Intel Core i7-11700K Review: Blasting Off with Rocket Lake
by Dr. Ian Cutress on March 5, 2021 4:30 PM EST- Posted in
- CPUs
- Intel
- 14nm
- Xe-LP
- Rocket Lake
- Cypress Cove
- i7-11700K
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
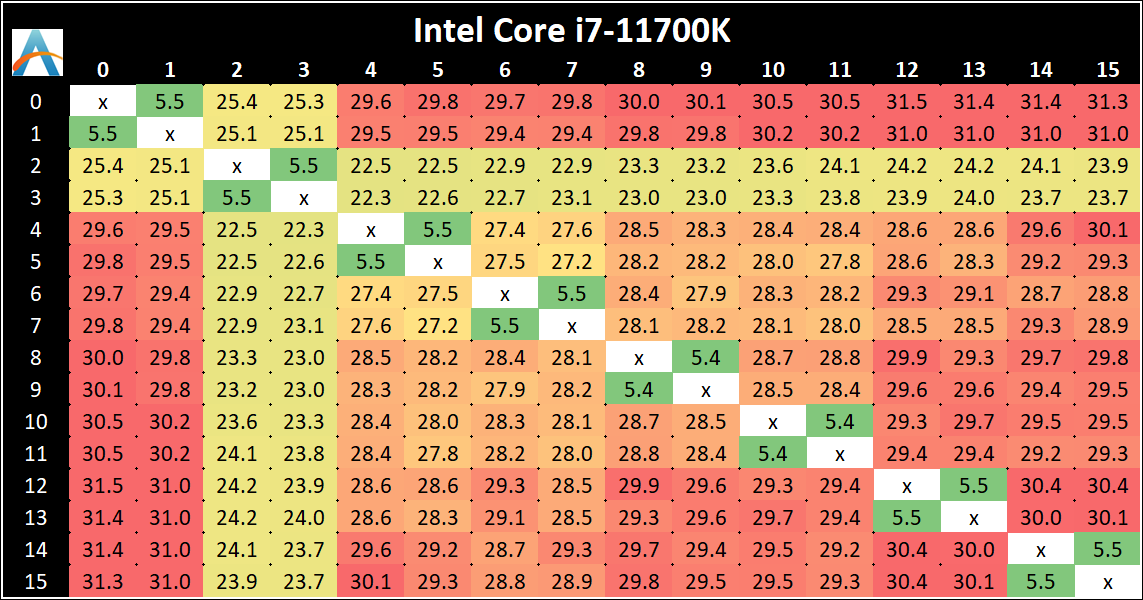
The core-to-core numbers are interesting, being worse (higher) than the previous generation across the board. Here we are seeing, mostly, 28-30 nanoseconds, compared to 18-24 nanoseconds with the 10700K. This is part of the L3 latency regression, as shown in our next tests.
One pair of threads here are very fast to access all cores, some 5 ns faster than any others, which again makes the layout more puzzling.
Update 1: With microcode 0x34, we saw no update to the core-to-core latencies.
Cache-to-DRAM Latency
This is another in-house test built by Andrei, which showcases the access latency at all the points in the cache hierarchy for a single core. We start at 2 KiB, and probe the latency all the way through to 256 MB, which for most CPUs sits inside the DRAM (before you start saying 64-core TR has 256 MB of L3, it’s only 16 MB per core, so at 20 MB you are in DRAM).
Part of this test helps us understand the range of latencies for accessing a given level of cache, but also the transition between the cache levels gives insight into how different parts of the cache microarchitecture work, such as TLBs. As CPU microarchitects look at interesting and novel ways to design caches upon caches inside caches, this basic test proves to be very valuable.
