drazick - Saturday, January 5, 2013 - link
Will You, Please, Update Your Google+ Page?It would be much easier to follow you there.
Ryan Smith - Saturday, January 5, 2013 - link
Our Google+ page is just a token page. If you wish to follow us then your best option is to follow our RSS feeds.