64 Cores of Rendering Madness: The AMD Threadripper Pro 3995WX Review
by Dr. Ian Cutress on February 9, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- Lenovo
- ThinkStation
- Threadripper Pro
- WRX80
- 3995WX
CPU Tests: Encoding
One of the interesting elements on modern processors is encoding performance. This covers two main areas: encryption/decryption for secure data transfer, and video transcoding from one video format to another.
In the encrypt/decrypt scenario, how data is transferred and by what mechanism is pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security.
Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
HandBrake 1.32: Link
Video transcoding (both encode and decode) is a hot topic in performance metrics as more and more content is being created. First consideration is the standard in which the video is encoded, which can be lossless or lossy, trade performance for file-size, trade quality for file-size, or all of the above can increase encoding rates to help accelerate decoding rates. Alongside Google's favorite codecs, VP9 and AV1, there are others that are prominent: H264, the older codec, is practically everywhere and is designed to be optimized for 1080p video, and HEVC (or H.265) that is aimed to provide the same quality as H264 but at a lower file-size (or better quality for the same size). HEVC is important as 4K is streamed over the air, meaning less bits need to be transferred for the same quality content. There are other codecs coming to market designed for specific use cases all the time.
Handbrake is a favored tool for transcoding, with the later versions using copious amounts of newer APIs to take advantage of co-processors, like GPUs. It is available on Windows via an interface or can be accessed through the command-line, with the latter making our testing easier, with a redirection operator for the console output.
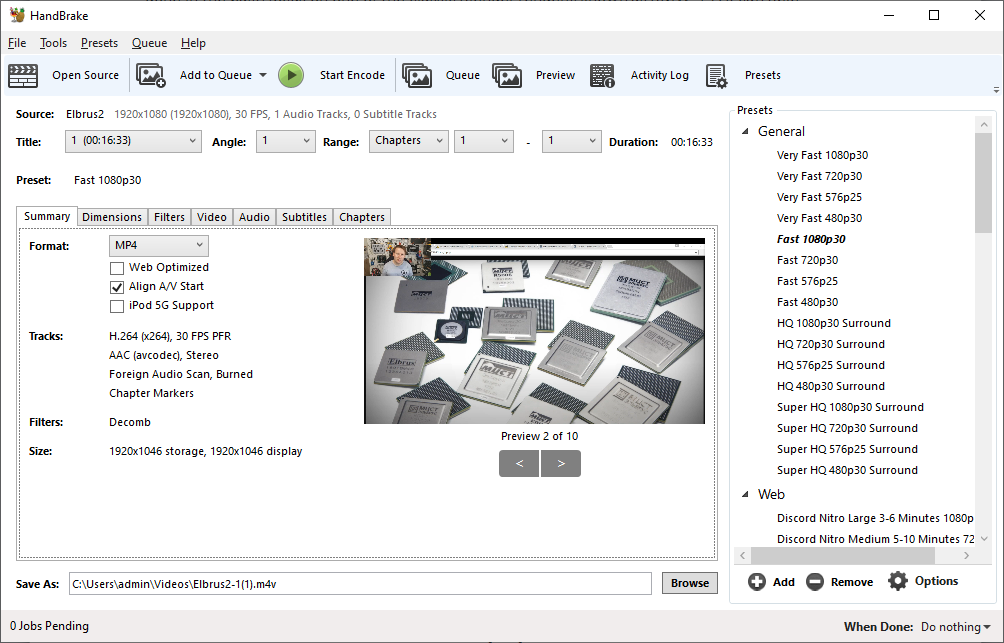
We take the compiled version of this 16-minute YouTube video about Russian CPUs at 1080p30 h264 and convert into three different files: (1) 480p30 ‘Discord’, (2) 720p30 ‘YouTube’, and (3) 4K60 HEVC.
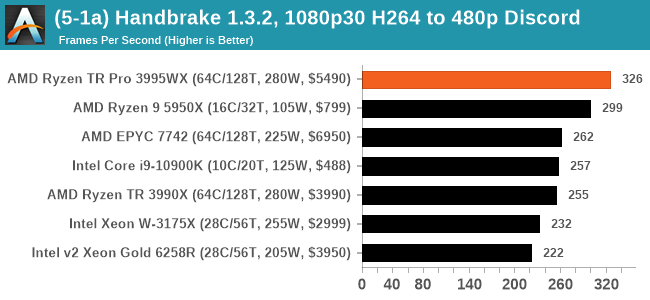
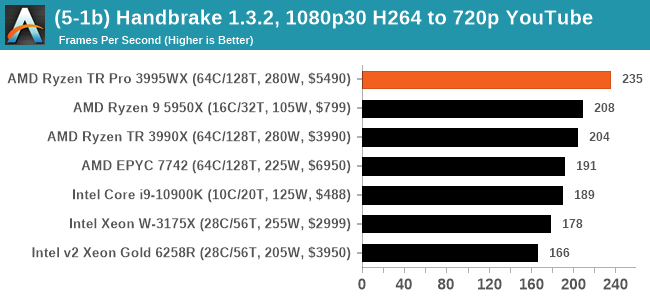

