The Radeon HD 4850 & 4870: AMD Wins at $199 and $299
by Anand Lal Shimpi & Derek Wilson on June 25, 2008 12:00 AM EST- Posted in
- GPUs
A Quick Primer on ILP
NVIDIA throws ILP (instruction level parallelism) out the window while AMD tackles it head on.
ILP is parallelism that can be extracted from a single instruction stream. For instance, if i have a lot of math that isn't dependent on previous instructions, it is perfectly reasonable to execute all this math in parallel.
For this example on my imaginary architecture, instruction format is:
LineNumber INSTRUCTION dest-reg, source-reg-1, source-reg-2
This is compiled code for adding 8 numbers together. (i.e. A = B + C + D + E + F + G + H + I;)
1 ADD r2,r0,r1
2 ADD r5,r3,r4
3 ADD r8,r6,r7
4 ADD r11,r9,r10
5 ADD r12,r2,r5
6 ADD r13,r8,r11
7 ADD r14,r12,r13
8 [some totally independent instruction]
...
Lines 1,2,3 and 4 could all be executed in parallel if hardware is available to handle it. Line 5 must wait for lines 1 and 2, line 6 must wait for lines 3 and 4, and line 7 can't execute until all other computation is finished. Line 8 can execute at any point hardware is available.
For the above example, in two wide hardware we can get optimal throughput (and we ignore or assume full speed handling of read-after-write hazards, but that's a whole other issue). If we are looking at AMD's 5 wide hardware, we can't achieve optimal throughput unless the following code offers much more opportunity to extract ILP. Here's why:
From the above block, we can immediately execute 5 operations at once: lines 1,2,3,4 and 8. Next, we can only execute two operations together: lines 5 and 6 (three execution units go unused). Finally, we must execute instruction 7 all by itself leaving 4 execution units unused.
The limitations of extracting ILP are on the program itself (the mix of independent and dependent instructions), the hardware resources (how much can you do at once from the same instruction stream), the compiler (how well does the compiler organize basic blocks into something the hardware can best extract ILP from) and the scheduler (the hardware that takes independent instructions and schedules them to run simultaneously).
Extracting ILP is one of the most heavily researched areas of computing and was the primary focuses of CPU design until the advent of multicore hardware. But it is still an incredibly tough problem to solve and the benefits vary based on the program being executed.
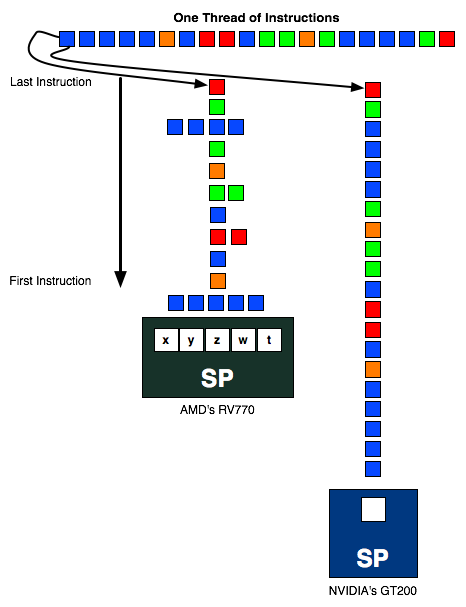
The instruction stream above is sent to an AMD and NVIDIA SP. In the best case scenario, the instruction stream going into AMD's SP should be 1/5th the length of the one going into NVIDIA's SP (as in, AMD should be executing 5 ops per SP vs. 1 per SP for NVIDIA) but as you can see in this exampe, the instruction stream is around half the height of the one in the NVIDIA column. The more ILP AMD can extract from the instruction stream, the better its hardware will do.
AMD's RV770 (And R6xx based hardware) needs to schedule 5 operations per thread every every clock to get the most out of their hardware. This certainly requires a bit of fancy compiler work and internal hardware scheduling, which NVIDIA doesn't need to bother with. We'll explain why in a second.
Instruction Issue Limitations and ILP vs TLP Extraction
Since a great deal of graphics code manipulates vectors like vertex positions (x,y,c,w) or colors (r,g,b,a), lots of things happen in parallel anyway. This is a fine and logical aspect of graphics to exploit, but when it comes down to it the point of extracting parallelism is simply to maximize utilization of hardware (after all, everything in a scene needs to be rendered before it can be drawn) and hide latency. Of course, building a GPU is not all about extracting parallelism, as AMD and NVIDIA both need to worry about things like performance per square millimeter, performance per watt, and suitability to the code that will be running on it.
NVIDIA relies entirely on TLP (thread level parallelism) while AMD exploits both TLP and ILP. Extracting TLP is much much easier than ILP, as the only time you need to worry about any inter-thread conflicts is when sharing data (which happens much less frequently than does dependent code within a single thread). In a graphics architecture, with the necessity of running millions of threads per frame, there are plenty of threads with which to fill the execution units of the hardware, and thus exploiting TLP to fill the width of the hardware is all NVIDIA needs to do to get good utilization.
