Making Sense of the Intel Haswell Transactional Synchronization eXtensions
by Johan De Gelas on September 20, 2012 12:15 AM ESTHaswell's TSX
The new Transactional Synchronization eXtensions (TSX) extend the x86 ISA with two new interfaces: HLE and RTM.
Restricted Transactional Memory (RTM) uses Xbegin and Xend, allowing developers to mark the start and end of a critical section. The CPU will thread this piece of code as an atomic transaction. Xbegin also specifies a fall back path in case the transaction fails. Either everything goes well and the code runs without any lock, or the shared variable(s) that the thread is working on is overwritten. In that case, the code is aborted and the transaction has failed. The CPU will now execute the fall back path, which is most likely a piece of code that does coarse grained locking. RTM enabled software will only run on Haswell and is thus not backwards compatible, so it might take a while before this form of Hardware Transactional Memory is adopted.
The most interesting interface in the short term is Hardware Lock Elision or HLE. It first appeared in a paper by Ravi Rajwar and James Goodman in 2001. Ravi is now a CPU architect at Intel and presented TSX together with his colleague Martin Dixon TSX at IDF2012.
The idea is to remove the locks and let the CPU worry about consistency. Instead of assuming that a thread should always protect the shared data from other threads, you optimistically assume that the other threads will not overwrite the variables that the thread is working on (in the critical section). If another thread overwrites one of those shared variables anyway, the whole process will be aborted by the CPU, and the transaction will be re-executed but with a traditional lock.
If the lock removing or elision is successful, all threads can work in parallel. If not, you fall back to traditional locking. So the developer can use coarse grained locking (for example locking the entire shared structure) as a "fall back" solution, while Lock Elision can give the performance that software with a well tuned fine grained locking library would get.
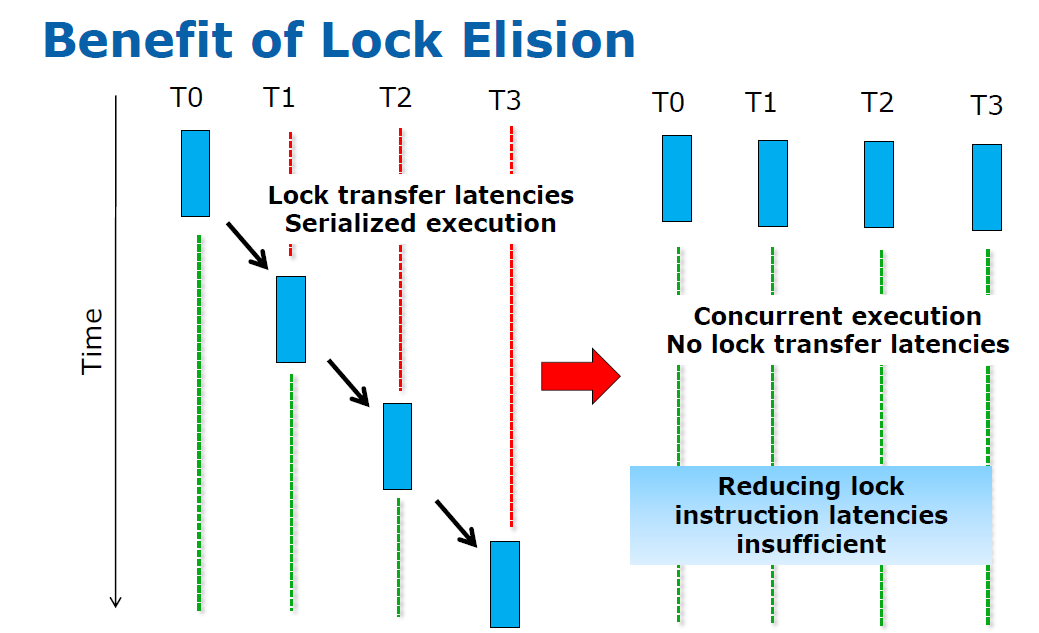
According to Ravi and Martin, the beauty is that the developer of your locking libraries simply has to add a few HLE instructions without breaking backwards compatibility. The developer uses the new TSX enabled library and gets the benefits of TSX if his application is run on Haswell or a later Intel CPU.








