AMD's Radeon HD 6970 & Radeon HD 6950: Paving The Future For AMD
by Ryan Smith on December 15, 2010 12:01 AM ESTCayman: The New Dawn of AMD GPU Computing
We’ve already covered how the shift from VLIW5 to VLIW4 is beneficial for AMD’s computing efforts: narrower SPUs are easier to fully utilize, FP64 performance improves to 1/4th FP32 performance, and the space savings give AMD room to lay down additional SIMDs to improve performance. But if Cayman is meant to be a serious effort by AMD to relaunch themselves in to the GPU computing market and to grab a piece of NVIDIA’s pie, it takes more than just new shaders to accomplish the task. Accordingly, AMD has been hard at work to round out the capabilities of their latest GPU to make it a threat for NVIDIA’s Fermi architecture.
AMD’s headline compute feature is called asynchronous dispatch, a long word that actually does a pretty good job of describing what it does. To touch back on Fermi for a moment, with Fermi NVIDIA introduced support for parallel kernels, giving Fermi the ability to execute multiple kernels at once. AMD in turn is following NVIDIA’s approach of executing multiple kernels at once, but is going to take it one step further.
The limit of NVIDIA’s design is that while Fermi can execute multiple kernels at once, each one must come from the same CPU thread. Independent threads/applications for example cannot issue their own kernels and have them execute in parallel, rather the GPU must context switch between them. With asynchronous dispatch AMD is going to allow independent threads/applications to issue kernels that execute in parallel. On paper at least, this would give AMD’s hardware a significant advantage in this scenario (context switching is expensive), one that would likely eclipse any overall performance advantages NVIDIA had.
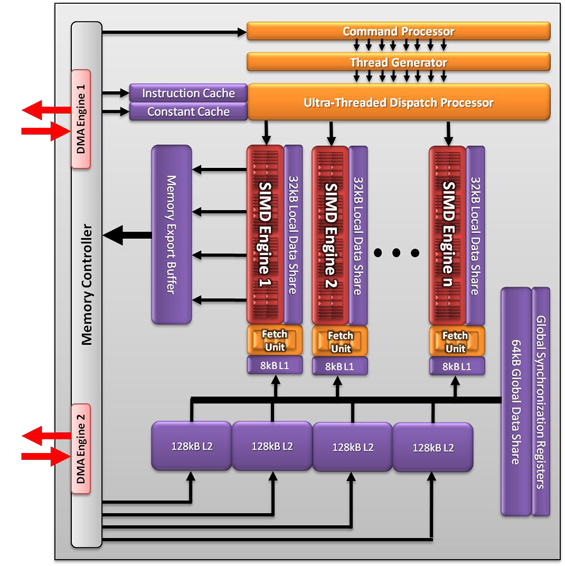
Fundamentally asynchronous dispatch is achieved by having the GPU hide some information about its real state from applications and kernels, in essence leading to virtualization of GPU resources. As far as each kernel is concerned it’s running in its own GPU, with its own command queue and own virtual address space. This places more work on the GPU and drivers to manage this shared execution, but the payoff is that it’s better than context switching.
For the time being the catch for asynchronous dispatch is that it requires API support. As DirectCompute is a fixed standard this just isn’t happening – at least not with DirectCompute 11. Asynchronous dispatch will be exposed under OpenCL in the form of an extension.
Meanwhile the rest of AMD’s improvements are focusing on memory and cache performance. While the fundamental architecture is not changing, there are several minor changes here to improve compute performance. The Local Data Store attached to each SIMD is now able to bypass the cache hierarchy and Global Data Store by having memory fetches read directly in to the LDS. Meanwhile Cayman is getting a 2nd DMA engine, improving memory reads & writes by allowing Cayman to execute two at once in each direction.
Finally, read ops from shaders are being sped up a bit. Compared to Cypress, Cayman can coalesce them in to fewer operations.