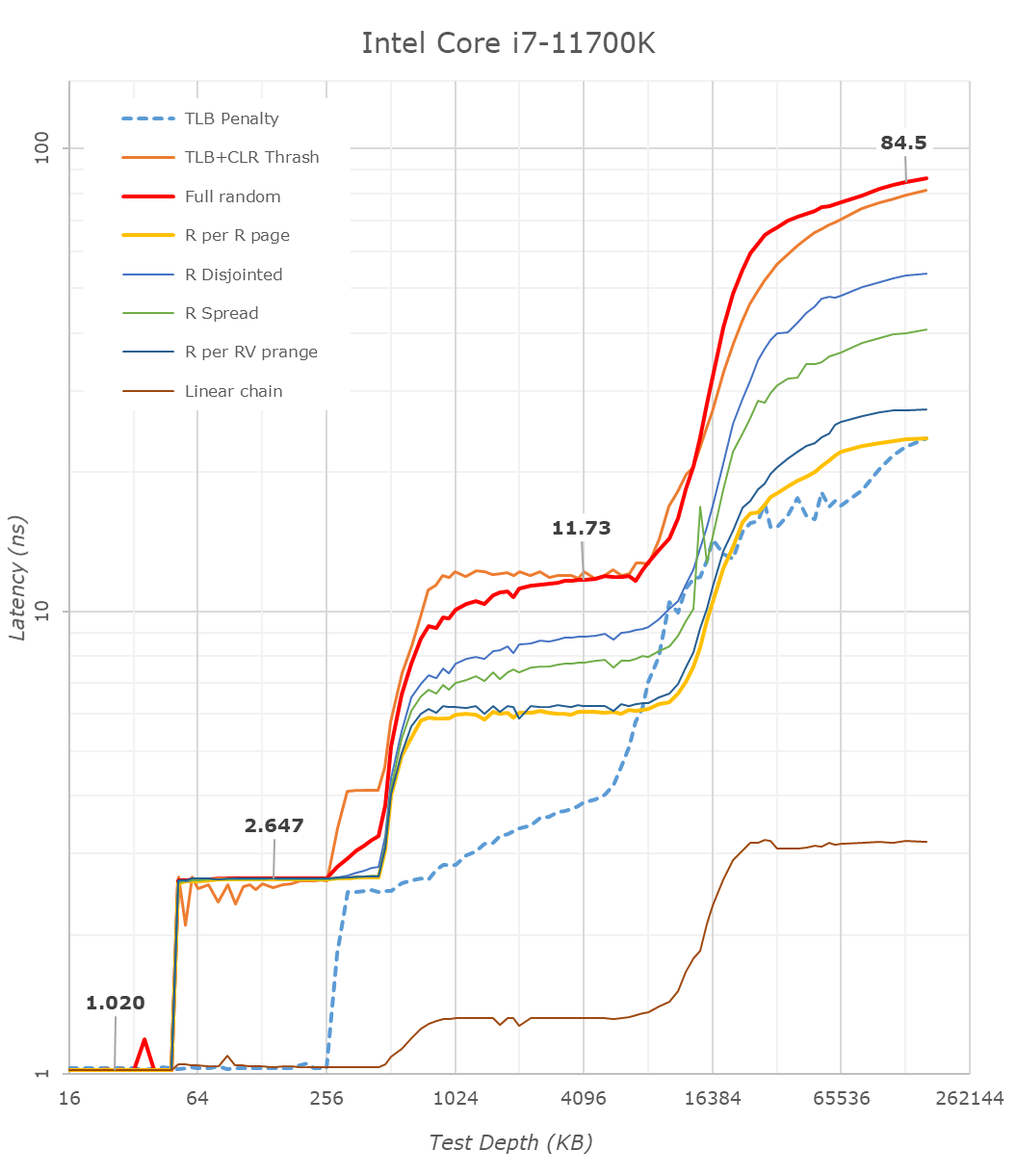
Looking at the rough graph of the 11700K and the general boundaries of the cache hierarchies, we again see the changes of the microarchitecture that had first debuted in Intel’s Sunny Cove cores, such as the move from an L1D cache from 32KB to 48KB, as well as the doubling of the L2 cache from 256KB to 512KB.
