AMD Ryzen 7 8700G and Ryzen 5 8600G Review: Zen 4 APUs with RDNA3 Graphics
by Gavin Bonshor on January 29, 2024 9:00 AM EST- Posted in
- CPUs
- AMD
- APUs
- Phoenix
- 4nm
- Zen 4
- RDNA3
- AM5
- Ryzen 8000G
- Ryzen 7 8700G
- Ryzen 5 8600G
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
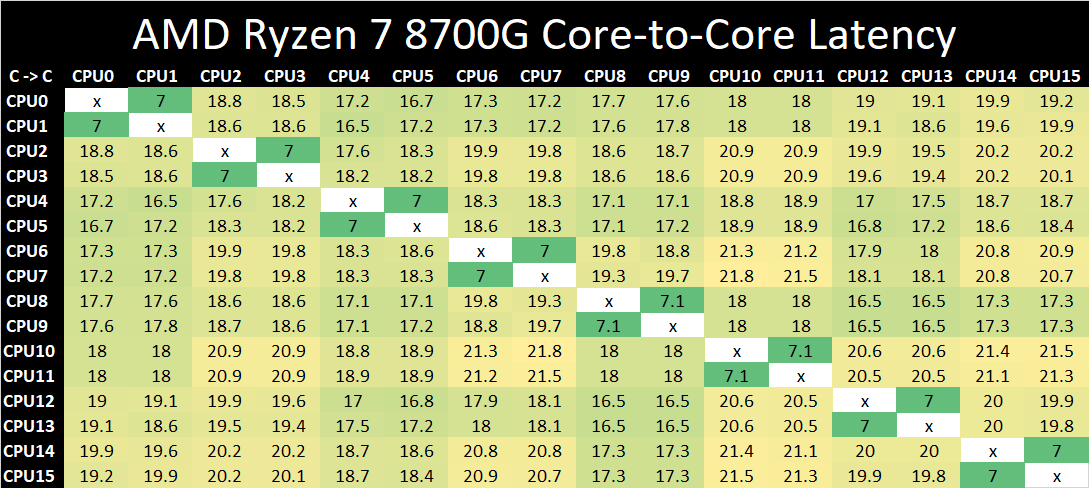
Looking at core-to-core latencies of the AMD Ryzen 7 8700G, as this is a monolithic Phoenix die, we can see good inter-core latencies between each of the eight individual Zen 4 cores. Going within the core, we can see solid latencies of 7ns, while things inter-core range between 17 and 21ns, showing that the Ryzen 7 8700G uses a single core cluster of eight cores.
Similar to what we've seen on previous iterations of Zen 4 and Zen 3, albeit on processors with multiple core complex (CCXs) such as the Ryzen 9 7950 and Ryzen 9 5950X, inter-core latencies are strong and low. In contrast, the Ryzen 7 8700G and other Ryzen 8000G monolithic chips on a single die remove the complications and penalties of connecting through AMD's Infinity Fabric interconnect. The Ryzen 7 8700G uses TSMC's refined 4nm manufacturing process, exactly the same as the Ryzen 7040 mobile, which is coincidentally the exact same design as the 8700G, given that AMD has repurposed Phoenix for use on AMD's AM5 desktop platform.
The core-to-core latency performance is inherently strong on the Ryzen 7 8700G, with low inter-core latencies. As expected, latency degrades a little going across the entire complex, but certainly not within the range where we would expect these penalties to cause latency issues when cores have to communicate with each other.








111 Comments
View All Comments
TheinsanegamerN - Tuesday, January 30, 2024 - link
guys WHY would you use a CPU only test in a CPU REVIEW??!?!?!?t.s - Tuesday, January 30, 2024 - link
Cause it have best iGPU in its class. If you won't test that, why bother testing, as it's almost certain that 7700x or 7700 will be better.AndrewJacksonZA - Tuesday, January 30, 2024 - link
👍TheinsanegamerN - Wednesday, January 31, 2024 - link
Ok, and in the CPU bench section they use a CPU test. How would you know if a 7700 would be better in CPU load if you dont test it?AndrewJacksonZA - Tuesday, January 30, 2024 - link
guys WHY would you only test PART of a CPU in a CPU REVIEW??!?!?!?TheinsanegamerN - Wednesday, January 31, 2024 - link
How DARE we want to see what a CPU does in a CPU review. WAAAH I NEED IGPU OR ILL CRY WAAAAHFWhitTrampoline - Tuesday, January 30, 2024 - link
Because AMD does not support ROCm/HIP for its iGPUs and its ROCm/HIP for consumer dGPUs is lacking as well on Linux. And the Blender Foundation starting with Blender 3.0/Later editions has dropped supporting OpenCL as the GPU compute API. And so since Blender 3.0/later the Blender Foundation only supports Nvidia's CUDA for non Apple PCs/Laptops and Apple's Metal for Apple silicon for Blender 3D 3.0/later editions.So without any Ryzen iGPU support for ROCm/HIP there's nothing to take the CUDA Intermediate Language Representation(ILR) and convert that to a form that can be executed on Radeon iGPU/dGPU hardware. And for Intel's iGPUs and dGPUs it's Intel's OneAPI/Level-0 that does the translating of the CUDA ILR to a form than can be executed on Intel's iGPU/dGPU hardware and for Intel that OneAPI/Level-0 works for Windows and Linux!
Blender 3D generates CUDA PTX ILR and All GPU Makers us Intermediate Languages for GPUs so GPU makers/others ship no pre-compiled binaries where software gets directly compiled into the GPUs Native Instruction Set in advance. And that's so the ILR code remains portable across OS/Ecosystems and GPU makers are free to modify their GPU ISA and still maintain comparability with software that only gets compiled into a portable Intermediate language Representation(ILR)
FWhitTrampoline - Tuesday, January 30, 2024 - link
Edit: maintain comparabilityto: maintain compatibility
I hate Firefox's Spell Checker its a Train Wreck as always!
thestryker - Monday, January 29, 2024 - link
Feels like these APUs deserve a DRAM scaling article comparing the IGP performance.GeoffreyA - Tuesday, January 30, 2024 - link
Yes, that would be a nice one. Always necessary for APUs.