AMD Zen 3 Ryzen Deep Dive Review: 5950X, 5900X, 5800X and 5600X Tested
by Dr. Ian Cutress on November 5, 2020 9:01 AM ESTSection by Andrei Frumusanu
The New Zen 3 Core: Front-End Updates
Moving on, let’s see what makes the Zen3 microarchitecture tick and how detail on how it actually improves things compared to its predecessor design, starting off with the front-end of the core which includes branch prediction, decode, the OP-cache path and instruction cache, and the dispatch stage.
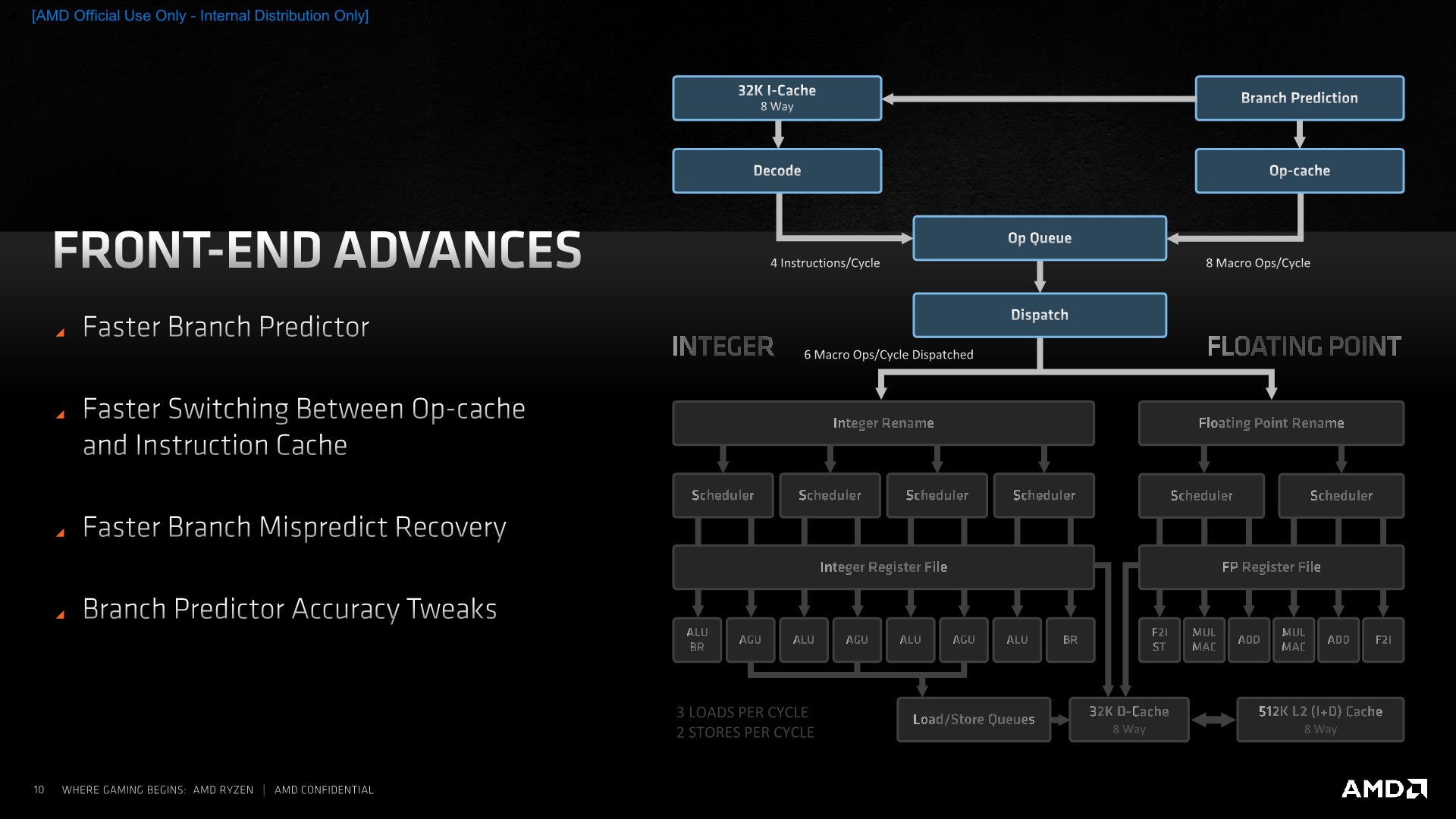
From a high-level overview, Zen3’s front-end looks the same as on Zen2, at least from a block-diagram perspective. The fundamental building blocks are the same, starting off with the branch-predictor unit which AMD calls state-of-the-art. This feeds into a 32KB instruction cache which forwards instructions into a 4-wide decode block. We’re still maintaining a two-way flow into the OP-queue, as when we see instructions again which have been previously decoded, they are then stored in the OP-cache from which they can be retrieved with a greater bandwidth (8 Mops/cycle) and with less power consumption.
