Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
SPEC - Multi-Threaded Performance
Picking up from the power efficiency discussion, let’s dive directly into the multi-threaded SPEC results. As usual, because these are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2 (for Zen3 as well due to GCC 10.2 not having znver3).
The new Ice Lake SP parts are using the -march/-mtune=icelake-server target. It’s to be noted that I briefly tested the system with the Skylake binaries, with little differences within margin of error.
I’m limiting the detailed comparison data to the flagship SKUs, to indicate peak performance of each platform. For that reason it’s not exactly as much an architectural comparison as it’s more of a top SKU comparison.
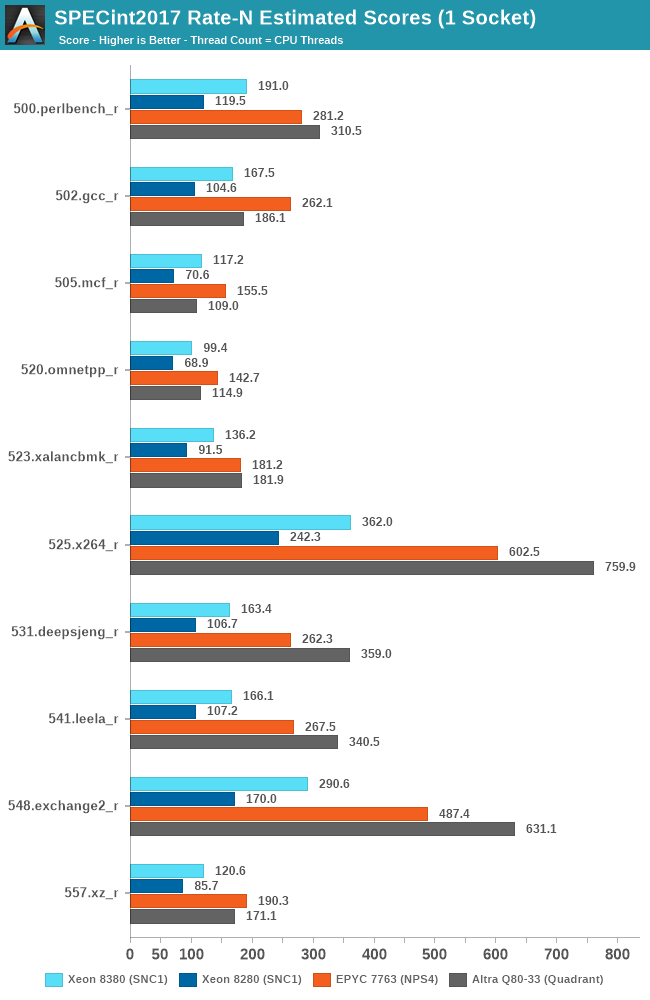
To not large surprise, the Xeon 8380 is posting very impressive performance advancements compared to the Xeon 8280, with large increases across the board for all workloads. The geo-mean increase is +54% with a low of +40% up to a high of +71%.
It’s to be noted that while the new Ice Lake system is a major generational boost, it’s nowhere near enough to catch up with the performance of the AMD Milan or Rome, or Ampere’s Altra when it comes to total throughput.
