AMD Zen 3 Ryzen Deep Dive Review: 5950X, 5900X, 5800X and 5600X Tested
by Dr. Ian Cutress on November 5, 2020 9:01 AM ESTConclusion: AMD Has Ryzen To The Top
Coming out the other end of this review, it’s hard to believe the extent to which some of AMD’s performance numbers have grown in the last five years. Even within the Ryzen family, we can pinpoint the leaps and bounds by which AMD is now the market leader in pure x86 performance.
Let’s start with some headline numbers.
+19% IPC Gain Confirmed
AMD quoted to us a raw IPC gain from Zen2 to Zen3 of +19%. AMD measured this with 25 workloads and both processors at 4.0 GHz, running DDR4-3600 memory. By comparison, we test with industry standard benchmarks at rated clock speeds and JEDEC supported memory, and we were able to accurately achieve that +19% number.
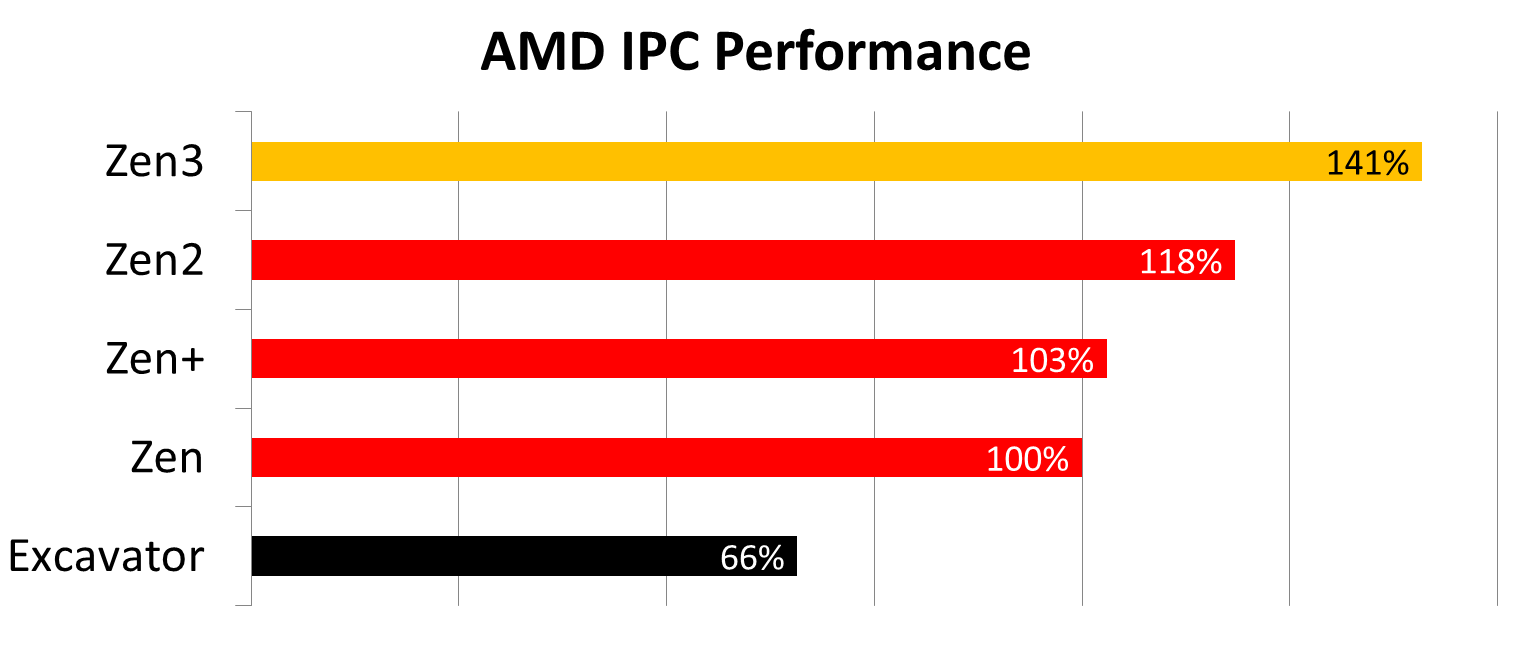
Compounding the generation-on-generation gains from a pre-Ryzen era, we’re seeing +114% IPC improvements, and if we look from the original Zen to Zen3, it is a ~41% gain.