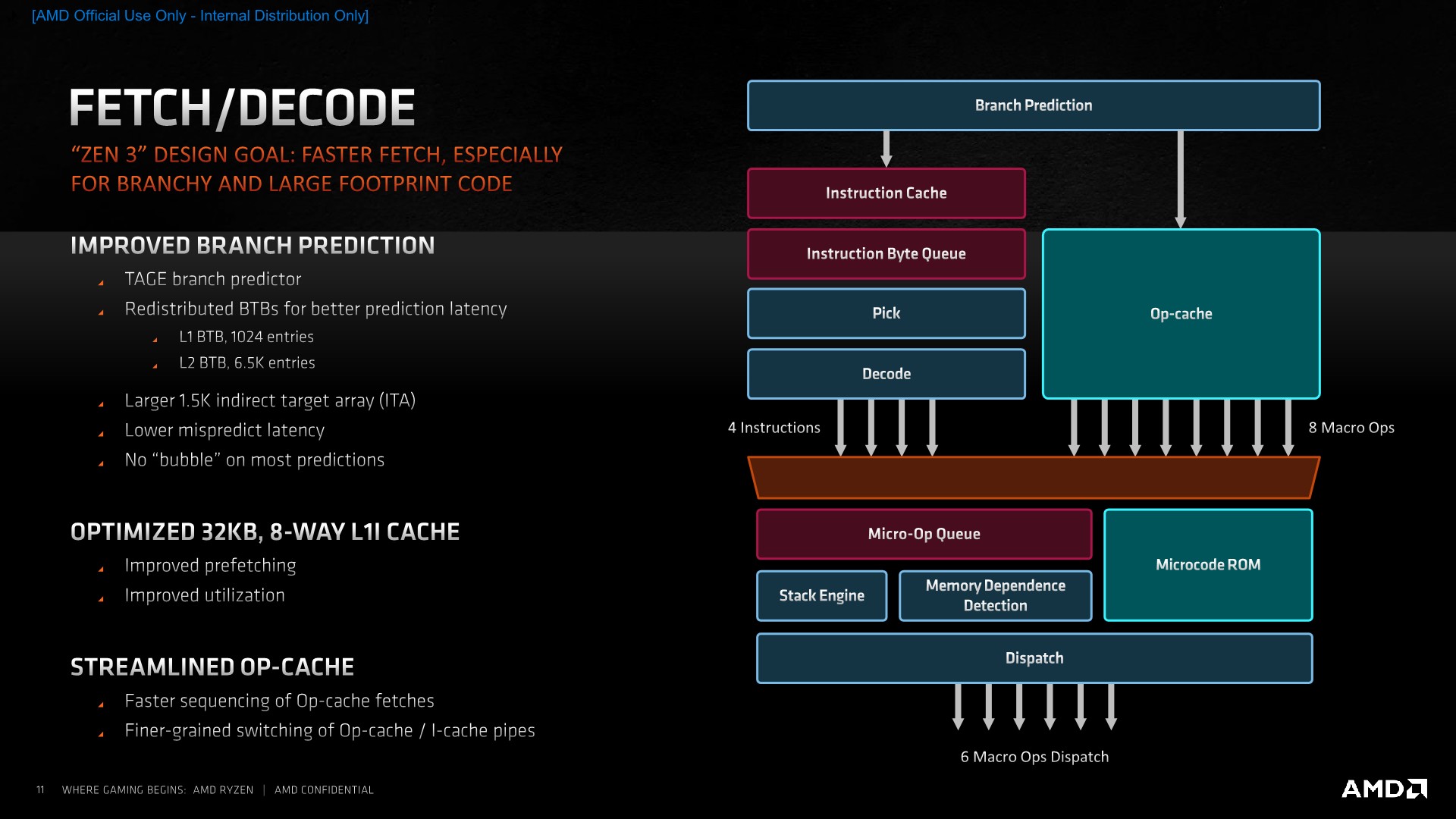
Improvements of the Zen3 cores in the actual blocks here include a faster branch predictor which is able to predict more branches per cycle. AMD wouldn’t exactly detail what this means but we suspect that this could allude to now two branch predictions per cycle instead of just one. This is still a TAGE based design as had been introduced in Zen2, and AMD does say that it has been able to improve the accuracy of the predictor.
Amongst the branch unit structure changes, we’ve seen a rebalancing of the BTBs, with the L1 BTB now doubling in size from 512 to 1024 entries. The L2 BTB has seen a slight reduction from 7K to 6.5K entries, but allowed the structure to be more efficient. The indirect target array (ITA) has also seen a more substantial increase from 1024 to 1536 entries.
If there is a misprediction, the new design reduces the cycle latency required to get a new stream going. AMD wouldn’t exactly detail the exact absolute misprediction cycles or how faster it is in this generation, but it would be a more significant performance boost to the overall design if the misprediction penalty is indeed reduced this generation.
AMD claims no bubbles on most predictions due to the increased branch predictor bandwidth, here I can see parallels to what Arm had introduced with the Cortex-A77, where a similar doubled-up branch predictor bandwidth would be able to run ahead of subsequent pipelines stages and thus fill bubble gaps ahead of them hitting the execution stages and potentially stalling the core.
