Server Guide part 2: Affordable and Manageable Storage
by Johan De Gelas on October 18, 2006 6:15 PM EST- Posted in
- IT Computing
Enterprise SATA
So the question becomes: will SATA conquer the enterprise market with the SAS Trojan horse, killing off the SCSI disks? Is there any reason to pay 4 times more for a SCSI based disk which has hardly one third of the capacity of a comparable SATA disk just because the former is about twice as fast? It seems ridiculous to pay 10 times more for the same capacity.
Just like with servers, the Reliability, Availability and Serviceability (RAS) of enterprise disks must be better than desktop disks to be able to keep the TCO under control. Enterprise disks are simply much more reliable. They use stiffer covers, heads with very high rigidity, expensive and more reliable rotation engines combined with smart servo algorithms. But that is not all; the drive electronics of SCSI disks can and do perform a lot more data integrity checks.
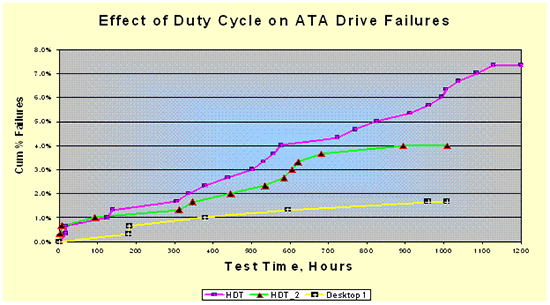
The rate of failures increase quickly as SATA drives are subjected to server workloads. Source: Seagate
The difference in reliability between typical SATA and real enterprise disks has been proven in a recent test by Seagate. Seagate exposed three groups of 300 desktop drives to high-duty-cycle sequential and random workloads. Enterprise disks list a slightly higher or similar failure rate than desktop drives, but that does not mean they are the same. Enterprise disks are tested for heavy duty highly random workloads and desktop drives are tested with desktop workloads. Seagate's tests revealed that desktop drives failed twice as often in the sequential server tests than with normal desktop use. When running random server or transactional workloads, SATA drives failed four times as often![²] In other words, it is not wise to use SATA drives for transactional database environments; you need real SCSI/SAS enterprise disks which are made to be used for the demanding server loads.
Even the so called "Nearline" (Seagate) or "Raid Edition" (RE, Western Digital) SATA drives which are made to operate in enterprise storage racks, and which are more reliable than desktop disks, are not made for the mission critical, random transactional applications. Their MTBF (Mean Time Between Failure) is still at least 20% lower than typical enterprise disks, and they will show the similar failure rates when used with highly random server workloads as desktop drives.
Also, the current SATA drives on average experience an Unrecoverable Error every 12.5 terabytes written or read (EUR of 1 in 1014 bits). Thanks to the sophisticated drive electronics, SAS/SCSI disks experience these kinds of errors 100 (!) times less. It would seem that EUR numbers are so small that they are completely negligible, but consider the situation where one of your hard drives fails in a RAID-5 or 6 configuration. Rebuilding a RAID-5 array with five 200 GB SATA drives results in reading 0.8 terabytes and writing 0.2 terabytes, in total 1 terabytes. So you have 1/12.5 or 8% chance of getting an EUR on this SATA array. If we look at a similar SCSI enterprise array, we would get a 0.08% chance on one unrecoverable error. It is clear an 8% chance of getting data loss is a pretty bad gamble for a mission critical application.
Another good point that Seagate made in the same study concerns vibration. When a lot of disk spindles and actuators are performing a lot of very random I/O operations in a big storage rack, quite a bit of rotational vibration is the result. In the best case the actuator will have to take a bit more time to get to the right sector (higher seek time) but in the worst case the read operation has to be retried. This can only be detected by the software driver, which means that the performance of the disk will be very low. Enterprise disks can take about 50% more vibration than SATA desktop drives before 50% higher seek times kill the random disk performance.
So the question becomes: will SATA conquer the enterprise market with the SAS Trojan horse, killing off the SCSI disks? Is there any reason to pay 4 times more for a SCSI based disk which has hardly one third of the capacity of a comparable SATA disk just because the former is about twice as fast? It seems ridiculous to pay 10 times more for the same capacity.