There are ways in which AMD's architecture offers benefits though. Because AMD doesn't have to context switch wavefronts every chance it gets and is able to extract ILP, it can be less sensitive to the number of active threads running than NVIDIA hardware (however both do require a very large number of threads to be active to hide latency). For NVIDIA we know that to properly hide latency, we must issue 6 warps per SM on G80 (we are not sure of the number for GT200 right now), which would result in a requirement for over 3k threads to be running at a time in order to keep things busy. We don't have similar details from AMD, but if shader programs are sufficiently long and don't stall, AMD can serially execute code from a single program (which NVIDIA cannot do without reducing its throughput by its instruction latency). While AMD hardware can certainly handle a huge number of threads in flight at one time and having multiple threads running will help hide latency, the flexibility to do more efficient work on serial code could be an advantage in some situations.
ILP is completely ignored in NVIDIA's architecture, because only one operation per thread is performed at a time: there is no way to exploit ILP on a scalar single-issue (per context) architecture. Since all operations need to be completed anyway, using TLP to hide instruction and memory latency and to fill available execution units is a much less cumbersome way to go. We are all but guaranteed massive amounts of TLP when executing graphics code (there can be many thousand vertecies and millions of pixels to process per frame, and with many frames per second, that's a ton of threads available for execution). This makes the lack of attention to serial execution and ILP with a stark focus on TLP not a crazy idea, but definitely divergent.
Just from the angle of extracting parallelism, we see NVIDIA's architecture as the more elegant solution. How can we say that? The ratio of realizable to peak theoretical performance. Sure, Radeon HD 4870 has 1.2 TFLOPS of compute potential (800 execution units * 2 flops/unit (for a multiply-add) * 750MHz), but in the vast majority of cases we'll look at, NVIDIA's GeForce GTX 280 with 933.12 GFLOPS ((240 SPs * 2 flops/unit (for multiply-add) + 60 SFUs * 4 flops/unit (when doing 4 scalar muls paired with MADs run on SPs)) * 1296MHz) is the top performer.
But that doesn't mean NVIDIA's architecture is necessarily "better" than AMD's architecture. There are a lot of factors that go into making something better, not the least of which is real world performance and value. But before we get to that, there is another important point to consider. Efficiency.








215 Comments
View All Comments
Final Destination II - Wednesday, June 25, 2008 - link
Dear girls and guys,does anyone know of a manufacturer, who offers a HD4850 with a better cooler? I'm desperately searching for one...
Please reply!
Graven Image - Wednesday, June 25, 2008 - link
Asus recently announced a 4850 with a non-stock cooler, though their version still doesn't expel the air out the back like a dual slot design. (http://www.asus.com/news_show.aspx?id=11871)">http://www.asus.com/news_show.aspx?id=11871). Its not available yet thought. My guess is mid-July we'll probably start seeing a couple different fan and heatsink designs.strikeback03 - Thursday, June 26, 2008 - link
Only dual-slot card I've ever used was an EVGA 8800GTS 640, it sucked air in the back and blew it into the case.Final Destination II - Wednesday, June 25, 2008 - link
Nice! 7°C cooler, that's a start! I guess I'll wait a bit more, then.Spacecomber - Wednesday, June 25, 2008 - link
Although I'm somewhat dubious about dual card solutions, I keep looking at the benchmarks and then at the prices for a couple of 8800 GTs.Perhaps, if the 4870 forces Nvidia to reduce their prices for the GTX 260 and the GTX 280, they will likewise bring down the price for the 9800 GX2. This is already the fastest single card solution, and it sells for less than the GTX 280. If this card starts selling for under $400 (maybe around $350), will this become Nvidia's best answer to the 4870?
Given the performance and the prices for the 4870 and the 9800 GX2 will Nvidia be able to price the GTX 280 competitively, or will it simply be vanity product - ridiculously priced and produced only in very small numbers?
It should be interesting to see where the prices for video cards end up over the course of the next few weeks.
kelmerp - Wednesday, June 25, 2008 - link
Better HD knickknacks? Better offloading/upscaling?chizow - Wednesday, June 25, 2008 - link
The HD4000 series have better HDMI sound support with 8ch LPCM over HDMI, but still can't pass uncompressed bistreams. Image quality hasn't changed as there isn't really any room to improve.kelmerp - Wednesday, June 25, 2008 - link
It would be nice to have a video card, where it doesn't matter how weak the current-gen processor is (say the lowliest celeron available), the card can still output 1080p HDTV without dropping any frames.Chaser - Wednesday, June 25, 2008 - link
Good to have back at the FRONT of the finish line.JPForums - Wednesday, June 25, 2008 - link
Ragarding the SLI scaling in Witcher:The GTX 280 SLI setup may be running into a bottleneck or driver issues, rather than seeing inherent scaling issues. Consider, the 9800 GTX+ SLI setup scales from 22.9 to 44.5. So the scaling isn't an inherent SLI scaling problem. Though it may point to scaling issues specific to the GTX 280, it is more likely that the problem lies elsewhere. I do, however, agree with your general statement that when CF is working properly, it tends to scale better. In my systems, it seems to require less CPU overhead.