On the side of the instruction cache, we didn’t see a change in the size of the structure as it’s still a 32KB 8-way block, however AMD has improved its utilisation. Prefetchers are now said to be more efficient and aggressive in actually pulling data out of the L2 ahead of them being used in the L1. We don’t know exactly what kind of pattern AMD alludes to having improved here, but if the L1I behaves the same as the L1D, then adjacent cache lines would then be pulled into the L1I here as well. The part of having a better utilisation wasn’t clear in terms of details and AMD wasn’t willing to divulge more, but we suspect a new cache line replacement policy to be a key aspect of this new improvement.
Being an x86 core, one of the difficulties of the ISA is the fact that instructions are of a variable length with encoding varying from 1 byte to 15 bytes. This has been legacy side-effect of the continuous extensions to the instruction set over the decades, and as modern CPU microarchitectures become wider in their execution throughput, it had become an issue for architects to design efficient wide decoders. For Zen3, AMD opted to remain with a 4-wide design, as going wider would have meant additional pipeline cycles which would have reduced the performance of the whole design.
Bypassing the decode stage through a structure such as the Op-cache is nowadays the preferred method to solve this issue, with the first-generation Zen microarchitecture being the first AMD design to implement such a block. However, such a design also brings problems, such as one set of instructions residing in the instruction cache, and its target residing in the OP-cache, again whose target might again be found in the instruction cache. AMD found this to be a quite large inefficiency in Zen2, and thus evolved the design to better handle instruction flows from both the I-cache and the OP-cache and to deliver them into the µOP-queue. AMD’s researchers seem to have published a more in-depth paper addressing the improvements.