For the lower resolution modes, it would appear that the increased memory bandwidth plays a role for the 3995WX and 7742, although single core frequency also means a lot. Moving to the HEVC metrics, the Ryzen 9 takes a win here, but the 3995WX still goes above the 3990X.
7-Zip 1900: Link
The first compression benchmark tool we use is the open-source 7-zip, which typically offers good scaling across multiple cores. 7-zip is the compression tool most cited by readers as one they would rather see benchmarks on, and the program includes a built-in benchmark tool for both compression and decompression.
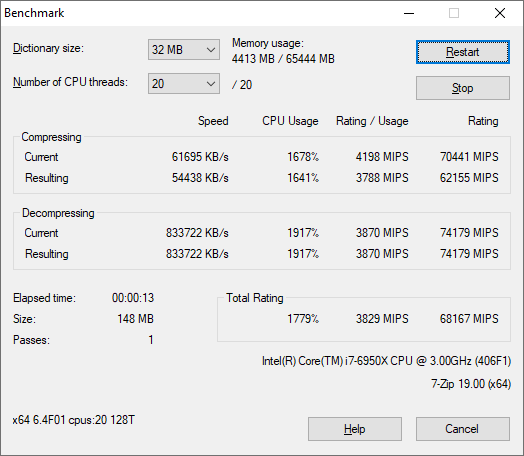
Example Test Run on an Intel 10-core i7-6950X
The tool can either be run from inside the software or through the command line. We take the latter route as it is easier to automate, obtain results, and put through our process. The command line flags available offer an option for repeated runs, and the output provides the average automatically through the console. We direct this output into a text file and regex the required values for compression, decompression, and a combined score.

This is a 16.6% win for the TR Pro 3995WX.
AES Encoding
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.

WinRAR 5.90: Link
For the 2020 test suite, we move to the latest version of WinRAR in our compression test. WinRAR in some quarters is more user friendly that 7-Zip, hence its inclusion. Rather than use a benchmark mode as we did with 7-Zip, here we take a set of files representative of a generic stack
- 33 video files , each 30 seconds, in 1.37 GB,
- 2834 smaller website files in 370 folders in 150 MB,
- 100 Beat Saber music tracks and input files, for 451 MB
This is a mixture of compressible and incompressible formats. The results shown are the time taken to encode the file. Due to DRAM caching, we run the test for 20 minutes times and take the average of the last five runs when the benchmark is in a steady state.
For automation, we use AHK’s internal timing tools from initiating the workload until the window closes signifying the end. This means the results are contained within AHK, with an average of the last 5 results being easy enough to calculate.

WinRAR is variable threaded, but the Xeon Gold takes the win here - even compared to the Xeon W-3175X. It's all relatively close at the top end.








