The Apple iPhone 11, 11 Pro & 11 Pro Max Review: Performance, Battery, & Camera Elevated
by Andrei Frumusanu on October 16, 2019 8:30 AM ESTThe A13's Memory Subsystem: Faster L2, More SLC BW
The memory subsystem of a chip is an essential backbone for the performance of not only the CPU cores, but also the whole rest of the system. In this case we’re taking a closer look at how the memory subsystem behaves on the CPU side of things.
Last year we saw Apple make significant changes to the SoC’s memory subsystem with the inclusion of a new architecture system level cache (SLC), which serves as the last level cache for not only the CPU, but also a lot of other SoC components like the GPU.
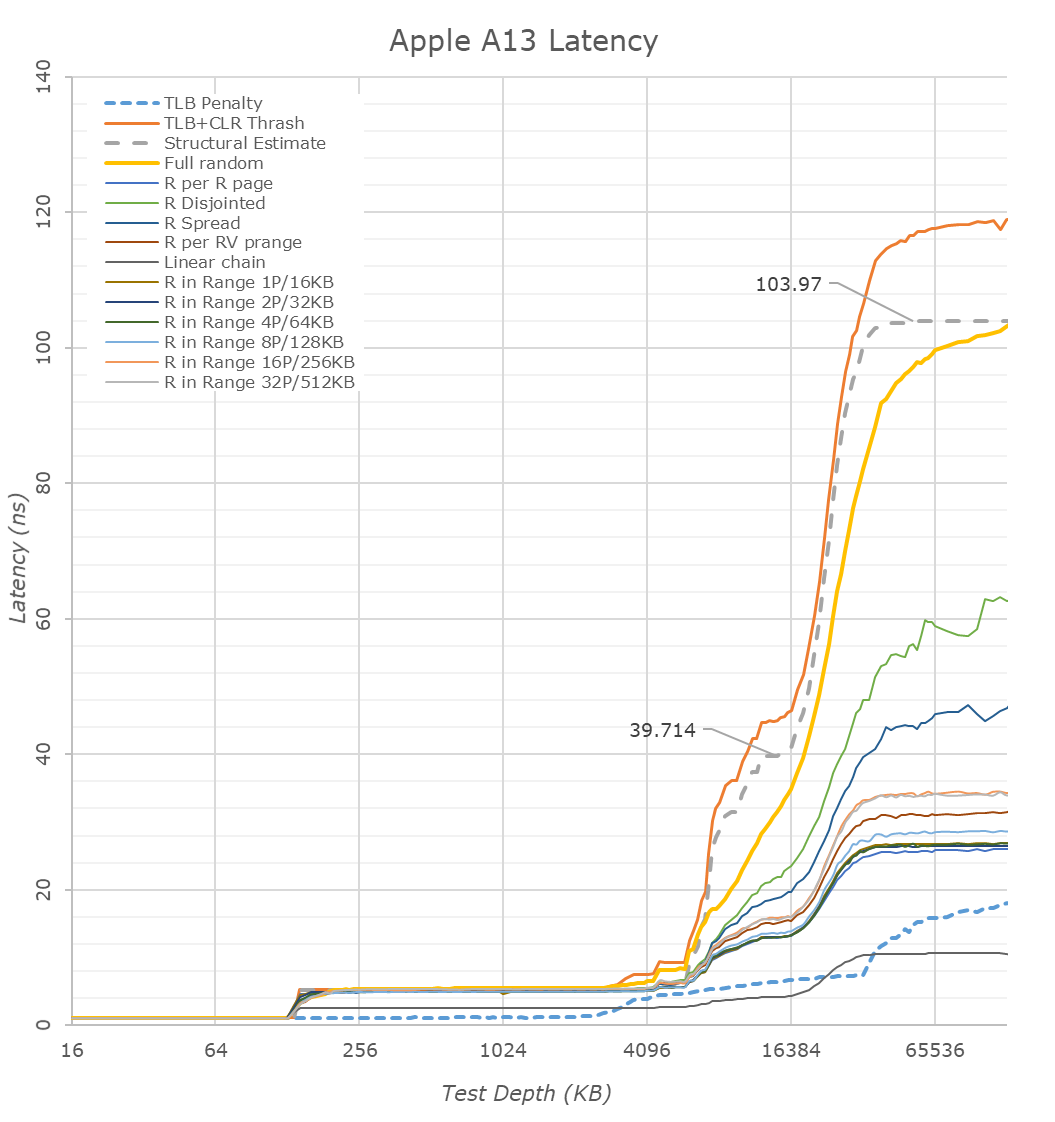
Looking first at the linear graphed memory latencies, we see that the A13’s structural DRAM latency falls in at ~104ns, a very slight regression to the 102.8ns of the A12. Apple in this regard isn’t the best among mobile SoCs, HiSilicon’s newest Kirin 990 now falls in at ~96ns and the Exynos 9820 should also fall into a similar range, however this doesn’t matter too much in the grand scheme of things given Apple’s massive cache hierarchy. Patterns such as full random pointer chasing is significantly more performant on Apple’s cores and this should be tightly linked to the strong TLBs as well as iOS’s system configuration choice of using 16KB pages.
