Intel's Larrabee Architecture Disclosure: A Calculated First Move
by Anand Lal Shimpi & Derek Wilson on August 4, 2008 12:00 AM EST- Posted in
- GPUs
Thread and Data Management: It's Time to Blow Your Mind
With both the recent NIVIDA and AMD graphics hardware launches, we spent quite a bit of time talking about thread management. Since Larrabee is designed to be more of a collection of general purpose scalar and vector processing units, and vertex, primitive and pixel data (along with associate shader programs) are software managed. As we discussed what a context is for AMD and NVIDIA graphics hardware, a true context is going to be a different thing altogether on Larrabee.
We do have to make a point of saying before proceeding that NVIDIA and AMD are under no obligation to actually tell us how their architecture is physically implemented. It is entirely possible that much of the attributes of the hardware are not actually attributes of the hardware but simply reflections of how hardware resources are used. In recent discussions with both companies about certain realities of their hardware revealed to us that the belief is if the system behaves like a specific physical implementation then it effectively is the same as that physical implementation.
Of course, we disagree. And it is possible that some of this has more similarity with NVIDIA and AMD than they are letting on. But we'll go on what we've got for now, and assume that what Intel is doing is as divergent as it sounds.
Each Larrabee core on a chip (of which it seems likely there will be some multiple of 8 in the final product) can maintain 4 simultaneous software threads (4 contexts are kept active at a time). This gives the appearance of 4 virtual physical processors to software running directly on the hardware even though all four threads are sharing a single resource. It is very likely that the major purpose of this is to hide some of the long latency we hit when going to memory for texture data and the like.
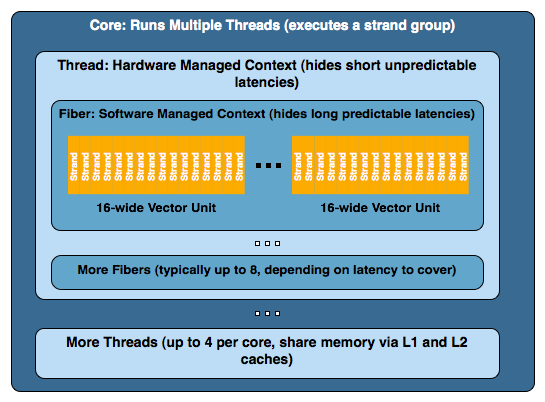
Now, for the purpose of graphics rendering using Intel's software rendering library or as it emulates DirectX and OpenGL, a thread is set up to manage the resources for a larger group of instructions and data that Intel calls a "fiber". Normally a thread will manage 8 fibers at a time. The hardware thread maintains a context in software for the fiber. The fiber's job is to manage the execution data parallel kernels on multiple groups of 16 "strands" (because the vector processor is 16-wide). A strand is what we have traditionally called a thread on other graphics hardware. The problem here is that Intel hardware is actually executing threads in a way that emulates hardware features of other architectures.
To put it together a little better, imagine one of Intel's threads as one of NVIDIA's TPCs, a fiber as an SM, and a strand as a thread. Okay, so it isn't that simple (simple?). But it is a sort of rough way of looking at it and a quick way of understand why naming is different here.
Let's take a deeper look at what goes on. With 4 threads per core (with at least 8 and hopefully something more like 32 cores), 8 fibers per thread, and some multiple of 16 strands per fiber, we could end up with a huge number of strands being managed simultaneously. This is active, running threads we are looking at as well. Since Larrabee will be a CPU in a true sense of the term, we can have as many threads as necessary live and waiting for a time slice. In the context of a normal CPU, this would be managed by the operating system, but as Larrabee will see the light of day as a graphics card, the driver will probably be managing timesharing issues an OS would normally perform.
While running ridiculous numbers of threads per core at a time might kill performance, unlike current GPUs, resource availability doesn't disrupt the creation of threads. Six of one, half dozen of the other? Maybe, and maybe not. Having active threads with data available to context switch to is key to hiding latency in NVIDIA and AMD hardware. If enough threads cannot be actively maintained, stalls happen and kill performance. Similar issues will impact Intel, and keeping dual-issue in-order hardware busy with multiple threads might be more easily managed if it can fall back on traditional CPU thread management paradigms to handle an abundance of threads that manage software that manages data parallel kernels.








101 Comments
View All Comments
NeonFlak - Thursday, November 15, 2012 - link
"Remember that Larrabee won't ship until sometime in 2009 or 2010, the first chips aren't even back from the fab yet, so not wanting to discuss how many cores Intel will be able to fit on a single Larrabee GPU makes sense. "