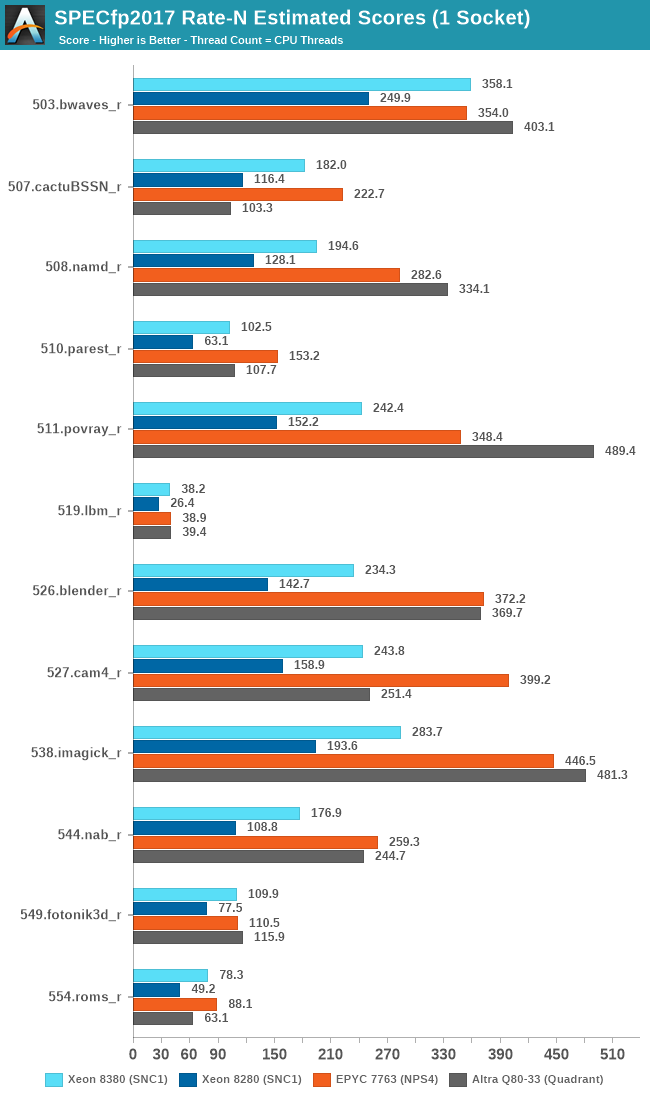
Looking at the FP suite, we have more workloads that are purely memory performance bound, and the Ice Lake Xeon 8380 again is posting significant performance increases compared to its predecessor, with a geo-mean of +53% with a range of +41% to +64%.
In some of the workloads, the new Xeon now catches up and is on par with AMD’s EPYC 7763 due to the fact that both systems have the same memory configuration with 8-channel DDR4-3200.
In any other workloads that requires more CPU compute power, the Xeon doesn’t hold up nearly as well, falling behind the competition by significant margins.
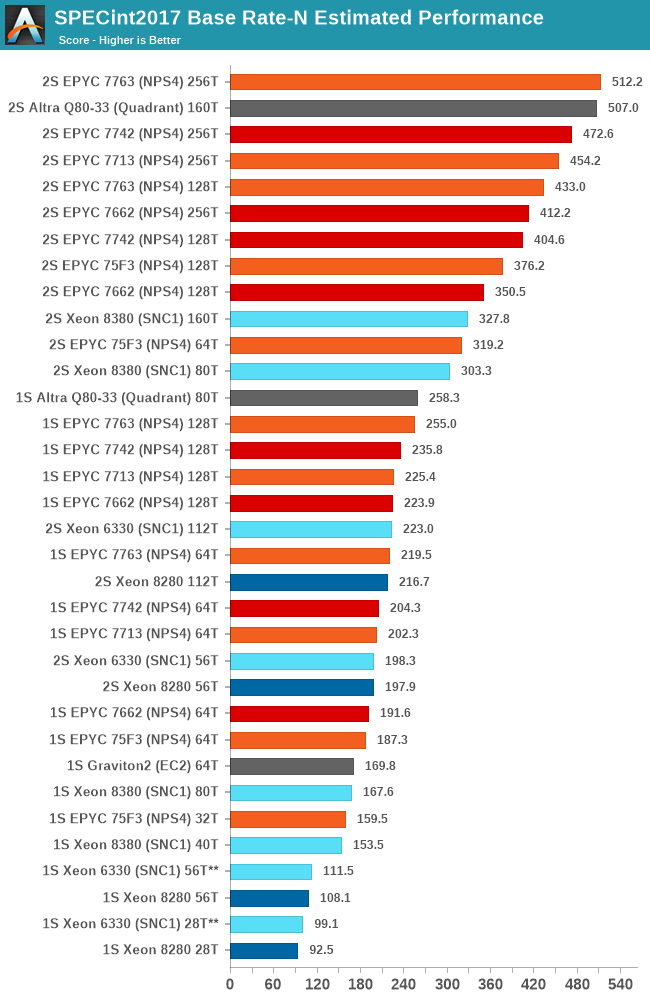
In the aggregate geomean scores, we’re seeing again that the new Xeon 8380 allows Intel to significantly reposition itself in the performance charts. Unfortunately, this is only enough to match the lower core count SKUs from the competition, as AMD and Ampere are still well ahead by massive leads – although admittedly the gap isn’t as embarrassing as it was before.