118 Comments
View All Comments
avb122 - Tuesday, February 9, 2021 - link
Those cases do not matter unless you are checking that the result is the same as a golden reference. Otherwise the image it creates is just as if the object it was rendering moved 10 micrometers. To our brain it not doesn't matter.Being off by one bit with FP32 for geometry is about the same magnitude as modeling light as a partial instead of a wave. For color intensity, one bit of FP32 is less than one photon in real world cases.
But, CPUs and GPUs all get the same answer when doing the same FP32 arithmetic. The programmer can choose to do something else like use lossy texture compression or goofy rounding modes.
avb122 - Tuesday, February 9, 2021 - link
It's not because of the hardware. AMD and NVIDIA's GPUs have IEEE complient FPUs. So, they get the same answer as the CPU when using the same algorithm.With CUDA, the same C or C++ code doing computations can run on the CPU and GPU and get the same answer.
The REAL reasons to not use a GPU are that the non-compete parts (threading, memory management, synchronization, etc.) are different on the GPU and not all GPUs support CUDA. Those are very good reasons. But it is not about the hardware. It is about the software ecosystem.
Also GPUs do not have a tiny amount of cache. They have more total cache than a CPU. The ratio of "threads" to cache is lower. That requires changing the size of the block that each "thread" operates on. Ultimately, GPUs have so much more internal and external bandwidth than a CPU that only extreme cases where everything fits in the CPUs' L1 caches buy not in the GPU's register file can a CPU have more bandwidth.
Ian's statement about wanting 36 bits so that it can do 12-bit color is way off. I only know CUDA and NVIDIA's OpenGL. For those, each color channel is represented by a non-SIMD register. Each color channel is then either an FP16 or FP32 value (before neural networks GPUs were not faster at FP16, it was just for memory capacity and bandwidth). Both cover 12-bit color space. Remember, games have had HDR for almost two decades.
Dug - Tuesday, February 9, 2021 - link
It's software.But sometimes you don't want perfect. It can work in your benefit depending on what end results you view and interpret.
Smell This - Tuesday, February 9, 2021 - link
Page 4
Cinebench R20
Paragraph below the first image
**Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code bath. **
I do like my code clean ...
alpha754293 - Tuesday, February 9, 2021 - link
It's a pity that the processor and as a platform, you can buy a used dual EPYC 7702 server and still reap the multithreaded performance of 128-cores/256-threads moreso than you would be able to get out of this processor.I'd wished that this review actually included the results of a dual EPYC 7702/7742 system for the purposes of comparing the two, as I think that the dual EPYC 7702/7742 would still outperform this Threadripper Pro 3995WX.
Duncan Macdonald - Tuesday, February 9, 2021 - link
Given the benchmarks and the prices, the main reason for using the Threadripper Pro rather than the plain Threadripper is likely to be the higher memory capacity (2TB vs 256GB) .Even a small overclock on a standard Threadripper would allow it to be faster than a non-overclocked Threadripper Pro for any application that fits into 256GB.
twtech - Tuesday, February 9, 2021 - link
There are a couple other pretty significant differences that matter perf-wise in some scenarios - the Pro has 8-channel memory support, and more PCIE lanes.Significant differences not directly tied to performance include registered ECC support, and management tools for corporate security, which actually matters quite a bit with everyone working remotely.
WaltC - Tuesday, February 9, 2021 - link
On the whole, a nice review...;)Yes, it's fairly obvious that one CPU core does not equal one GPU core, as comparatively, the latter is wide and shallow and handles fewer instructions, IPC, etc. GPU cores are designed for a specific, narrow use case, whereas CPU cores are much deeper (in several ways) and designed for a much wider use case. It's nice that companies are designing programming languages to utilize GPUs as untapped computing resources, but the bottom line is that GPUs are designed primarily to accelerate 3d graphics and CPUs are designed for heavy, multi-use, multithreaded computation with a much deeper pipeline, etc. While it might make sense to use both GPUs and CPUs together in a more general computing case once the specific-case programming goals for each kind of processing hardware are reached, it makes no sense to use GPUs in place of CPUs or CPUs in place of GPUs. AMD has recently made no secret it is divulging its GPU line to provide more 3d-acceleration circuitry and less compute circuitry for gaming, and another branch that will include more CU circuitry and less gaming-use 3d-acceleration circuitry. 'bout time.
The software rendering of Crysis is a great example--an old, relatively slow 3d GPU accelerator with a CPU can bust the chops of even WX3995 CPUs *if* the 3995WX is tasked to rendering Crysis sans a 3d accelerator. When the Crysis-engine talks about how many cores and so on it will support, it's talking about using a 3d accelerator *with* a general-purpose CPU. That's what the engine is designed to do, actually. Take the CPU out and the engine won't run at all--trying to use the CPU as the API renderer and it's a crawl that no one wants...;) Most of all, using the CPU to "render" Crysis in software has no comparison to a CPU rendering a ray-traced scene, for instance. Whereas the CPU is rendering to a software D3d API in Crysis, ray-tracing is done by far more complex programming that will not be found in the Crysis engine (of course.)
I was surprised to read that Ian didn't think that 8-channel memory would add much of anything to performance beyond 4-channel support....;) Eh? It's the same principle as expecting 4-channel to outperform 2 channel, everything else being equal. Of course, it makes a difference--if it didn't there would be no sense in having 3995WX support 8 channels. No point at all...;)
Oxford Guy - Tuesday, February 9, 2021 - link
Yes, the same principle of expecting a dual core to outperform a single core — which is why single/core CPUs are still dominant.(Or, we could recognize that diminishing returns only begin to matter at a certain point.)
tyger11 - Tuesday, February 9, 2021 - link
Definitely waiting for the Zen 3 version of the 3955X. I'm fine with 16 cores.