Hybrid Clouds: are we there yet?
by Johan De Gelas on October 18, 2010 2:05 PM EST- Posted in
- IT Computing
Hybrid "Storage" Cloud
A good network connection between two datacenters is the first step. But things really get interesting when you can move your data quickly and easily to another place. Moving a VM (vMotion, Xenmotion, live migration) towards a new location is nice, but you are just moving the processing and memory part.
Moving a VM to a location that is hundreds of kms/miles away behind a firewall and letting it access storage over a long distance is a bad idea.
The traditional way to solve this would be a fail-over mirroring setup. One node is the "original" active node. This is the one that is written to: the application will send writes to handle an OLTP transaction for example. The other node is the passive node and is synced with the "original" one on a block level. It does not handle any transactions. You could perform a "fake" storage migration by shutting down the active node and letting the passive node take over. Nice, but you do not get any performance scalability. In fact, the "original" storage node is slowed down as it has to sync with the passive one all the time. And you can not really "move around" the workload: you must first invest a lot of time and effort to get the mirror up and running.
Another solution is simply merge two SANs to one. You place one SAN in a datacenter, and the other one in another datacenter. Since high-end optical fibre channel cables are able to bridge about 10 kms, you can build a "stretched SAN". That is fine for connecting your own datacenters locally, but it is nowhere near our holy grail of an "hybrid cloud".
Storage vMotion and vMotion are relatively affordable solutions to create a hybrid cloud at first sight. But at second thought, you'll understand that moving a VM between your private cloud and public cloud without down time will turn out to be pretty challenging. From the vSphere Admin guide:
"VMotion requires a Gigabit Ethernet (GigE) network between all VMotion-enabled hosts."
A dedicated gigabit WAN link is not something that most people have access to. And expanding the VLAN accross datacenters can be pretty hard too. It will work, but it is not supported by VMware (as far as we know) and will cause a performance hit. We have not measured this yet... but we will.
VM Teleportation
A little rant: I have learned to stay from presentations of quite a few vice presidents. Some of these VPs seem to be so out of touch with technical reality that I could not help wondering if they ever set foot in the tech company they are working for. What supposed to be a techy presentation turns out in an endless repitition of "we need to adapt to the evolving needs of our customers" and "those needs are changing fast". And then endless slides with smiling suits and skyscrapers.
Chad Sakac, the EMC VMware Technology Alliance VP, restored my faith in VPs: a very enthusiatic person which obviously spends a lot - probably too much - of time with his engineers in the EMC and VMware labs. Technical deep dives are just a natural way to express himself. If you don't believe me, just ask anyone attending the sessions at VMworld or EMCworld or watch this or this.
Chad talked about EMC's "VM teleportation" device, the EMC vPlex. At the physical level, the vPlex is a dual fully redundant Intel Nehalem (2.4 GHz) based server with 4 redundant I/O modules.
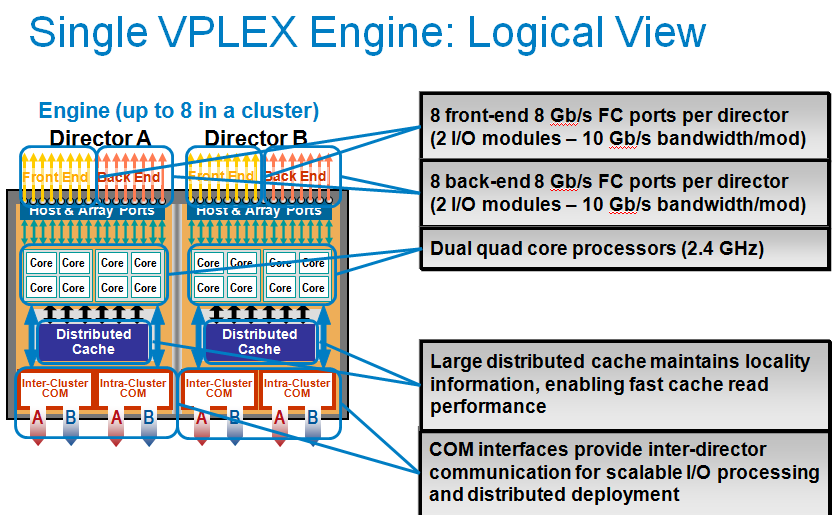
Click to enlarge
Each "Director" or Nehalem Server has 16 - 64 GB of RAM. Four GB is used for the software of the VPLEX engine, the rest is used for caching.
The VPLEX boxes are expensive ($77000) but the VPLEX engine does bring the "ideal" hybrid closer. Place one VPLEX in each datacenter on top of your SANs (can be EMC or other).