On the dispatch side, Zen3 remains a 6-wide machine, emitting up to 6-Macro-Ops per cycle to the execution units, meaning that the maximum IPC of the core remains at 6. The Op-cache being able to deliver 8 Macro-Ops into the µOp-queue would serve as a mechanism to further reduce pipeline bubbles in the front-end – as the full 8-wide width of that structure wouldn’t be hit at all times.
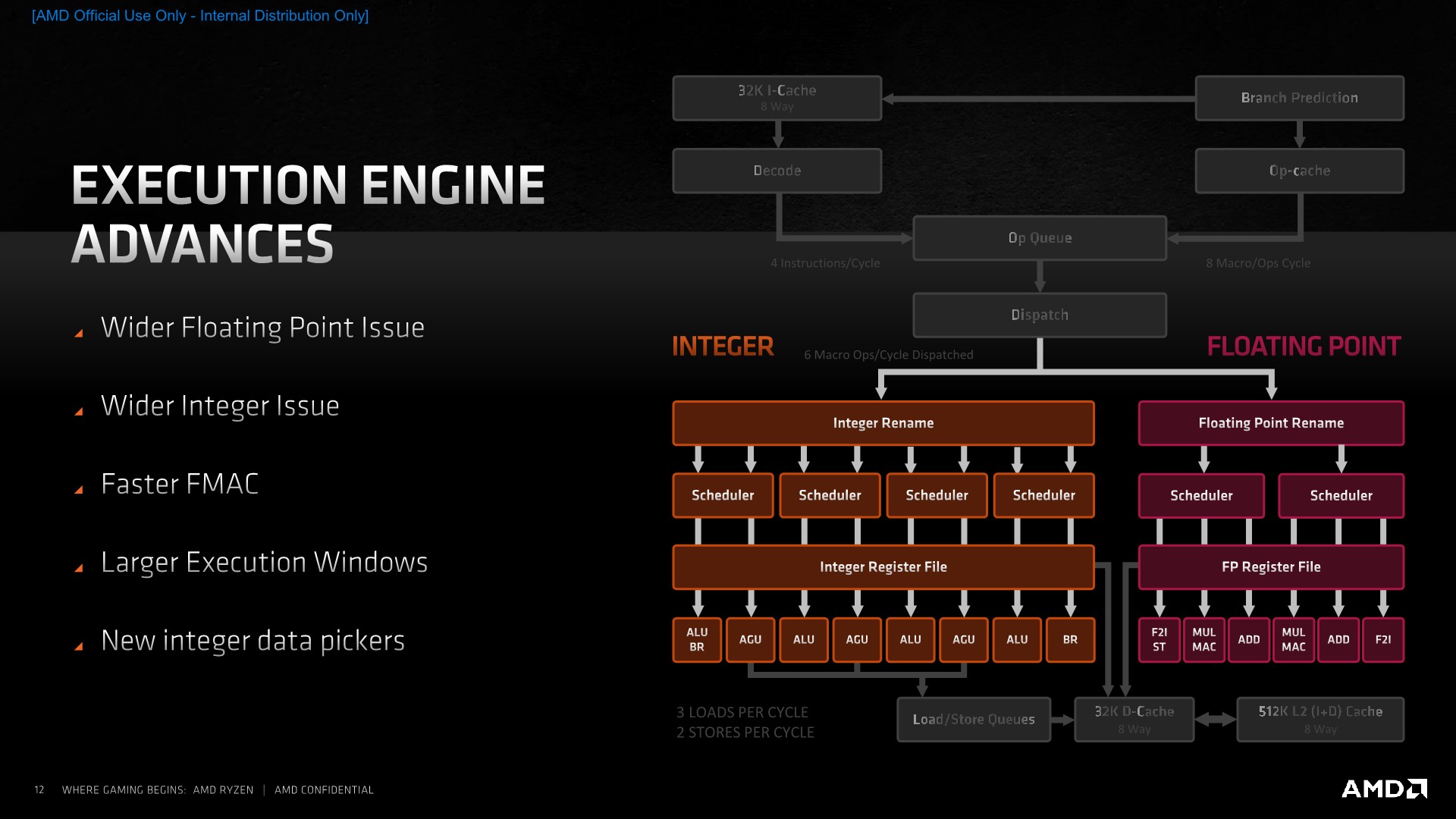
On the execution engine side of things, we’ve seen a larger overhaul of the design as the Zen3 core has seen a widening of both the integer and floating-point issue width, with larger execution windows and lower latency execution units.