The L3 cache on these parts look to be unchanged from a capacity perspective, featuring the same 16MB which is shared amongst the 8 cores of the chip.
On the DRAM side of things, we’re not seeing much change, albeit there is a small 2.1ns generational regression at the full random 128MB measurement point. We’re using identical RAM sticks at the same timings between the measurements here.
It’s to be noted that these slight regressions are also found across the cache hierarchies, with the new CPU, although it’s clocked slightly higher here, shows worse absolute latency than its predecessor, it’s also to be noted that AMD’s newest Zen3 based designs showcase also lower latency across the board.
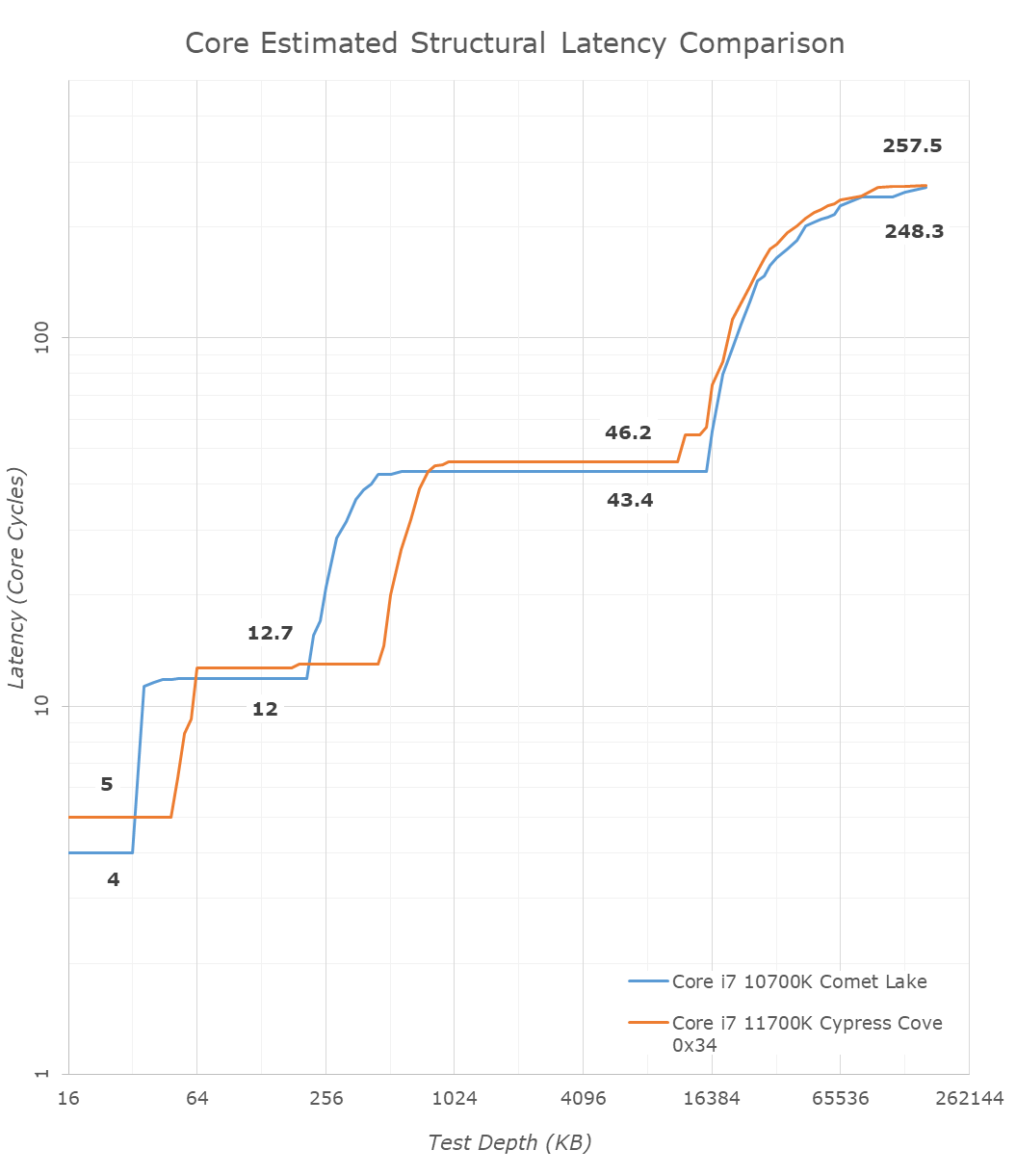
With the new graph of the Core i7-11700K with microcode 0x34, the same cache structures are observed, however we are seeing better performance with L3.
