AMD 3rd Gen EPYC Milan Review: A Peak vs Per Core Performance Balance
by Dr. Ian Cutress & Andrei Frumusanu on March 15, 2021 11:00 AM ESTDisclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
Compiling LLVM, NAMD Performance
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
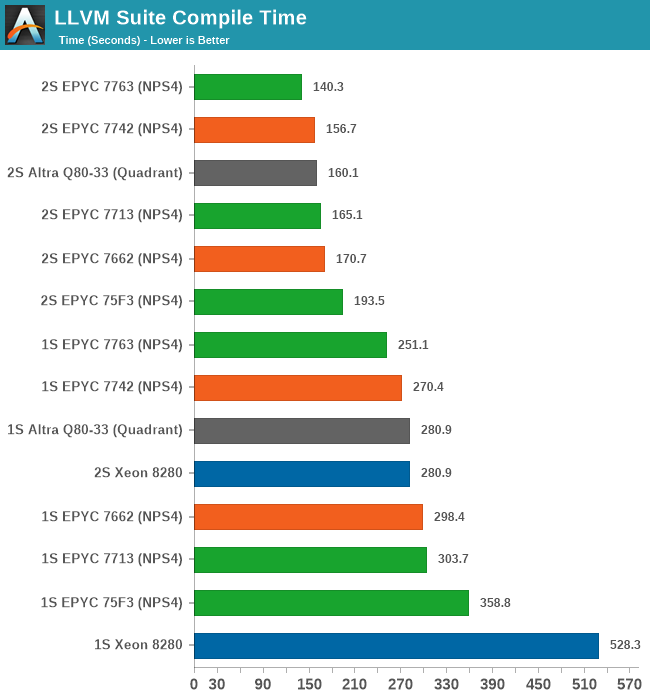
For the new Milan chips, the results are a bit mixed. The higher-power 7763 takes a lead with a +10.5% improvement over the 7742, however the 7713 doesn’t manage to keep up with that predecessor.
The 1S vs 2S scores are interesting as the 2S figures showcase the new Milan chips in a better light due to the higher single-threaded performance of the Zen3 cores. The compilation here also has linking phases which are single-thread performance bottle-necked. This results in scenarios such as the 7713 losing to the 7662 in 1S comparisons, however winning out against the same chip in the 2S comparison, as it’s able to make that advantage count for more.
It’s also great to see the 75F3 keep up with the 64-core counterparts at around 72% of the top-SKU performance.
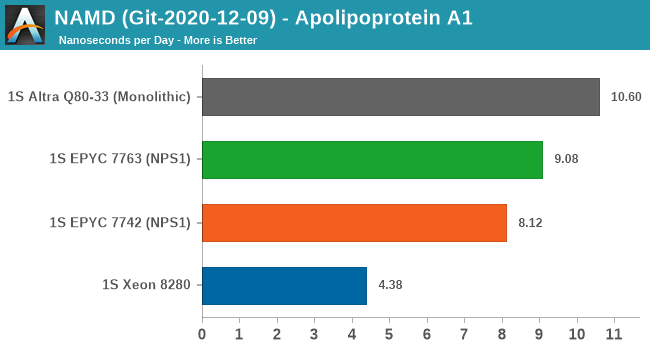
Finally, in NAMD, this is more of a core-local compute workload. We see the 7763 outperform the 7742 by +11.8%, however the Milan chip is still outperformed by the higher core compute capacity of the 80-core Altra chip.
Generally, I have my reservations about NAMD as a benchmark due to its multicore vs MPI variants and scaling anomalies, on top of the whole topic of the benchmark having a completely different algorithm for AVX512 processors.








120 Comments
View All Comments
mode_13h - Saturday, March 20, 2021 - link
Okay, thanks for confirming with them.mode_13h - Saturday, March 20, 2021 - link
It's not the easiest thing to confirm with a test, since you'd have to come along behind the writer and observe that a write that SHOULD still be in cache isn't.CBeddoe - Monday, March 15, 2021 - link
I'm excited by AMD's continuing design improvements.Can't wait to see what happens with the next node shrink. Intel has some catching up to do.
Ppietra - Tuesday, March 16, 2021 - link
Can someone please explain how is it possible that the power consumption of the all package is so much higher than the power consumption of the actual cores doing the work?Spunjji - Friday, March 19, 2021 - link
Because the I/O die is running on an older 14nm process and is servicing all of the cores. In a 64-core CPU, the per-core power use of the I/O die is less than 2W. Still too much, of course, but in context not as obscene as it looks when you look at the total power.Elstar - Tuesday, March 16, 2021 - link
Lest it go unsaid, I really appreciate the "compile a big C++ project" benchmark (i.e. LLVM). Thank you!Spunjji - Tuesday, March 16, 2021 - link
"To that end, all we have to compare Milan to is Intel’s Cascade Lake Xeon Scalable platform, which was the same platform we compared Rome to."Says it all, really. Good work AMD, and cheers to the team for the review!
Hifihedgehog - Tuesday, March 16, 2021 - link
Sysadmin: Ram? Rome?AMD: Milan, darling, Milan...
Ivan Argentinski - Tuesday, March 16, 2021 - link
Congrats for going more in-depth for the per-core performance! For many enterprise buyers, this is the most (only?) important metric. I do suspect, that in this regard, the 8 core 72F3 will actually be the best 3rd gen EPYC!But to better understand this, we need more test and per-core comparisons. I would suggest comparing:
* All current AMD fast/frequency optimized CPUs - EPYC 72F3, 73F3, ...
* Previous gen AMD fast/frequency CPUs like EPYC 7F32, ...
* Intel Frequency optimized CPUs like Xeon Gold 6250, 6244, ...
The only metric that matters is per-core performance under full *sustained* load.
Exploring the dynamic TDP of AMD EPYC 3rd gen is also an interesting option. For example, I am quite curious about configuring 72F3 with 200W instead of the default 180W.
Andrei Frumusanu - Saturday, March 20, 2021 - link
If we get more SKUs to test, I'll be sure to do so.