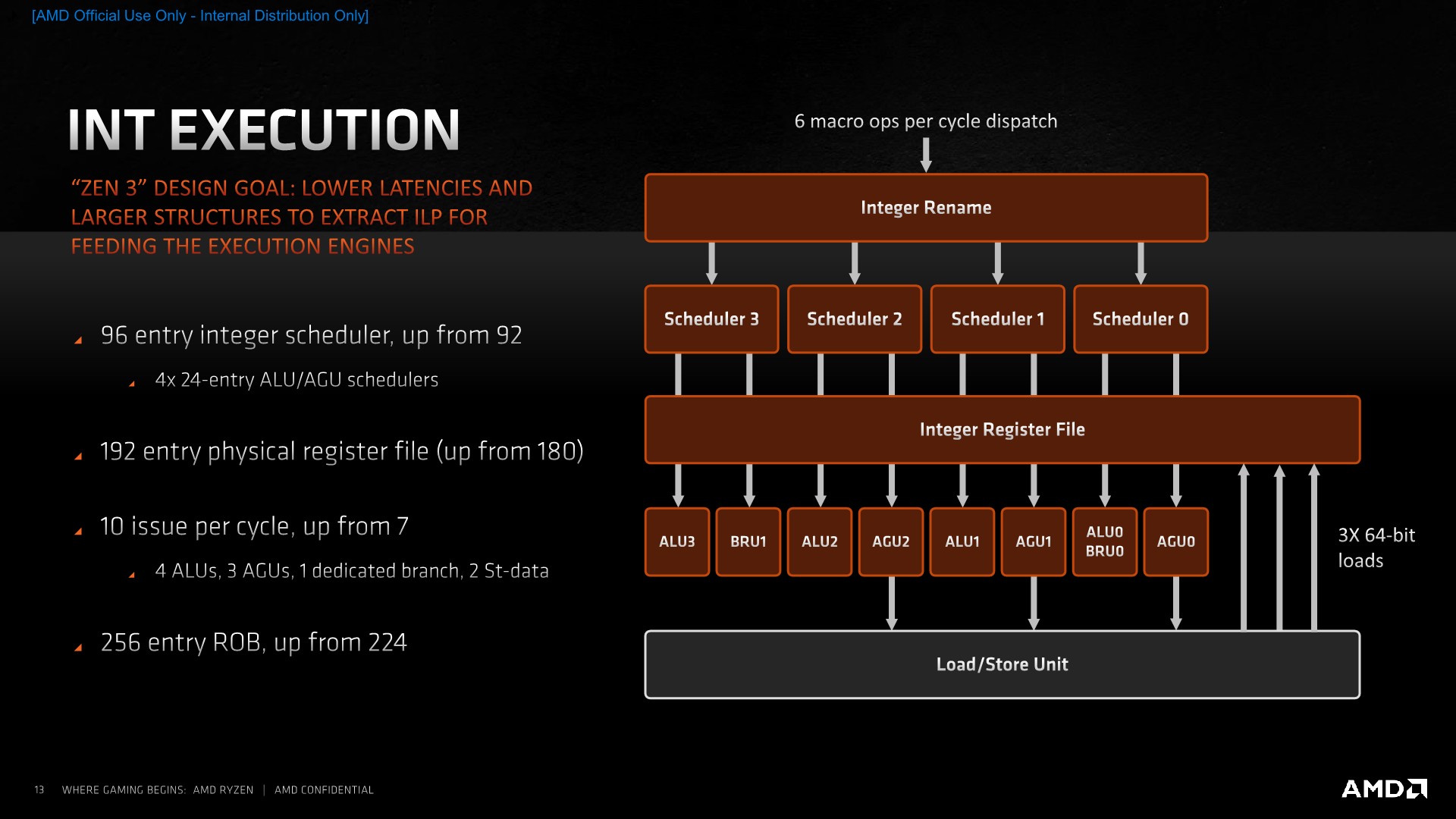

Starting off in more detail on the integer side, the one larger change in the design has been a move from individual schedulers for each of the execution units to a more consolidated design of four schedulers issuing into two execution units each. These new 24-entry schedulers should be more power efficient than having separate smaller schedulers, and the entry capacity also grows slightly from 92 to 96.
