The Radeon HD 4850 & 4870: AMD Wins at $199 and $299
by Anand Lal Shimpi & Derek Wilson on June 25, 2008 12:00 AM EST- Posted in
- GPUs
A Quick Primer on ILP
NVIDIA throws ILP (instruction level parallelism) out the window while AMD tackles it head on.
ILP is parallelism that can be extracted from a single instruction stream. For instance, if i have a lot of math that isn't dependent on previous instructions, it is perfectly reasonable to execute all this math in parallel.
For this example on my imaginary architecture, instruction format is:
LineNumber INSTRUCTION dest-reg, source-reg-1, source-reg-2
This is compiled code for adding 8 numbers together. (i.e. A = B + C + D + E + F + G + H + I;)
1 ADD r2,r0,r1
2 ADD r5,r3,r4
3 ADD r8,r6,r7
4 ADD r11,r9,r10
5 ADD r12,r2,r5
6 ADD r13,r8,r11
7 ADD r14,r12,r13
8 [some totally independent instruction]
...
Lines 1,2,3 and 4 could all be executed in parallel if hardware is available to handle it. Line 5 must wait for lines 1 and 2, line 6 must wait for lines 3 and 4, and line 7 can't execute until all other computation is finished. Line 8 can execute at any point hardware is available.
For the above example, in two wide hardware we can get optimal throughput (and we ignore or assume full speed handling of read-after-write hazards, but that's a whole other issue). If we are looking at AMD's 5 wide hardware, we can't achieve optimal throughput unless the following code offers much more opportunity to extract ILP. Here's why:
From the above block, we can immediately execute 5 operations at once: lines 1,2,3,4 and 8. Next, we can only execute two operations together: lines 5 and 6 (three execution units go unused). Finally, we must execute instruction 7 all by itself leaving 4 execution units unused.
The limitations of extracting ILP are on the program itself (the mix of independent and dependent instructions), the hardware resources (how much can you do at once from the same instruction stream), the compiler (how well does the compiler organize basic blocks into something the hardware can best extract ILP from) and the scheduler (the hardware that takes independent instructions and schedules them to run simultaneously).
Extracting ILP is one of the most heavily researched areas of computing and was the primary focuses of CPU design until the advent of multicore hardware. But it is still an incredibly tough problem to solve and the benefits vary based on the program being executed.
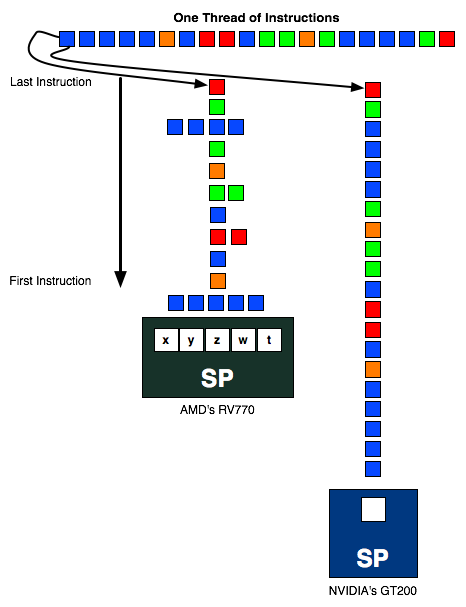
The instruction stream above is sent to an AMD and NVIDIA SP. In the best case scenario, the instruction stream going into AMD's SP should be 1/5th the length of the one going into NVIDIA's SP (as in, AMD should be executing 5 ops per SP vs. 1 per SP for NVIDIA) but as you can see in this exampe, the instruction stream is around half the height of the one in the NVIDIA column. The more ILP AMD can extract from the instruction stream, the better its hardware will do.
AMD's RV770 (And R6xx based hardware) needs to schedule 5 operations per thread every every clock to get the most out of their hardware. This certainly requires a bit of fancy compiler work and internal hardware scheduling, which NVIDIA doesn't need to bother with. We'll explain why in a second.