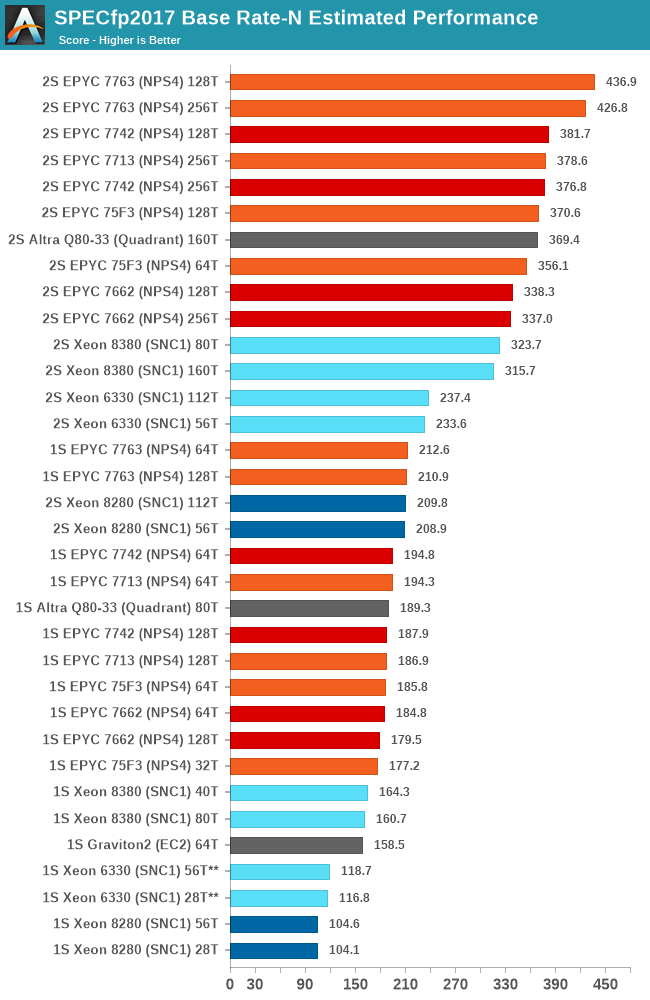
In the floating-point suite, the results are a bit more in favour for the Xeon 8380 compared to the integer suite, as the memory performance is weighed more into the total contribution of the total performance. It’s still not enough to beat the AMD and Ampere parts, but it’s much more competitive than it was before.
The Xeon 6330 is showcasing minor performance improvements over the 8280 and its cheaper equivalent the 6258R, but at least comes at half the cost – so while performance isn’t very impressive, the performance / $ might be more competitive.

Our performance results match Intel’s own marketing materials when it comes to the generational gains, actually even surpassing Intel’s figures by a few percent.
If you would be looking at Intel’s slide above, you could be extremely enthusiastic about Intel’s new generation, as indeed the performance improvements are extremely large compared to a Cascade Lake system.
As impressive as those generational numbers are, they really only help to somewhat narrow the Grand Canyon sized competitive performance gap we’ve had to date, and the 40-core Xeon 8380 still loses out to a 32-core Milan, and from a performance / price comparison, even a premium 75F3 costs 40% less than the Xeon 8380. Lower SKUs in the Ice Lake line-up would probably fare better in perf/$, however would also just lower the performance to an even worse competitive positioning.