The physical register file has seen a slight increase from 180 entries to 192 entries, allowing for a slight increase in the integer OOO-window, with the actual reorder-buffer of the core growing from 224 instructions to 256 instructions, which in the context of competing microarchitectures such as Intel’s 352 ROB in Sunny Cove or Apple giant ROB still seems relatively small.
The overall integer execution unit issue width has grown from 7 to 10. The breakdown here is that while the core still has 4 ALUs, we’ve now seen one of the branch ports separate into its own dedicated unit, whilst the other unit still shares the same port as one of the ALUs, allowing for the unshared ALU to dedicate itself more to actual arithmetic instructions. Not depicted here is an additional store unit, as well as a third load unit, which is what brings us to 10 issue units in total on the integer side.
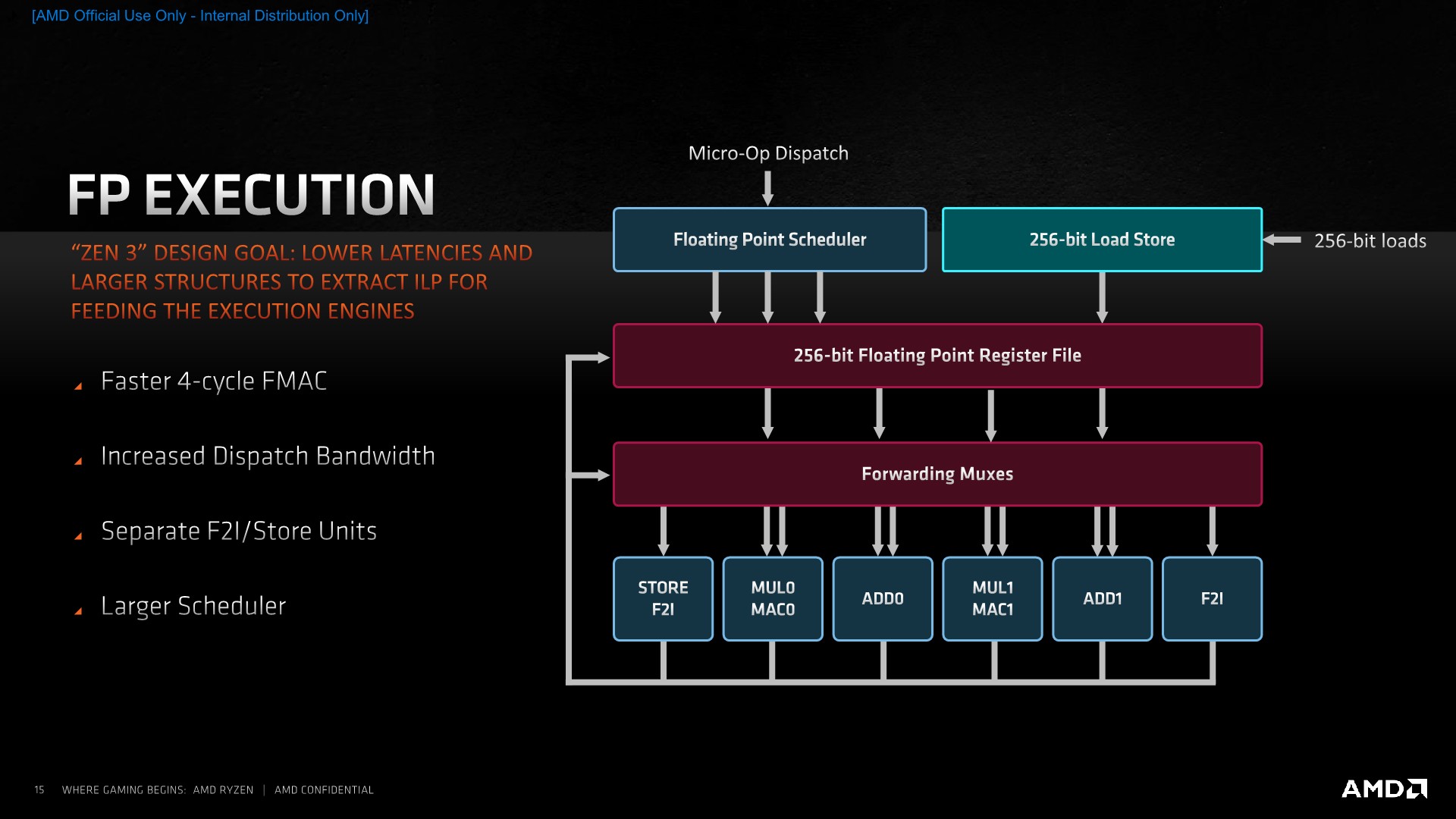
On the floating-point side, the dispatch width has been increased from 4 µOps to 6 µOps. Similar to the integer pipelines, AMD has opted to disaggregate some of the pipelines capabilities, such as moving the floating point store and floating-point-to-integer conversion units into their own dedicated ports and units, so that the main execution pipelines are able to see higher utilisation with actual compute instructions.
One of the bigger improvements in the instruction latencies has been the shaving off of a cycle from 5 to 4 for fused multiply accumulate operations (FMAC). The scheduler on the FP side has also seen an increase in order to handle more in-flight instructions as loads on the integer side are fetching the required operands, although AMD here doesn’t disclose the exact increases.








339 Comments
View All Comments
Luminar - Thursday, November 5, 2020 - link
Cache Rules Everything Around MeSIDtech - Thursday, November 5, 2020 - link
Hi Andrei,Excellent work. Do you know how this performance shapes up against the Cortex A77 ?
t.s - Friday, November 6, 2020 - link