Instruction Issue Limitations and ILP vs TLP Extraction
Since a great deal of graphics code manipulates vectors like vertex positions (x,y,c,w) or colors (r,g,b,a), lots of things happen in parallel anyway. This is a fine and logical aspect of graphics to exploit, but when it comes down to it the point of extracting parallelism is simply to maximize utilization of hardware (after all, everything in a scene needs to be rendered before it can be drawn) and hide latency. Of course, building a GPU is not all about extracting parallelism, as AMD and NVIDIA both need to worry about things like performance per square millimeter, performance per watt, and suitability to the code that will be running on it.
NVIDIA relies entirely on TLP (thread level parallelism) while AMD exploits both TLP and ILP. Extracting TLP is much much easier than ILP, as the only time you need to worry about any inter-thread conflicts is when sharing data (which happens much less frequently than does dependent code within a single thread). In a graphics architecture, with the necessity of running millions of threads per frame, there are plenty of threads with which to fill the execution units of the hardware, and thus exploiting TLP to fill the width of the hardware is all NVIDIA needs to do to get good utilization.
There are ways in which AMD's architecture offers benefits though. Because AMD doesn't have to context switch wavefronts every chance it gets and is able to extract ILP, it can be less sensitive to the number of active threads running than NVIDIA hardware (however both do require a very large number of threads to be active to hide latency). For NVIDIA we know that to properly hide latency, we must issue 6 warps per SM on G80 (we are not sure of the number for GT200 right now), which would result in a requirement for over 3k threads to be running at a time in order to keep things busy. We don't have similar details from AMD, but if shader programs are sufficiently long and don't stall, AMD can serially execute code from a single program (which NVIDIA cannot do without reducing its throughput by its instruction latency). While AMD hardware can certainly handle a huge number of threads in flight at one time and having multiple threads running will help hide latency, the flexibility to do more efficient work on serial code could be an advantage in some situations.
ILP is completely ignored in NVIDIA's architecture, because only one operation per thread is performed at a time: there is no way to exploit ILP on a scalar single-issue (per context) architecture. Since all operations need to be completed anyway, using TLP to hide instruction and memory latency and to fill available execution units is a much less cumbersome way to go. We are all but guaranteed massive amounts of TLP when executing graphics code (there can be many thousand vertecies and millions of pixels to process per frame, and with many frames per second, that's a ton of threads available for execution). This makes the lack of attention to serial execution and ILP with a stark focus on TLP not a crazy idea, but definitely divergent.
Just from the angle of extracting parallelism, we see NVIDIA's architecture as the more elegant solution. How can we say that? The ratio of realizable to peak theoretical performance. Sure, Radeon HD 4870 has 1.2 TFLOPS of compute potential (800 execution units * 2 flops/unit (for a multiply-add) * 750MHz), but in the vast majority of cases we'll look at, NVIDIA's GeForce GTX 280 with 933.12 GFLOPS ((240 SPs * 2 flops/unit (for multiply-add) + 60 SFUs * 4 flops/unit (when doing 4 scalar muls paired with MADs run on SPs)) * 1296MHz) is the top performer.
But that doesn't mean NVIDIA's architecture is necessarily "better" than AMD's architecture. There are a lot of factors that go into making something better, not the least of which is real world performance and value. But before we get to that, there is another important point to consider. Efficiency.








215 Comments
View All Comments
araczynski - Wednesday, June 25, 2008 - link
...as more and more people are hooking up their graphics cards to big HDTVs instead of wasting time with little monitors, i keep hoping to find out whether the 9800gx2/4800 lines have proper 1080p scaling/synching with the tvs? for example the 8800 line from nvidia seems to butcher 1080p with tv's.anyone care to speak from experience?