Just like with servers, the Reliability, Availability and Serviceability (RAS) of enterprise disks must be better than desktop disks to be able to keep the TCO under control. Enterprise disks are simply much more reliable. They use stiffer covers, heads with very high rigidity, expensive and more reliable rotation engines combined with smart servo algorithms. But that is not all; the drive electronics of SCSI disks can and do perform a lot more data integrity checks.
The rate of failures increase quickly as SATA drives are subjected to server workloads. Source: Seagate
The difference in reliability between typical SATA and real enterprise disks has been proven in a recent test by Seagate. Seagate exposed three groups of 300 desktop drives to high-duty-cycle sequential and random workloads. Enterprise disks list a slightly higher or similar failure rate than desktop drives, but that does not mean they are the same. Enterprise disks are tested for heavy duty highly random workloads and desktop drives are tested with desktop workloads. Seagate's tests revealed that desktop drives failed twice as often in the sequential server tests than with normal desktop use. When running random server or transactional workloads, SATA drives failed four times as often![²] In other words, it is not wise to use SATA drives for transactional database environments; you need real SCSI/SAS enterprise disks which are made to be used for the demanding server loads.
Even the so called "Nearline" (Seagate) or "Raid Edition" (RE, Western Digital) SATA drives which are made to operate in enterprise storage racks, and which are more reliable than desktop disks, are not made for the mission critical, random transactional applications. Their MTBF (Mean Time Between Failure) is still at least 20% lower than typical enterprise disks, and they will show the similar failure rates when used with highly random server workloads as desktop drives.
Also, the current SATA drives on average experience an Unrecoverable Error every 12.5 terabytes written or read (EUR of 1 in 1014 bits). Thanks to the sophisticated drive electronics, SAS/SCSI disks experience these kinds of errors 100 (!) times less. It would seem that EUR numbers are so small that they are completely negligible, but consider the situation where one of your hard drives fails in a RAID-5 or 6 configuration. Rebuilding a RAID-5 array with five 200 GB SATA drives results in reading 0.8 terabytes and writing 0.2 terabytes, in total 1 terabytes. So you have 1/12.5 or 8% chance of getting an EUR on this SATA array. If we look at a similar SCSI enterprise array, we would get a 0.08% chance on one unrecoverable error. It is clear an 8% chance of getting data loss is a pretty bad gamble for a mission critical application.
Another good point that Seagate made in the same study concerns vibration. When a lot of disk spindles and actuators are performing a lot of very random I/O operations in a big storage rack, quite a bit of rotational vibration is the result. In the best case the actuator will have to take a bit more time to get to the right sector (higher seek time) but in the worst case the read operation has to be retried. This can only be detected by the software driver, which means that the performance of the disk will be very low. Enterprise disks can take about 50% more vibration than SATA desktop drives before 50% higher seek times kill the random disk performance.








21 Comments
View All Comments
Bill Todd - Saturday, October 28, 2006 - link
It's quite possible that the reason you are seeing far fewer unrecoverable errors than the specs would suggest is that you're reading all or at least a large percentage of your data far more frequently than the specs assume. Background 'scrubbing' of data - using a disk's idle periods to scan its surface and detect any sectors which are unreadable (in which case they can be restored from a mirror or parity-generated copy if one exists) or becoming hard to read (in which case they can just be restored to better health, possibly in a different location, from their own contents) - decreases the incidence of unreadable sectors by several orders of magnitude compared to the value specified, and the amount of reading that you're doing may be largely equivalent to such scrubbing (or, for that matter, perhaps you're actively scrubbing as well).While Johan's article is one of the best that I've seen on storage technology in years, in this respect I think he may have been a bit overly influenced by Seagate marketing, which conveniently all but ignores (and certainly makes no attempt to quantify) the effect of scrubbing on potential data loss from using those alleged-risky SATA upstarts. Seagate, after all, has a lucrative high-end drive franchise to protect; we see a similar bias in their emphasis on the lack of variable sector sizes in SATA, with no mention of new approaches such as Sun's ZFS that attain more comprehensive end-to-end integrity checks without needing them, and while higher susceptibility to rotational vibration is a legitimate knock, it's worst in precisely those situations where conventional SATA drives are inappropriate for other reasons (intense, continuous-duty-cycle small-random-access workloads: I'd really have liked to have seen more information on just how well WD SATA Raptors match enterprise drives in that area, because if one can believe their specs they would seem to be considerably more cost-effective solutions in most such instances).