In real world benchmarks, we saw an average +24% performance gain, showcasing both the increase in IPC and frequency uplift that the Ryzen 5000 parts have.
5.0 GHz Achieved on Ryzen
Turbo frequencies are often setup dependent, and because AMD uses a combination of listed turbo frequency and opportunistic boosting, the exact turbo frequency can be hard to nail down. For the top-tier Ryzen 9 5950X, AMD lists the turbo frequency as 4900 MHz for single core loading, however in very standard conditions, we were able to pass that to 5050 MHz. Diving deeper into the AGESA, this processor actually has a ‘maximum frequency’ setting of 5025 MHz. All of our Ryzen 5000 series processors offered +50-150 MHz above the listed turbo showcasing that these parts still have some headroom.
As we note in the review, AMD could have listed a 5 GHz turbo frequency, and it would be a big win for the company. However, I feel the company (a) wants to focus more on the market leading performance and engineering which doesn’t need 5 GHz, and (b) if they listed 5 GHz, it would suddenly be the only messaging people would take from the product launch. By not listing an explicit 5 GHz, it also allows AMD room to maneuver for a future product.
New WRs in Cinebench 1T, Breaking 10K in nT
AMD currently loves presenting CineBench as a measure of performance (Intel seems to flip/flop on the issue, depending on its position), and one of the main launch announcements was breaking the 600 point barrier in single threaded performance. At the time, it stated that the top three parts could get this value, whereas the Ryzen 5 5600X was just slightly behind.
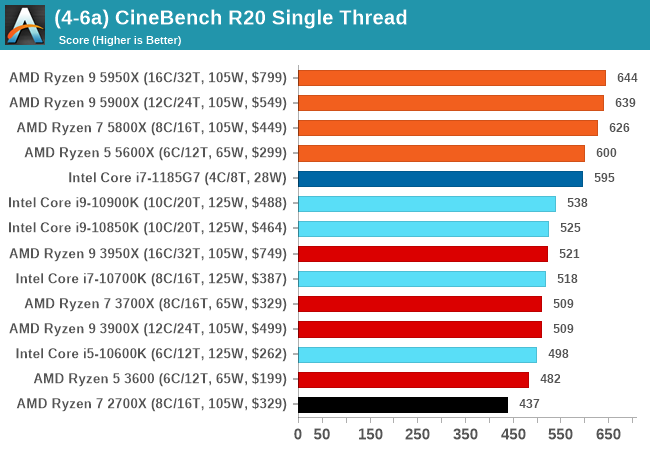
In our testing, we scored at least 600 on all processors. This is significant as Intel’s latest Tiger Lake processors, turbo-ing at 4.8 GHz with as much power as they can use, only scored 595. Users that want a Tiger Lake can’t find one in a desktop, whereas the base Ryzen 5 5600X is $300.
Another win worth mentioning here though not explicitly announced by AMD is breaking the 10000 point barrier with the Ryzen 9 5950X in the multithreaded test. We achieved it just by the skin of our teeth, and a good few hundred points above AMD’s ‘reviewer guide’ that accompanies every launch. The only other CPUs to get above this value are 205 W Xeons or Threadrippers, while AMD does it within the 142 W peak power window.
Gaming: Cache is Good, But Depends on the Title
Performance in gaming is always a bit harder to pin down performance numbers, depending on the titles, resolutions, graphics card used, memory and drivers. AMD came into Zen3 showcasing a +5-50% gain at 1080p High over Zen2 across a number of titles, averaging 20-25%, along with performance leadership comparing against Intel’s best performer.
We don’t test at 1080p High, however we do have two metrics worth comparing. We run our games with an RTX 2080 Ti.
At the purely CPU-limited scenario, at the lowest resolutions and the lowest quality, we saw a +44% average uplift going from Zen2 to Zen3, from +10% on the low end to +80% on the high-end.
At 1080p Maximum, we saw a +10% average uplift going from Zen2 to Zen3. This varied from benchmarks where the results were equal due to being GPU-limited, to some modest +36% gains in more CPU-limited tests.