DerekWilson - Wednesday, June 25, 2008 - link
i havent had any problem with any modern graphics card (dvi or hdmi) and digital hdtvsi haven't really played with analog for a long time and i'm not sure how either amd or nvidia handle analog issues like overscan and timing.
araczynski - Wednesday, June 25, 2008 - link
interesting, what cards have you worked with? i have the 8800gts512 right now and have the same problem as with the 7900gtx previously. when i select 1080p for the resolution (which the drivers recognize the tv being capable of as it lists it as the native resolution) i get a washed out messy result where the contrast/brightness is completely maxed (sliders do little to help) as well as the whole overscan thing that forces me to shrink the displayed image down to fit the actual tv (with the nvidia driver utility). 1600x900 can usually be tolerable in XP (not in vista for some reason) and 1080p is just downright painful.i suppose it could by my dvi to hdmi cable? its a short run, but who knows... i just remember reading a bit on the nvidia forums that this is a known issue with the 8800 line, so was curious as to how the 9800 line or even the 4800 line handle it.
but as the previous guy mentioned, ATI does tend to do the TV stuff much better than nvidia ever did... maybe 4850 crossfire will be in my rig soon... unless i hear more about the 4870x2 soon...
ChronoReverse - Wednesday, June 25, 2008 - link
ATI cards tend to do the TV stuff properlyFXi - Wednesday, June 25, 2008 - link
If Nvidia doesn't release SLI to Intel chipsets (and on a $/perf ratio it might not even help if it does), the 4870 in CF is going to stop sales of the 260's into the ground.Releasing SLI on Intel and easing the price might help ease that problem, but of course they won't do it. Looks like ATI hasn't just come back, they've got a very, very good chip on their hands.
Powervano - Wednesday, June 25, 2008 - link
Anand and DerekWhat about temperatures of HD4870 under IDLE and LOAD? page 21 only shows power comsumption.
iwodo - Wednesday, June 25, 2008 - link
Given how ATI architecture greatly rely on maximizing its Shader use, wouldn't driver optimization be much more important then Nvidia in this regard?And is ATI going about Nvidia CUDA? Given CUDA now have a much bigger exposure then how ever ATI is offering.. CAL or CTM.. i dont even know now.
DerekWilson - Wednesday, June 25, 2008 - link
getting exposure for AMD's own GPGPU solutions and tools is going to be though, especially in light of Tesla and the momentum NVIDIA is building in the higher performance areas.they've just got to keep at it.
but i think their best hope is in Apple right now with OpenCL (as has been mentioned above) ...
certainly AMD need to keep pushing their GPU compute solutions, and trying to get people to build real apps that they can point to (like folding) and say "hey look we do this well too" ...
but in the long term i think NVIDIA's got the better marketing there (both to consumers and developers) and it's not likely going to be until a single compute language emerges as the dominant one that we see level competition.
Amiga500 - Wednesday, June 25, 2008 - link
AMD are going to continue to use the open source alternative - Open CL.In a relatively fledgling program environment, it makes all the sense in the world for developers to use the open source option, as compatibility and interoperability can be assured, unlike older environments like graphics APIs.
OSX v10.6 (snow lepoard) will use Open CL.
DerekWilson - Wednesday, June 25, 2008 - link
OpenCL isn't "open source" ...Apple is trying to create an industry standard heterogeneous compute language.
What we need is a compute language that isn't "owned" by a specific hardware maker. The problem is that NVIDIA has the power to redefine the CUDA language as it moves forward to better fit their architecture. Whether they would do this or not is irrelevant in light of the fact that it makes no sense for a competitor to adopt the solution if the possibility exists.
If NVIDIA wants to advance the industry, eventually they'll try and get CUDA ANSI / ISO certified or try to form an industry working group to refine and standardize it. While they have the exposure and power in CUDA and Tesla they won't really be interested in doing this (at least that's our prediction).
Apple is starting from a standards centric view and I hope they will help build a heterogeneous computing language that combines the high points of all the different solutions out there now into something that's easy to develop or and that can generate code to run well on all architectures.
but we'll have to wait and see.