29 Comments
View All Comments
dealcorn - Thursday, September 20, 2012 - link
The graphs indicate the benefit of HLE versus no HLE gets bigger as the number of threads increase. However, they lack scaling on the horizonal axis: I have no sense of the benefit at real world numbers like 8 threads, 12 threads and 16 threads.Is the primary benefit of RTM greater CPU performance or programmer productivity?
GatoRat - Thursday, September 20, 2012 - link
With the right application, you get both. With the wrong application, you get an apparent increase in productivity at the cost of performance. In the end, you still need smart, experienced and expensive engineers to know when to use this technology and when not to.GatoRat - Thursday, September 20, 2012 - link
It fails to properly explain what STM is. Unfortunately, most of the descriptions I've read make the same fundamental mistake made in this article--you don't lock a data structure or variables, you lock code. This difference is important because it means you can control it very exactly. These same articles then basically argue that STM is beneficial to lazy programmers who use locks too broadly. Yet programmers who do that aren't going to use STM, which is far more complicated and for which the benefits are dubious outside of some very narrow applications.My own experience is that non-locking algorithms are highly problematic and rarely give a performance advantage over using carefully designed locking algorithms. Moreover, in several situations a crudely designed locking algorithm can perform extremely fast due to the decreased complexity of the overall algorithm.
Bottom line is that what Intel has been doing, even with Nehelem, is fantastic, but thinking this will obviate the need for spending a lot of time and effort and brain power is delusional. On the other hand, it will help in the myriad of situations where management contradicts reality and says "it's good enough."
GatoRat - Thursday, September 20, 2012 - link
Incidentally, STM imposes a very real overhead which can easily cause worse performance than the alternative. Between the overhead and the increased complexity in code, in lightly loaded systems, the performance will always be worse.The hype is similar to that of parallel programming and will have just as dismal results. Like with parallel programming, you need a certain mindset and a problem which is conducive to being solved in that matter. I recently worked on a problem which simply had too many threads and asynchronous events due to the underlying (and well known) framework. STM would have been a disaster. I designed a pseudo-parallel architecture, but was never able to implement and test it due to the project being put on hiatus (by new management that was utterly clueless.)
clarkn0va - Thursday, September 20, 2012 - link
You know these new extensions will succeed and rapidly gain market share because the marketers managed to use a capital X in the name.glugglug - Thursday, September 20, 2012 - link
Other than real lock-contention, where HLE will net a small improvement even over fine-grained locks, the situations where it won't work (i.e. running out of L1 cache lines) come into play just as much with only 1 thread running, and the code that gets hit by these will lose its single-threaded performance. Worst case would be single threaded performance hit near 50%, but I think that would be extremely rare. Still, the amount of multithreaded gain is deceptive when you are hindering the single threaded performance.Also, in order to avoid that single threaded hit you end up going back to fine grained locks -- the coarse locks are more likely to hit the restrictions and have to re-run.
JonBendtsen - Friday, September 21, 2012 - link
Where are the scaling on the graphs? without scales the graph is useless.wwwcd - Friday, September 21, 2012 - link
Conclusion: The Need for doubling or quadrupling the amount of cache on the first floor rather than continuing torture tricks with software to optimize the use of already too little used since time immemorial volume. Of course, accompanied by the necessary improvement of the design of the CPU cores and adjusting volume levels of other caches.It is also necessary to increase the throughput of caches, or by widening the bus or increase their frequency of use, or by both methods
mallik79 - Monday, September 24, 2012 - link
I work for improving performance on a large commercial database.Challenge seems to be multi-CPU than multi-core.
Bottlenecks get magnified by adding cpu's instead of cores.
(we have custom spinlock code, donot use system provided primitives).
How many ever cores you add to a CPU, people still want multi-CPU huge boxes to run their databases.
So does this transaction memory caching makes life tougher for multi-CPU as the lock is nearer to a particular CPU, it makes cores of other CPU starve?
Thanks for all the in-depth reviews.