Seconded. Want to know how the likes of ryzen 4 4350G or 5600 versus Cortex A77 or A78.Kangal - Saturday, November 7, 2020 - link
It's hard to say, because it really depends on the instruction/software as it is very situational. It also depends on the type of device it is powering, you can move up from Phones, to Thin Tablets, to Thick Laptops, to Large Desktops, and upto a Server. Each device offers different thermal constraints.The lower-thermal devices will favour the ARM chip, the mid-level will favour AMD, and the higher-thermal devices will favour Intel. That WAS the rule of thumb. In general, you could say Intel's SkyLake has the single-threaded performance crown, then AMD's Zen+ loses to it by a notable margin but beats it in multi-threaded tasks, and then going to an ARM Cortex A76 will have the lowest single-thread but the highest multi-threaded performance.
Now?
Well, there's the newly launched 2021 AMD Zen3 processor. And the upcoming 2021 ARM Cortex-X Overclocked Big-core using the new A78 microarchitecture. Lastly there's the 2022 Intel Rocket Lake yet to debut. So it's too early to tell, we can only make inferences.
Kangal - Saturday, November 7, 2020 - link
Here is my personal (yet amateur) take on the future 2020-2022 standpoints between the three racers. Firstly I'll explain what the different keywords and attributes mean(from most technical to most real-world implication)
Total efficiency: (think Full Server / Tractor) how much total calculations versus total power draw
Multi-threaded: (think Large Desktop / Truck) how much total calculations
Single-threaded: (think Thick Laptop / Car) how much priority calculations
IPC performance: (think Thin Tablet / Motorbike) how much priority calculations at desirable frequency/voltage/power-draw
*Emulating:
Having a "simple" ARM chip running "complex" x86 instructions. Such as running 32bit or 64bit OS X or Windows programs, via new techniques of emulation using a partial-hardware and hybrid-software solutions. I think the hit to efficiency will be around x3, instead of the expected x12 degradation.