When we compare AMD against Intel, AMD easily wins the CPU-limited lowest resolution tests from +2% to +52%, averaging around +21% higher FPS. In the 1080p Maximum however, AMD and Intel trade blows, swaying from -4% to +6% for AMD (except in our Civ6 test, which is a +43% win for AMD).
As we saw in our recent Broadwell re-review, having access to large amounts of lower latency cache seems to be a good way to increasing gaming performance. By moving from each core having access to 16 MB to 32 MB, along with raw IPC gains, AMD is showing some good uplift. On the competitive front, we’re seeing a more even battlefield between Intel and AMD as the settings are cranked up.
Overall Impressions of Zen 3 and Ryzen 5000
One of the exciting things about probing a new core is finding out all the little quirks and improvements that they don’t tell you about. It’s been interesting finding out how this core was put together, both from our findings and discussions AMD’s engineers.
Moving to an 8-core CCX for this generation was a no-brainer, with an easy up-tick in performance. However it is the changes in the execution units and load/store were a lot of the magic happens – increasing to peak 3 loads/cycle and 2 stores/cycle, splitting out some of the ALU/AGU work, finer grained transitions from decoder/op-cache to the micro-op queue, and pre-fetchers with more bandwidth all help to that. A lot of the instruction improvements, such as lower latency FMA and faster DIV/IDIV is going to scale well as we move into the enterprise and EPYC processors.
With AMD taking the performance crown in almost area it’s competing in, attention now comes to price. Having $300 as an entry level for this tier is going to sting a lot of users who would rather spend $200 or less – despite AMD having nine out of ten of Amazon’s best sellers, only two of those parts are $300 and up. There’s going to be an early adopters tax as well – one could argue that moving into Q1, when AMD is enabling 400-series motherboards, might be a better inception point for a lot of users.
Having said that, with Intel set to launch Rocket Lake at the end of Q1 next year with 8 cores, this sub-$300 market is going to be ripe for any AMD Zen3 APU to come in and take that price bracket. AMD never launched Zen2 APUs into the consumer market, which might indicate a fast follow-on with Zen3. Watch this space – a monolithic Zen3 APU is going to be exciting.
| AMD Ryzen 5000 Series Processors Zen 3 Microarchitecture |
||||||
| AnandTech | Cores Threads |
Base Freq |
Turbo Freq |
L3 Cache |
TDP | MSRP |
| Ryzen 9 5950X | 16c/32t | 3400 | 4900 | 64 MB | 105 W | $799 |
| Ryzen 9 5900X | 12c/24t | 3700 | 4800 | 64 MB | 105 W | $549 |
| Ryzen 7 5800X | 8c/16t | 3800 | 4700 | 32 MB | 105 W | $449 |
| Ryzen 5 5600X | 6c/12t | 3700 | 4600 | 32 MB | 65 W | $299* |
All things considered, we’re really impressed with what AMD has achieved here. After the disillusionment of years of weaker generation-on-generation performance uplifts from the competition, AMD set a goal to beat the average ~7% IPC year-on-year gain. With +19% IPC on Zen3, Intel has no equal right now - not even Tiger Lake at 4.8 GHz - and has lost that single-threaded crown.

Zen3 gets a gold award. No question.








339 Comments
View All Comments
TheinsanegamerN - Tuesday, November 10, 2020 - link
However AMD's boost algorithim is very temperature sensitive. Those coolers may work fine, but if they get to the 70C range you're losing max performance to higher temperatures.Andrew LB - Sunday, December 13, 2020 - link
Blah blah....Ryzen 5800x @ 3.6-4.7ghz : 219w and 82'c.
Ryzen 5800x @ 4.7ghz locked: 231w and 88'c.
Fractal Celsius+ S28 Prisma 280mm AIO CPU cooler at full fan and pump speed
https://www.kitguru.net/components/cpu/luke-hill/a...
If you actually set your voltages on Intel chips they stay cool. My i7-10700k @ 5.0ghz all-core locked never goes above 70'c.