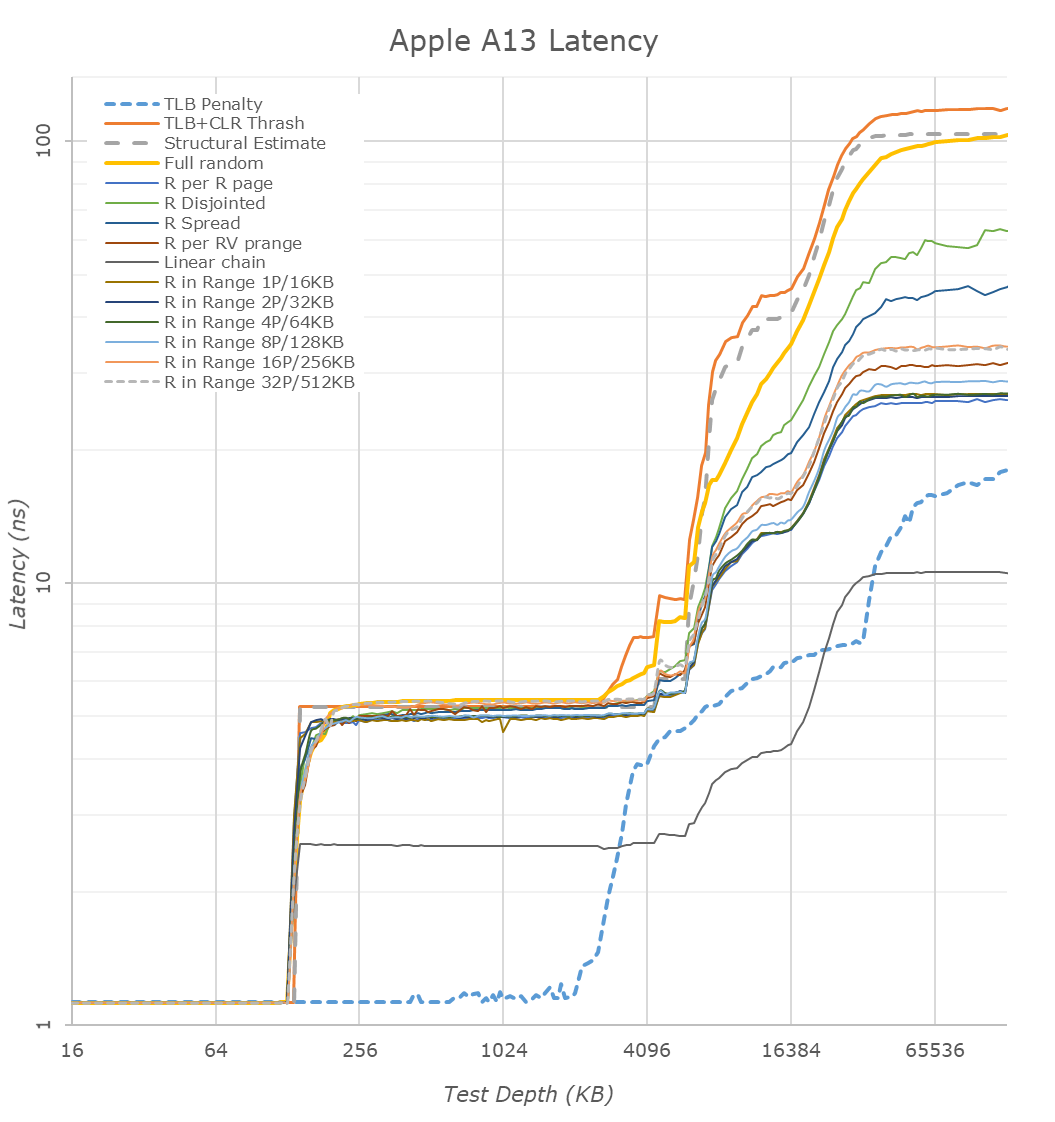
Moving to a logarithmic chart we better see the transitions between the cache hierarchies. We can clearly see Apple’s 128KB L1D cache here. The L2 cache is also relatively straightforward till 4MB as the latencies are relatively flat. From here on things become quite complicated and things differ a bit compared to the A12. Last year we determined that the L2 cache structure physically must be around 8MB in size, however we saw that it only looks as if the big cores only have access to around 6MB. Apple employs an “L2E” cache – this is seemingly a region of the big core L2 cache that serves as an L3 to the smaller efficiency cores (which themselves have their own shared L2 underneath in their CPU group).