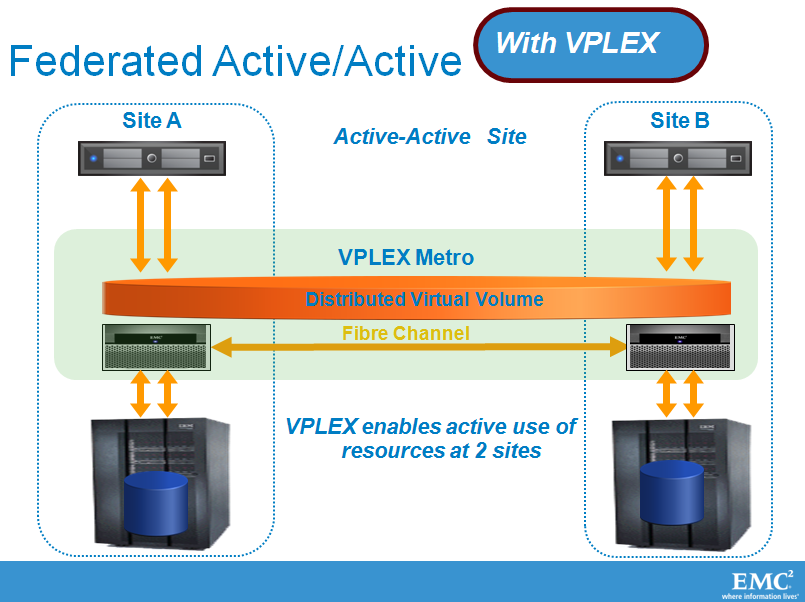
Click to enlarge
The cool thing about this VPLEX setup is that it is able to move a large VM (and even several large ones), even if that VM belongs to heavy OLTP database server, over to a remote datacenter very quickly and with acceptable performance impact.
Of course EMC does not disclose fully how they have managed to made this work. What follows is summary of what I managed to jot down. Both datacenters have part of the actual storagevolumes and are linked to each other with at least 2 fast FC network links. The underlying SANs have probably some form of networking RAID similar to the HP lefthand devices.
The virtual machine and data that is being moved, uses "normal" vmotion (no storage vmotion) towards the other datacenter. The VM can thus start immediately after the end of vmotion, after copying the right pages of the original host's memory. That takes only a minute or less, and meanwhile the VM keeps responding. The OLTP application on top is not disrupted in any way, just slowed down a bit. You can see below what happened when 5 OLTP databases were moved. A Swingbench benchmark on top of these VMs measured the response time before, during and after the movement of the 5 VMs.
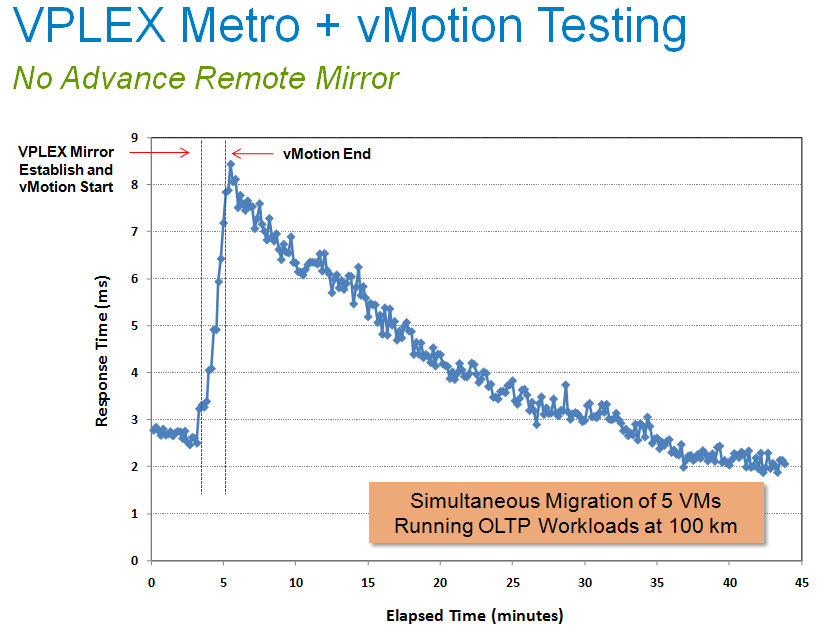
As the cache of the remote VPLEX device is "cold", it needs to get a lot of data from the other side. The remote VPLEX cache gets a lot of cache misses at first. So if you run a transactional load in the VM, you will notice higher latency after the vMotion: about 2.5 times higher (7.5 instead of 3 ms). After some time (40 minutes in this case), the second cache is also filled with the most requested blocks.
A directory based distributed cache coherence makes sure the VPLEX node can answer to the I/O requests, whether it be reads or writes. This is very similar to directory based CPU caches (here: the VPLEX cache) and how they interact with the RAM (here: the distributed "network RAID" virtual storage volume).
The underlying layer must take care of the rest: writes should not happen in both datacenters on the same block. So in the case of vMotion, the writes will be written by the VM that is active. So if the vmotion is not over yet, writing will happen first on the original location, and once the VM has been moved, the changes will be written at the new location.
EMC call this VPLEX device a geo disperse, cache coherent storage federation device. Right now the VPLEX METRO allows synchronous syncing over a distance of 100 km. The requirements are pretty staggering:
- An IP network with a minimum bandwidth of 622 Mbps
- The maximum latency between the two VMware vSphere servers cannot exceed 5 milliseconds (ms), about 100 km with a fiber network.
- The source and destination ESX servers must have a private network on the same IP subnet and broadcast domain.