The L1 cache structure is the same, and the L2 is of a similar latency. In our previous test, the L3 latency was 50.9 cycles, but with the new microcode is now at 45.1 cycles, and is now more in line with the L3 cache on Comet Lake.
Out at DRAM, our 128 MB point reduced from 82.4 nanoseconds to 72.8 nanoseconds, which is a 12% reduction, but not the +40% reduction that other media outlets are reporting as we feel our tools are more accurate. Similarly, for DRAM bandwidth, we are seeing a +12% memory bandwidth increase between 0x2C and 0x34, not the +50% bandwidth others are claiming. (BIOS 0x1B however, was significantly lower than this, resulting in a +50% bandwidth increase from 0x1B to 0x34.)
In the previous edition of our article, we questioned the previous L3 cycle being a larger than estimated regression. With the updated microcode, the smaller difference is still a regression, but more in line with our expectations. We are waiting to hear back from Intel what differences in the microcode encouraged this change.
Frequency Ramping
Both AMD and Intel over the past few years have introduced features to their processors that speed up the time from when a CPU moves from idle into a high powered state. The effect of this means that users can get peak performance quicker, but the biggest knock-on effect for this is with battery life in mobile devices, especially if a system can turbo up quick and turbo down quick, ensuring that it stays in the lowest and most efficient power state for as long as possible.
Intel’s technology is called SpeedShift, although SpeedShift was not enabled until Skylake.
One of the issues though with this technology is that sometimes the adjustments in frequency can be so fast, software cannot detect them. If the frequency is changing on the order of microseconds, but your software is only probing frequency in milliseconds (or seconds), then quick changes will be missed. Not only that, as an observer probing the frequency, you could be affecting the actual turbo performance. When the CPU is changing frequency, it essentially has to pause all compute while it aligns the frequency rate of the whole core.
We wrote an extensive review analysis piece on this, called ‘Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics’, due to an issue where users were not observing the peak turbo speeds for AMD’s processors.
We got around the issue by making the frequency probing the workload causing the turbo. The software is able to detect frequency adjustments on a microsecond scale, so we can see how well a system can get to those boost frequencies. Our Frequency Ramp tool has already been in use in a number of reviews.