In this region the new A13 behaves slightly different as there’s an additional “step” in the latency ladder till about 6MB. Frankly I don’t have any proper explanation as to what the microarchitecture is doing here till the 8MB mark. It does look however that the physical structure has remained at 8MB.
Going further out into the cache hierarchy we’re hitting the SLC, which would act as an L3 to the large performance cores, but should be shared with other IP blocks in the SoC. Here we see a significant change in behavior to the A12. If one had to guess as to what happening you’d think that the SLC has grown in size beyond the 8MB we estimated to have been used in the A12. Short of analyzing the die shot and see if the structure indeed has doubled, I’m a bit skeptical and I feel it’s more likely that Apple is using a partitioning system and has possibly enabled the CPU complex to access more of the SLC. What is evident here, is the doubling of the SLC cache from 8MB to 16MB.
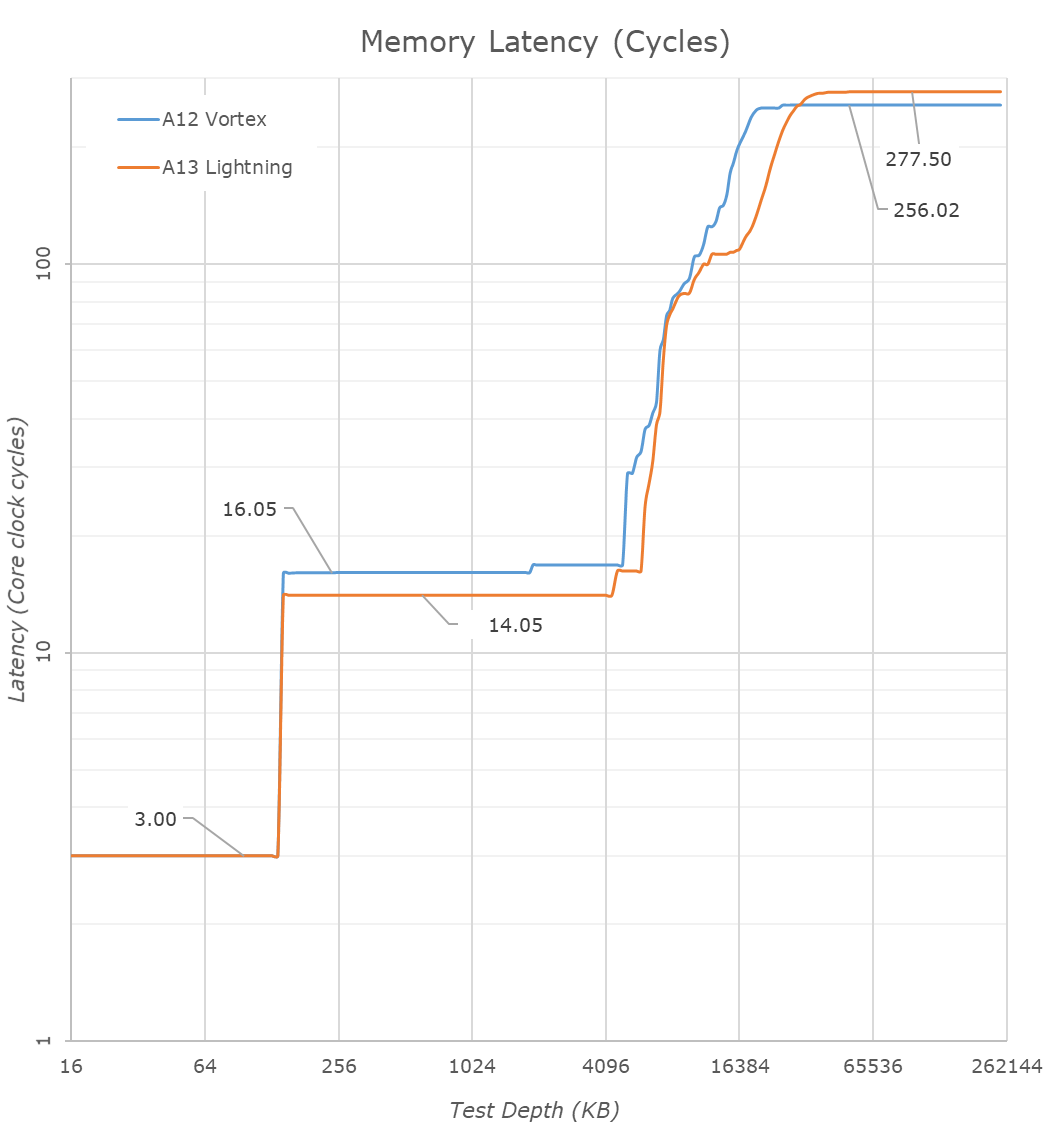
We mentioned that the Lightning cores L2 is faster now: Converting the measured latencies from nanoseconds to core cycles, we see the structural speed changes to the caches. The L1 remains at 3 cycles which is massively impressive given its 128KB size. The L2 cache has been reduced from 16 cycles down to 14 cycles, which is again extremely impressive given its purported 8MB physical size. Accounting for the core’s frequency increase, we do more noticeably see that the structural memory latency has increased a bit on the A13, adding about 21-22 cycles. It’s possible that the microarchitectural changes that made the SLC so much faster this generation had a knock-on effect in adding more total latency to DRAM.

Looking at the new Thunder cores versus last year’s Tempest microarchitecture, we see the new cache hierarchy differences. The L1D has grown from 32KB to 48KB – straightforward until now.