Count Rushmore - Friday, November 6, 2020 - link
It took 3 days... finally the article load-up.AT seriously need to upgrade their server (or I need to stop using IE6).
name99 - Friday, November 6, 2020 - link
"AMD wouldn’t exactly detail what this means but we suspect that this could allude to now two branch predictions per cycle instead of just one"So imagine you have wide OoO CPU. How do you design fetch? The current state of the art (and presumably AMD have aspects of this, though perhaps not the *entire* package) goes as follows:
Instructions come as runs of sequential instructions separated by branches. At a branch you may HAVE to fetch instructions from a new address (think call, goto, return) or you may perhaps continue to the next address (think non-taken branch).
So an intermediate complexity fetch engine will bring in blobs of instructions, up to (say 6 or 8) with the run of instructions terminating at
- I've scooped up N or
- I've hit a branch or
- I've hit the end of a cache line.
Basically every cycle should consist of pulling in the longest run of instructions possible subject to the above rules.
The way really advanced fetch works is totally decoupled from the rest of the CPU. Every cycle the fetch engine predicts the next fetch address (from some hierarchy of : check the link stack, check the BTB, increment the PC), and fetches as much as possible from that address. These are stuck in a queue connected to decode, and ideally that queue would never run dry.
BUT: on average there is about a branch every 6 instructions.
Now supposed you want to sustain, let's say, 8-wide. That means that you might set N at 8, but most of the time you'll fetch 6 or so instructions because you'll bail out based on hitting a branch before you have a full 8 instructions in your scoop. So you're mostly unable to go beyond an IPC of 6, even if *everything* else is ideal.
BUT most branches are conditional. And good enough half of those are not taken. This means that if you can generate TWO branch predictions per cycle then much of the time the first branch will not be taken, can be ignored, and fetch can continue in a straight line past it. Big win! Half the time you can pull in only 6 instructions, but the other half you could pull in maybe 12 instructions. Basically, if you want to sustain 8 wide, you'd probably want to pull in at least 10 or 12 instructions under best case conditions, to help fill up the queue for the cases where you pull in less than 8 instructions (first branch is taken, or you reach the end of the cache line).
Now there are some technicalities here.
One is "how does fetch know where the branches are, to know when to stop fetching". This is usually done via pre-decode bits living in the I-cache, and set by a kinda decode when the line is first pulled into the I-cache. (I think x86 also does this, but I have no idea how. It's obviously much easier for a sane ISA like ARM, POWER, even z.)
Second, and more interesting, is that you're actually performing two DIFFERENT TYPES of prediction, which makes it somewhat easier from a bandwidth point of view. The prediction on the first branch is purely "taken/not taken", and all you care about is "not taken"; the prediction on the second branch is more sophisticated because if you predict taken you also have to predict the target, which means dealing BTB or link stack.
But you don't have to predict TWO DIFFERENT "next fetch addresses" per cycle, which makes it somewhat easier.
Note also that any CPU that uses two level branch prediction is, I think, already doing two branch prediction per cycle, even if it doesn't look like it. Think about it: how do you USE a large (but slow) second level pool of branch prediction information?
You run the async fetch engine primarily from the first level; and this gives a constant stream of "runs of instructions, separated by branches" with zero delay cycles between runs. Great, zero cycle branches, we all want that. BUT for the predictors to generate a new result in a single cycle they can't be too large.
So you also run a separate engine, delayed a cycle or two, based on the larger pool of second level branch data, checking the predictions of the async engine. If there's a disagreement you flush whatever was fetched past that point (which hopefully is still just in the fetch queue...) and resteer. This will give you a one (or three or four) cycle bubble in the fetch stream, which is not ideal, but
- it doesn't happen that often
- it's a lot better catching a bad prediction very early in fetch, rather than much later in execution
- hopefully the fetch queue is full enough, and filled fast enough, that perhaps it's not even drained by the time decode has walked along it to the point at which the re-steer occurred...
This second (checking) branch prediction doesn't ever get mentioned, but it is there behind the scenes, even when the CPU is ostensibly doing only a single prediction per cycle.
There are other crazy things that happen in modern fetch engines (which are basically in themselves as complicated as a whole CPU from 20 years ago).
One interesting idea is to use the same data that is informing the async fetch engine to inform prefetch. The idea is that you now have essentially two fetch engines running. One is as I described above; the second ONLY cares about the stream of TAKEN branches, and follows that stream as rapidly as possible, ensuring that each line referenced by this stream is being pulled into the I-cache. (You will recognize this as something like a very specialized form of run-ahead.)