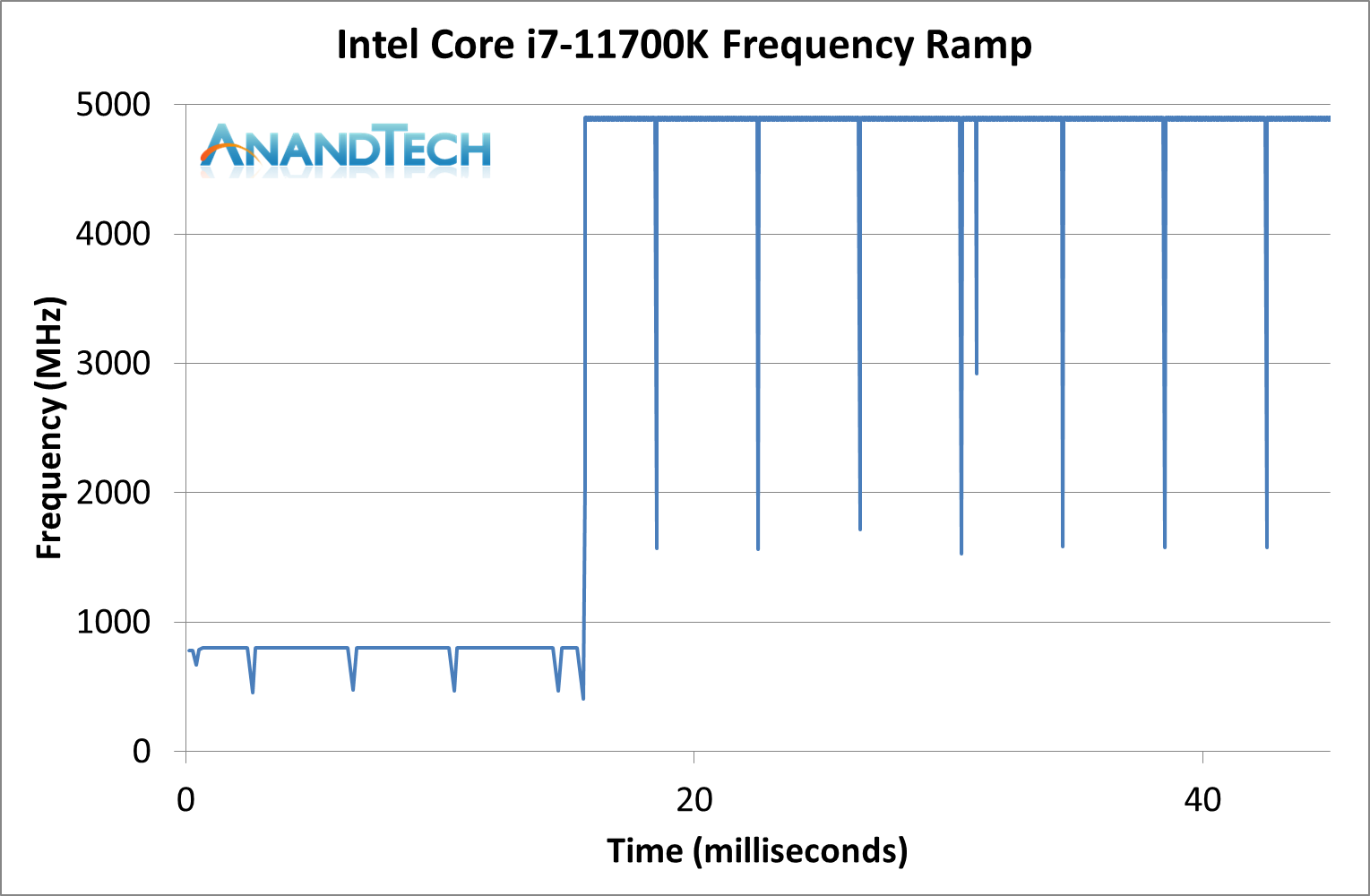
Our ramp test shows a jump straight from 800 MHz up to 4900 MHz in around 17 milliseconds, or a frame at 60 Hz.








541 Comments
View All Comments
brucethemoose - Monday, March 8, 2021 - link
1: AT benches on Windows, and right now x86 vs ARM is kinda Apples-to-oranges on that platform, especially when one starts mixing in emulation and AVX.Give it time. More comparisons will come. But you'll probably see comparisons on Linux/Mac, and open source software in general, sooner.
2: People uses CPUs for different things. Some of these benches are relevant to those people.
At the same time, my use cases weren't really covered here, so... I get what you're saying.