The L2 cache size also has evidently increased. Last year we estimated that the small core cluster had 2MB of shared L2, but was partitioned in such as way that a given core only has access to about 1.5MB, and this depth depended on the power management policy and DVFS state of the cores, appearing to only have access to 512KB when at the lowest performance states.
This year, this 1.5MB access size has seemingly increased to 2.5MB. I thus estimate the shared L2 of the small cores has increased from a physical 2MB to 3MB. Past this we’re seeing a step-wise behavior in latency up to 4MB – it’s possible this would be part of the L2E cache of the CPU complex, so in other words we’d possibly be accessing a special partition of the big core’s L2.
Update October 27th: The die shot reveals that the L2 of the Thunder cluster is half the size of the Lightning cluster L2, thus we estimate it's 4MB large in total.
In this graph we continue to see the behavior change of the A13’s SLC. At first glance it appears bigger, which still can be the case, but I rather think the CPU complex has much better access to the 4 (or more) cache slices of the SLC in this generation.
Another change of the new Thunder cores here is that we’re obviously seeing an increase in the L2 TLB capacity of the core. While the L1 TLB seems to have remained unchanged at 128 pages / 2MB, the L2 TLB has increased from 512 pages to 1024 pages – covering up to 16MB, a quite ideal size as it’s covering the depth of the SLC.
Finally, we see that the efficiency cores in the A13 this time around don’t have access to faster DRAM on their own – the memory controller remains very slow and DRAM latencies are in excess of 340ns while on the A12 the Tempest cores were able to enjoy latencies of 140-150ns. This explains some of the performance regressions of the new Thunder cores we measured earlier.