So this is definitely very cool technology, but only for companies with deep pockets.

Click to enlarge
EMC does not want to stop there. A few months ago EMC anounced VPLEX Metro (5ms or about 100 km) synchronous. In 2011, the VPLEX family should be able to bridge 1000 km using asynchronous syncing. Later, even higher distances will be bridged.
That would lead to some massive migrations as you can see here. More info can als be found on Chad's personal blog.








26 Comments
View All Comments
HMTK - Tuesday, October 19, 2010 - link
Well you don't NEED cutting edge storage for a lot of things. In many cases more cheap(er) machines can be interesting than fewer more expensive machines. A lower specced machine in a large cluster of such machines going down might have less of an impact than a high end server in a cluster of only a few machines. For my customers (SMB's) I prefer more but less powerful machines. As usual YMMV.Exelius - Wednesday, October 20, 2010 - link
Very rarely do people actually need cutting edge. Even if you think you do; more often than not a good SAN operating across a few dozen spindles is much faster than you think. Storage on a small scale is tricky and expensive; storage on a large scale is easy, fast and cheap. You'd be surprised how fast a good SAN can be (even on iSCSI) if you have the right arrays, HBAs and switches.And "enterprise" cloud providers like SunGard and IBM will sell you storage, and deliver minimum levels of IOPS and/or throughput. They've done this for at least 5 years (which is the last time I priced one of them out.) It's expensive, but so is building your own environment. And remember to take into account labor costs over the life of the equipment; if your IT guy quits after 2 years you'll have to train someone, hire someone pre-trained, or (most likely,) hire a consultant at $250/hr every time you need anything changed.
Cloud is cheaper because you only need to train your IT staff on the cloud, not on whatever brand of server, HBAs, SAN, switches, disks, virtualization software, etc... For most companies, operating IT infrastructure is not a core competency, so outsource it already. You outsource your payroll to ADP, so why not your IT infrastructure to Amazon or Google?
Murloc - Tuesday, October 19, 2010 - link
I love these articles about IT stuff in large enterprises.They are so clear even for noobs. I don't know anything about this stuff but thanks to anandtech I get to know about these exciting developments.
dustcrusher - Tuesday, October 19, 2010 - link
"It won't let you tripple your VM resources in a few minutes, avoiding a sky high bill afterwards."Triple has an extra "p."
"If it works out well, those are bonusses,"
Extra "s" in bonuses.
HMTK - Wednesday, October 20, 2010 - link
I believe Johan was thinking of http://en.wikipedia.org/wiki/TripelJohanAnandtech - Sunday, October 24, 2010 - link
Scary how you can read my mind. Cheers :-)iwodo - Tuesday, October 19, 2010 - link
I admit first i am no expert in this field. But Rackspace Cloud Hosting seems much cheaper then Amazon. And i could never understand why use EC2 at all, what advantage does it give compare like RackSpace Cloud.What alert me was the cost you posted up, which surprise me.
iwodo - Tuesday, October 19, 2010 - link
Arh.. somehow posted without knowing it.And even with the cheaper price of Racksapce, i still consider the Cloud thing as expensive.
For small to medium size Web Site, Hosting still seems to be best value.
JonnyDough - Tuesday, October 19, 2010 - link
...and we don't want to "be there". I want control of my data thank you. :)pablo906 - Tuesday, October 19, 2010 - link
Metro Clusters aren't new and you can already active active metro clusters on 10MB links with a fair amount of success. NetApp does a pretty good job of this with XenServer. Is it scalable to extreme levels, well certainly it's not as scalable as a Fiber Channel on a 1GB link. This is interesting tech and has promise in 5 years. American bandwidth is still archaically priced and Telcos really bend you over for fiber. I spend over 500k /yr on telco side network expenses already and that's using a slew of 1MB links with fiber backbone.1GB links simply aren't even available in many places. I personally don't want my DR site 100km away from my main site. I'd like one on each coast if I was designing this system. It's definitely a good first step.
Having worked for ISP's I think they may be the only people in the world that will find this reasonable to implement quickly. ISP's generally have low latency multi GB link Fiber Rings that meshing a storage Fabric into wouldn't be difficult. The crazy part is it needs nearly the theoretical limit of the 1GB to operate so it really requires additional infrastructure costs. If a Tornado, Hurricane, or Earthquake hits your datacenter 100km away will likely also be feeling the effects. It is nice to replicate data with however in hopes that you don't completely loose all your physical equipment in both.
How long lasting is FC anyway. It seems there is a ton of emphasis still on FC when 10GB is showing scalability and ease of use that's really nice. It's an interesting cross roads for storage manufacturers. I've spoken to insiders at a couple of the BIG players who question the future of FC. I can't be the only person out there thinking that leveraging FC seems to be a loosing proposition right now. iSCSI over 10Gb is very fast and you have things like Link Aggregation, MPIO, and VLANS that really help scale those solutions and allow you to engineer some very interesting configurations. NFS over 10GB is another great technology that makes management extremely simple. You have VHD files and you move them around as needed.
Virtualization is a game changer in the Corporate IT world and we're starting to see some really cool ideas coming out of the big players.