As today’s launch is primarily about the Radeon HD 6900 series AMD isn’t going too much in depth on the compute side of things, so everything here is a fairly high level overview of the architecture. Once AMD has Firestream cards ready to go with Cayman in them, there will likely be more to talk about.








168 Comments
View All Comments
cyrusfox - Wednesday, December 15, 2010 - link
You should totally be able to do a 4X1 display, 2 DP and 2 DVI, as long as one of those DP dells also has a DVI input. That would get rid of the need for your usb-vga adapter.gimmeagdlaugh - Wednesday, December 15, 2010 - link
Not sure why AMD 6970 has green bar,while NV 580 has red bar...?
medi01 - Wednesday, December 15, 2010 - link
Also wondering. Did nVidia marketing guys called again?Ryan Smith - Wednesday, December 15, 2010 - link
I normally use green for new products. That's all there is to it.JimmiG - Wednesday, December 15, 2010 - link
Still don't like the idea of Powertune. Games with a high power load are the ones that fully utilize many parts of the GPU at the same time, while less power hungry games only utilize parts of it. So technically, the specifications are *wrong* as printed in the table on page one.The 6970 does *not* have 1536 stream processors at 880 MHz. Sure, it may have 1536 stream processors, and it may run at up to 880 MHz.. But not at the same time!
So if you fully utilize all 1536 processors, maybe it's a 700 MHz GPU.. or to put it another way, if you want the GPU to run at 880 MHz, you may only utilize, say 1200 stream processors.
cyrusfox - Wednesday, December 15, 2010 - link
I think Anand did a pretty good job of explaining at how it reasonably power throttles the card. Also as 3rd party board vendors will probably make work-arounds for people who abhor getting anything but the best performance(even at the cost of efficiency). I really don't think this is much of an issue, but a good development that is probably being driven by Fusion for Ontario, Zacate, and llano. Also only Metro 2033 triggered any reduction(850Mhz from 880Mhz). So your statement of a crippled GPU only holds for Furmark, nothing got handicapped to 700Mhz. Games are trying to efficiently use all the GPU has to offer, so I don't believe we will see many games at all trigger the use of powertune throttling.JimmiG - Wednesday, December 15, 2010 - link
Perhaps, but there's no telling what kind of load future DX11 games, combined with faster CPUs will put on the GPU. Programs like Furmark don't do anything unusual, they don't increase GPU clocks or voltages or anything like that - they just tell the GPU - "Draw this on the screen as fast as you can".It's the same dilemma overclockers face - Do I keep this higher overclock that causes the system to crash with stress tests but works fine with games and benchmarks? Or do I back down a few steps to guarantee 100% stability. IMO, no overclock is valid unless the system can last through the most rigorous stress tests without crashes, errors or thermal protection kicking in.
Also, having a card that throttles with games available today tells me that it's running way to close to the thermal limit. Overclocking in this case would have to be defined as simply disabling the protection to make the GPU always work at the advertised speed.
It's a lazy solution, what they should have done is go back to the drawing board until the GPU hits the desired performance target while staying within the thermal envelope. Prescott showed that you can't just keep adding stuff without any considerations for thermals or power usage.
AnnihilatorX - Wednesday, December 15, 2010 - link
Didn't you see you can increase the throttle threshold by 20% in Catalyst Control Centre. This means 300W until it throttles, which in a sense disables the PowerTune.Mr Perfect - Thursday, December 16, 2010 - link
On page eight Ryan mentions that Metro 2033 DID get throttled to 700MHz. The 850MHz number was reached by averaging the amount of time Metro was at 880MHz with the time it ran at 700MHz.Which is a prime example of why I hate averages in reviews. If you have a significantly better "best case", you can get away with a particularly bad "worst case" and end up smelling like roses.
fausto412 - Wednesday, December 15, 2010 - link
CPU's have been doing this for a while...and you are allowed to turn the feature off. AMD is giving you a range to go over.It will cut down on RMA's, Extend Reliability.