So here are the lists (from most technical to most real-world implication)
Simple Code > Mixed code > Recommended Solution
Here's how they stack up when running identical new code (ie Modern Apps):
Total efficiency: ARM >>>> AMD >> Intel
Multi-threaded: ARM > AMD > Intel
Single-threaded: Intel = AMD > ARM
IPC performance: ARM >>> AMD > Intel
Now what about them running legacy code (ie x86 Program):
Efficiency + *emulating: AMD > Intel >> ARM
Multi + *emulating: AMD > Intel >> ARM
1n + *emulating: Intel = AMD >>> ARM
IPC + *emulating: AMD > Intel > ARM
My recommendation?
Full Server: 60% legacy 40% new code. This makes ARM the best option by a small margin.
Large Desktop: 80% legacy 20% new code. AMD is the best option with modest margin.
Thick Laptop: 70% legacy 30% new code. Intel is the best. AMD is very close (tied?) second.
Thin Tablet: 10% legacy 90% new code. ARM is the best option by huge margin.
Tomatotech - Monday, November 9, 2020 - link
Excellent post, but worth pointing out that *all* modern chips now emulate x86 and x64 code. They run a front end that takes x86 / x64 machine code then convert that into RISC code and that goes through various microcode and translation layers before being processed by the backend. That black box structure has allowed swapping out and optimising the back end for decades while maintaining code compatibility on the front end.So it’s not as simple to differentiate between the various chips as you make it out to be.
Gondalf - Sunday, November 8, 2020 - link
I don't know. Looking Spec results, we can say Anandtech is absolutely unable to set a Spec session correctly. From the review Zen 2 is slower per Ghz than old Skylake in integer, that is absolutely wrong in consumer cores (in server cores yes), even worse Ice Lake core is around fast as old Skylake per GHz.Basically this review is rushed and very likely they have set all AMD compiler flags on "fast" to do more contacts and a lot of hipe.
My God, for Anandtech Zen 3 is 35% faster in the global Spec values than Zen 2. Not even AMD worst marketing slide say this. We have Zen 4 here not Zen 3. Wait wait please.
A really crap review, the author need to go back to school about Spec.
Obviously the article do not say that 28W Tiger Lake is unable to run at 4.8Ghz for more than a couple of seconds, after this it throttes down, so the same Willow Cove core on a desktop Cpu could destroy Zen 3 without mercy on a CB session. Not to mention the far slower memory subsystem of a mobile cpu.
Basically looking at games results, Rocket Lake will eclipse this core forever. AMD have nothing of new in its hands, they need to wait Zen 4
Qasar - Sunday, November 8, 2020 - link
yea ok gondalf, trying to find ways that your beloved intel doesnt lose at everything now ??accept it, amd is faster then intel across the board.
Spunjji - Monday, November 9, 2020 - link
That's a strange claim about Tiger Lake performance, Gondalf, because I seem to recall Intel seeding all the reviewers with a laptop that could run TGL at 4.8Ghz boost 'til the cows come home - and that's what Anandtech used to get that number. It's literally the best they can do right now. You're right of course - in actual shipping ultrabooks, TGL is a hot PoS that cannot maintain its boost clocks. Maybe by 2022 they'll finally put Willow Cove into a shipping desktop CPU."Basically looking at games results, Rocket Lake will eclipse this core forever"
If by "eclipse" you mean gain a maximum 5% advantage at higher clock speeds and nearly double the power draw then sure, "eclipse", yeah. 🤭
I love your posts here. Please, never stop stepping on rakes like Sideshow Bob.
macroboy - Saturday, December 12, 2020 - link
LOL look at AMD's Efficiency and sustained core clocks, Intel runs too hot to stay at 5ghz for very long. meanwhile Zen3 plows along at 55C no problem, *you're the one who needs to check your facts.