- bill
JohanAnandtech - Thursday, October 19, 2006 - link
"Nonetheless, something bugs me in your article on Seagate test. I manage a cluster of servers whose total throughoutput is around 110 TB a day (using around 2400 SATA disks). With Seagate figure (an Unrecoverable Error every 12.5 terabytes written or read), I would get 10 Unrecoverable Errors every day. Which, as far as I know, is far away from what I may see (a very few per week/month). "1. The EUR number is worst case, so the 10 Unrec errors you expect to see are really the worst situation that you would get.
2. Cached reads are not included as you do not access the magnetic media. So if on average the servers are able to cache rather well, you are probably seeing half of that throughtput.
And it also depends on how you measured that. Is that throughput on your network or is that really measured like bi/bo of Vmstat or another tool?
Fantec - Thursday, October 19, 2006 - link
There is no cache (for two reason, first the data is accessed quite randomly while there is only 4 GB of memory for 6 TB of data, second data are stored/accessed on block device in raw mode). And, indeed, throughoutput is mesured on network but figures from servers match (iostat).
Sunrise089 - Thursday, October 19, 2006 - link
I liked this story, but I finished feeling informed but not satisfied. I love AT's focus on real-world performance, so I think an excellent addition would be more info into actually building a storage system, or at least some sort of a buyers guide to let us know how the tech theory translates over to the marketplace. The best idea would be a tour of AT's own equipment and a discussion of why it was chosen.JohanAnandtech - Thursday, October 19, 2006 - link
If you are feeling informed and not satisfied, we have reached our goal :-). The next article will go in through the more complex stuff: when do I use NAS, when do I use DAS and SAN. What about iSCSI and so on. We are also working to having different storage solutions in our lab.stelleg151 - Wednesday, October 18, 2006 - link
In the table the cheetah decodes 1000block of 4KB faster than the raptor decodes 100 blocks of 4KB. Guessing this is a typo. Liked the article.JarredWalton - Wednesday, October 18, 2006 - link
Yeah, I notified Johan of the error but figured it wasn't big enough problem to hold back releasing the article. I guess I can Photoshop the image myself... I probably should have just done that, but I was thinking it would be more difficult than it is. The error is corrected now.slashbinslashbash - Wednesday, October 18, 2006 - link
I appreciate the theory and the mentioning of some specific products and the general recommendations in this article, but you started off mentioning that you were building a system for AT's own use (at the lowest reasonable cost) without fully going into exactly what you ended up using or how much it cost.So now I know something about SAS, SATA, and other technologies, but I have no idea what it will actually cost me to get (say) 1TB of highly-reliable storage suitable for use in a demanding database environment. I would love to see a line-item breakdown of the system that you ended up buying, along with prices and links to stores where I can buy everything. I'm talking about the cables, cards, drives, enclosures, backplanes, port multipliers, everything.
Of course my needs aren't the same as AnandTech's needs, but I just need to get an idea of what a typical "total solution" costs and then scale it to my needs. Also it'd be cool to have a price/performance comparison with vendor solutions like Apple, Sun, HP, Dell, etc.
BikeDude - Friday, October 20, 2006 - link
What if you face a bunch of servers with modest disk I/O that require high availability? We typically use SATA drives in RAID-1 configurations, but I've seen some disturbing issues with the onboard SATA RAID controller on a SuperMicro server which leads me to believe that SCSI is the right way to go for us. (the issue was that the original Adaptec driver caused Windows to eventually freeze given a certain workload pattern -- I've also seen mirrors that refuse to rebuild after replacing a drive; we've now stopped buying Maxtor SATA drives completely)More to the point: Seagate has shown that massive amount of IO requires enterprise class drives, but do they say anything about how enterprise class drives behave with a modest desktop-type load? (I wish the article linked directly to the document on Seagate's site, instead it links to a powerpoint presentation hosted by microsoft?)
JohanAnandtech - Thursday, October 19, 2006 - link
Definitely... When I started writing this series I start to think about what I was asking myself years ago. For starters, what the weird I/O per second benchmarking. If you are coming from the workstation world, you expect all storage benchmarks to be in MB/s and ms.Secondly, one has to know the interfaces available. The features of SAS for example could make you decide to go for a simple DAS instead of an expensive SAN. Not always but in some cases. So I had to make sure that before I start talking iSCSI, FC SAN, DAS that can be turned in to SAN etc., all my readers know what SAS is all about.
So I hope to address the things you brought up in the second storage article.