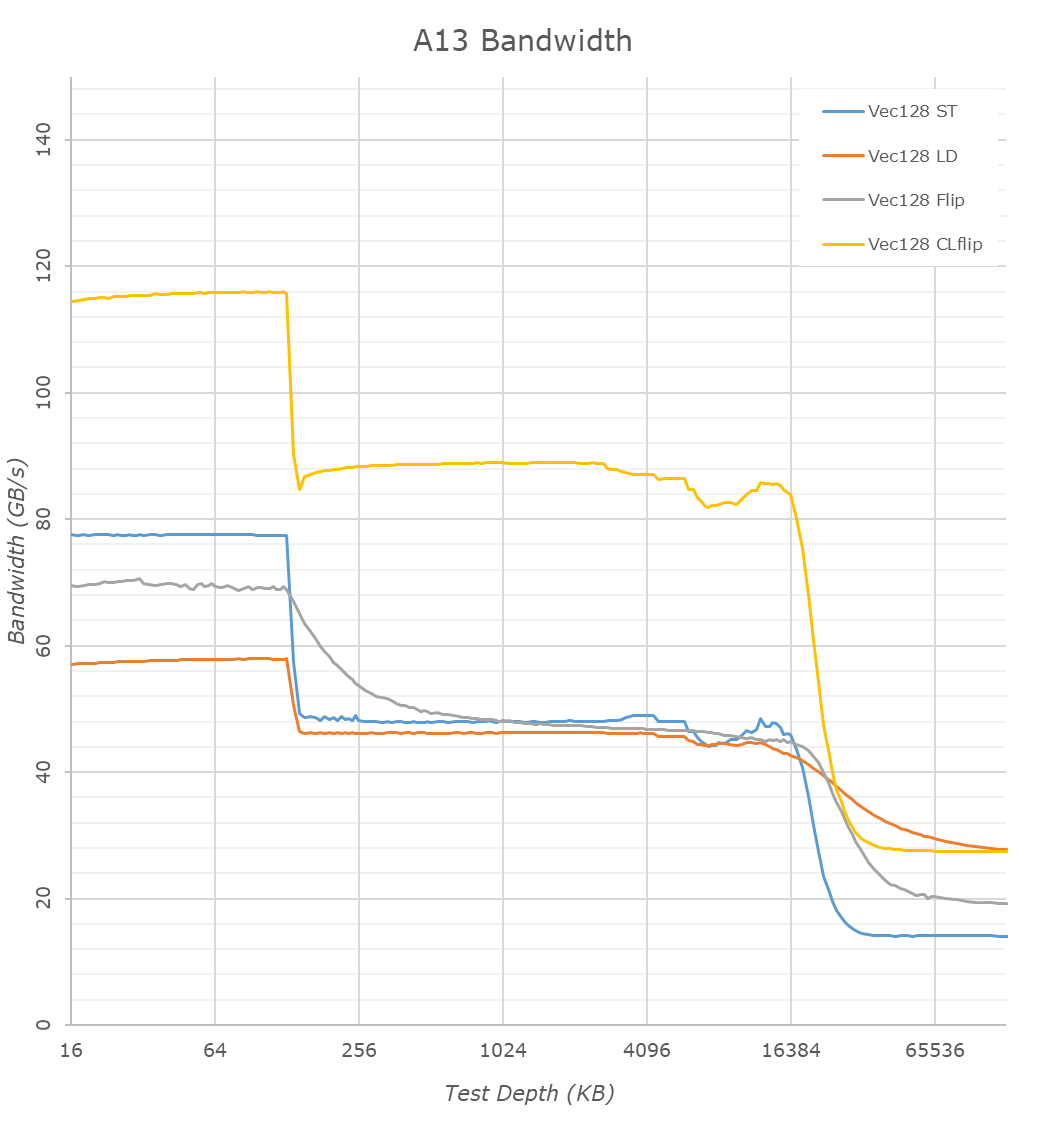
Bandwidth between the A13 and A12 doesn’t majorly differ in the L1 and DRAM regions beyond minor clock speed changes. In the L2, we notice there’s been a more noticeable increase in performance for read+writes into the same cache line, increasing performance by 25%.
It’s again in the SLC region where we see major changes – while on the A12 the bandwidth here slowly fell off in depth, the A13 is able to sustain the same bandwidth over the 16MB of system cache. It’s impressive that the bandwidth here is essentially equal to the L2 – albeit of course quite notably worse latency as we noted earlier. The smaller dips at the 8MB region is an artifact of the cache behavior between the big L2 and the SLC.