3. Yeah, it seems rather silly to me, especially when Anand test GPU limited AAA games.
Where you really need a big CPU is in simulation/sandbox games, especially in servers for such things, and sluggish early access stuff. But no one ever benches those :/
Silver5urfer - Monday, March 8, 2021 - link
So with the 19% IPC claim and losing to 9900KS and 10700K what is the point of releasing this chip, from Intel. I never got much from AT benches a lot and preferred the Hardware unboxed, Gamernexus guys and others. But if this is the final performance figures, then this is really a DOA product from Intel. How can they allow this ? I never saw Intel in such a position..maybe X299 got rekted when Zen 2 dropped but this is mainstream segment.Damn it. AMD processors have the idiotic stock related issues, add that WHEA and USB shitstorm. Intel has bullshit performance over past gen except a Gen4 addition and extra lanes from chipset. GPUs are out of damn stock as well.
2020 and 2021 both are completely fucked up for PC HW purchases.
Gigaplex - Monday, March 8, 2021 - link
"I never saw Intel in such a position.."The Pentium 4, in particular the Prescott architecture was a dud back in the early 2000's. That era spawned the antitrust lawsuit against Intel for illegally blocking AMD sales since the Intel products weren't competitive.
dwbogardus - Monday, March 8, 2021 - link
The fact that Intel can even remain in a close second place, using a 14 nm process is impressive. Imagine what they could do with TSMC's 7 nm process! It would almost certainly outperform AMD by a significant margin.Bagheera - Monday, March 8, 2021 - link
Really tired of Intel fanboys saying this.architectures are designed for specific nodes - RKL's problems are exactly due to porting an arch onto a node it wasn't designed for.
the fact is Intel is not a partner for TSMC and their archs are not designed for TSMC processes. if Intel were to outsource CPU production to TSMC, they will either have to make a new arch or make make tweaks to existing ones - a multi-million $ endeavor with risms of issues like your just read with RKL.
Hifihedgehog - Tuesday, March 9, 2021 - link
> a close second place^Here we see in his natural environment your common everyday dude who fails at reading comprehension. I guess you didn't read the part about the serious gaming performance losses and latency regressions gen-over-gen, the 10% performance gap in single-threaded or 10-20%+ performance gaps in multithread, or the inexcusably high peak power draw? Talk about deluded...
RanFodar - Monday, March 8, 2021 - link
Though their efforts may be futile, I am glad Intel attempted to do something out of the ordinary; not a Skylake refresh, but a backport that is found to have worse performance. And yet, it is an attempt for Intel to learn their lessons for generations to come.Hifihedgehog - Tuesday, March 9, 2021 - link
Backporting is not a lesson; it is a last ditch effort or a fallback when all else fails on the manufacturing side. Half full, half empty cup viewing aside, they wasted even more valuable engineering manhours into a failed backport when it should have been invested into developing new architectures. A best use would have been developing the next release. The problem is Intel had to make Rocket Lake good enough in synthetic benchmarks to appease their investors. That, however, still does not address the elephants in the room of 10-20% single threaded performance gaps or—the one that takes the cake—the latency regressions that makes gaming worse, Intel’s historic crown jewel. Much like movies that fail at release and live on box office bombs that their producers later opine should have been cut early on in development, Intel should have cut this idea early on. If you are looking for a lesson that Intel should have learned here, there it is: avoid another Rocket Lake backporting disaster and just warm over your current microarchitecture with one more middling refresh one last time.Hifihedgehog - Tuesday, March 9, 2021 - link
Ian, I just want to say thank you for the incredible review. Just ignore the haters on social media and in the comments who get their panties in a bunch. If the product is garbage, say it like it is, like you did and quite well I might add. You were incredibly diplomatic about it and even openly and honestly showed when and where Intel did win on the rare occasion in the benchmarks. It is so silly how people make these CPU companies (who don't know them from Sam Hill) their religion, as if erecting a Gordon Moore or Lisa Su shrine would avail them anything. Silly geese.misiu_mp - Wednesday, March 10, 2021 - link
Is that the new bulldozer?