In principle this should be perfect -- the I prefetcher and branch-prediction are both trying to solve the *exact* same problem, so pooling their resources should be optimal! In practice, so far this hasn't yet been perfected; the best simulations using this idea are a very few percent behind the best simulations using a different I prefetch technology. But IMHO this is mostly a consequence of this being a fairly new idea that has so far been explored mainly by using pre-existing branch predictors, rather than designing a branch predictor store that's optimal for both tasks.
The main difference is that what matters for prefetching is "far future" branches, branches somewhat beyond where I am now, so that there's plenty of time to pull in the line all the way from RAM. And existing branch predictors have had no incentive to hold onto that sort of far future prediction state. HOWEVER
A second interesting idea is what IBM has been doing for two or three years now. They store branch prediction in what they call an L2 storage but, to avoid things, I'll cal a cold cache. This is stale/far future branch prediction data that is unused for a while but, on triggering events, that cold cache data will be swapped into the branch prediction storage so that the branch predictors are ready to go for the new context in which they find themselves.
I don't believe IBM use this to drive their I-prefetcher, but obviously it is a great solution to the problem I described above and I suspect this will be where all the performance CPUs eventually find themselves over the next few years. (Apple and IBM probably first, because Apple is Apple, and IBM has the hard part of the solution already in place; then ARM because they's smart and trying hard; then AMD because they're also smart but their technology cycles are slower than ARM; and final Intel because, well, they're Intel and have been running on fumes for a few years now.)
(Note of course this only solves I-prefetch, which is nice and important; but D-prefetch remains as a difficult and different problem.)
name99 - Friday, November 6, 2020 - link
Oh, one more thing. I referred to "width" of the CPU above. This becomes an ever vaguer term every year. The basic points are two:- when OoO started, it seemed reasonable to scale every step of the pipeline together. Make the CPU 4-wide. So it can fetch up to 4 instructions/cycle. decode up to 4, issue up to 4, retire up to 4. BUT if you do this you're losing performance every step of the way. Every cycle that fetches only 3 instructions can never make that up; likewise every cycle that only issues 3 instructions.
- so once you have enough transistors available for better designs, you need to ask yourself what's the RATE-LIMITING step? For x86 that's probably in fetch and decode, but let's consider sane ISAs like ARM. There the rate limiting step is probably register rename. So lets assume your max rename bandwidth is 6 instructions/cycle. You actually want to run the rest of your machinery at something like 7 or 8 wide because (by definition) you CAN do so (they are not rate limiting, so they can be grown). And by running them wider you can ensure that the inevitable hiccups along the way are mostly hidden by queues, and your rename machinery is running at full speed, 6-wide each and every cycle, rather than frequently running at 5 or 4 wide because of some unfortunate glitch upstream.
Spunjji - Monday, November 9, 2020 - link
These were interesting posts. Thank you!GeoffreyA - Monday, November 9, 2020 - link
Yes, excellent posts. Thanks.Touching on width, I was expecting Zen 3 to add another decoder and take it up to 5-wide decode (like Skylake onwards). Zen 3's keeping it at 4 makes good sense though, considering their constraint of not raising power. Another decoder might have raised IPC but would have likely picked up power quite a bit.
ignizkrizalid - Saturday, November 7, 2020 - link
Rip Intel no matter how hard you try squeezing Intel sometimes on top within your graphics! stupid site bias and unreliable if this site was to be truth why not do a live video comparison side by side using 3600 or 4000Mhz ram so we can see the actual numbers and be 100% assured the graphic table is not manipulated in any way, yea I know you will never do it! personally I don't trust these "reviews" that can be manipulated as desired, I respect live video comparison with nothing to hide to the public. Rip Intel Rip Intel.Spunjji - Monday, November 9, 2020 - link
I... don't think this makes an awful lots of sense, tbh.MDD1963 - Saturday, November 7, 2020 - link
It would be interesting to also see the various results of the 10900K the way most people actually run them on Z490 boards, i.e, with higher RAM clocks, MCE enabled, etc...; do the equivalent tuning with 5000 series, I'm sure they will run with faster than DDR4-3200 MHz. plus perhaps a small all-core overclock.