169 Comments
View All Comments
Drazick - Wednesday, April 7, 2021 - link
The ICC compiler has much better vectorization engine than the one in GCC. It will usually generate better vectorized code. Especially numerical code.But the real benefit of ICC is its companion libraries: VSML, MKL, IPP.
Oxford Guy - Wednesday, April 7, 2021 - link
I remember that custom builds of Blender done with ICC scored better on Piledriver as well as on Intel hardware. So, even an architecture that was very different was faster with ICC.mode_13h - Thursday, April 8, 2021 - link
And when was this? Like 10 years ago? How do we know the point is still relevant?Oxford Guy - Sunday, April 11, 2021 - link
How do we know it isn't?Instead of whinge why not investigate the issue if you're actually interested?
Bottom line is that, just before the time of Zen's release, I tested three builds of Blender done with ICC and all were faster on both Intel and Piledriver (a very different architecture from Haswell).
I asked why the Blender team wasn't releasing its builds with ICC since performance was being left on the table but only heard vague suggestions about code stability.
Wilco1 - Sunday, April 11, 2021 - link
This thread has a similar comment about quality and support in ICC: https://twitter.com/andreif7/status/13808945639975...KurtL - Wednesday, April 7, 2021 - link
This is absolutely untrue. There is not much special about AOCC, it is just a AMD-packaged Clang/LLVM with few extras so it is not a SPEC compiler at all. Neither is it true for Intel. Sites that are concerned about getting the most performance out of their investments often use the Intel compilers. It is a very good compiler for any code with good potential for vectorization, and I have seen it do miracles on badly written code that no version of GCC could do.Wilco1 - Wednesday, April 7, 2021 - link
And those closed-source "extras" in AOCC magically improve the SPEC score compared to standard LLVM. How is it not a SPEC compiler just like ICC has been for decades?JoeDuarte - Wednesday, April 7, 2021 - link
It's strange to tell people who use the Intel compiler that it's not used much in the real world, as though that carries some substantive point.The Intel compiler has always been better than gcc in terms of the performance of compiled code. You asserted that that is no longer true, but I'm not clear on what evidence you're basing that on. ICC is moving to clang and LLVM, so we'll see what happens there. clang and gcc appear to be a wash at this point.
It's true that lots of open source Linux-world projects use gcc, but I wouldn't know the percentage. Those projects tend to be lazy or untrained when it comes to optimization. They hardly use any compiler flags relevant to performance, like those stipulating modern CPU baselines, or link time optimization / whole program optimization. Nor do they exploit SIMD and vectorization much, or PGO, or parallelization. So they leave a lot of performance on the table. More rigorous environments like HPC or just performance-aware teams are more likely to use ICC or at least lots of good flags and testing.
And yes, I would definitely support using optimized assembly in benchmarks, especially if it surfaced significant differences in CPU performance. And probably, if the workload was realistic or broadly applicable. Anything that's going to execute thousands, millions, or billions of times is worth optimizing. Inner loops are a common focus, so I don't know what you're objecting to there. Benchmarks should be about realizable optimal performance, and optimization in general should be a much bigger priority for serious software developers – today's software and OSes are absurdly slow, and in many cases desktop applications are slower in user-time than their late 1980s counterparts. Servers are also far too slow to do simple things like parse an HTTP request header.
pSupaNova - Wednesday, April 7, 2021 - link
"today's software and OSes are absurdly slow, and in many cases desktop applications are slower in user-time than their late 1980s counterparts." a late 1980's desktop could not even play a video let alone edit one, your average mid range smartphone is much more capable. My four year old can do basic computing with just her voice. People like you forget how far software and hardware has come.GeoffreyA - Wednesday, April 7, 2021 - link
Sure, computers and devices are far more capable these days, from a hardware point of view, but applications, relying too much on GUI frameworks and modern languages, are more sluggish today than, say, a bare Win32 application of yore.