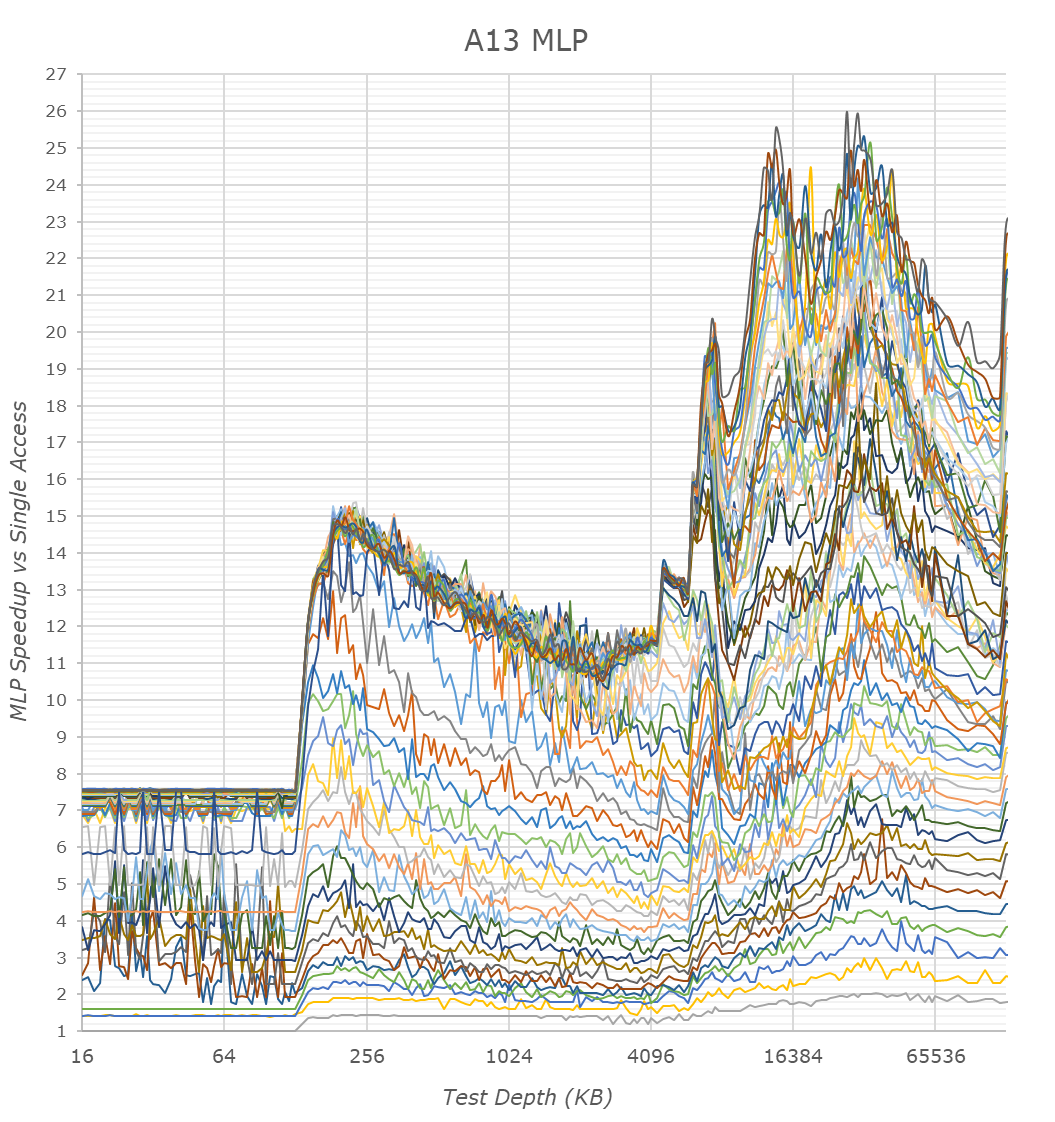
Finally, the MLP graphs showcase the memory level parallelism capacity of the CPU cores and the memory subsystem. MLP is the ability for the CPU to “park” memory requests missing the caches and to continue executing in out-of-order fashion other requests. High MLP ability is extremely important to be able to extract the most from out-of-order execution of code, which has higher memory pressure and more complex memory access patterns.
The A13 here again remains quite unique in its behavior, which is vastly more complex that what we see in any other microarchitecture. The non-linearity of the MLP speedup versus access count is something I can’t find a viable explanation for. We do see that the new A13 is a little bit better and more “even” than the A12, although what this practically means is something only Apple’s architects know. In general, Apple’s MLP ability is only second to AMD’s Zen processors, and clearly trounces anything else in the mobile space.
The overall conclusion for the A13’s memory subsystem is that Apple has evidently made very large changes to the system level cache, which is now significantly faster than what we’ve seen in the A12. The L2 cache of the big cores benefit from a 2-cycle latency reduction, but otherwise remain the same. Finally, the new Thunder efficiency cores have seen large changes with increased L1D, L2 and TLB capacity increases.








242 Comments
View All Comments
Total Meltdowner - Wednesday, October 16, 2019 - link
Bingo. I think the writer was just happy that he did notice performance improvements in this model. Still, the iPhone lacks innovation and that price tag is absurd. I'd buy it for $600 but $1000 or more? hah!Zerrohero - Wednesday, October 16, 2019 - link
“No innovation”Plenty of innovation. Read the review.
There is nothing absurd about the price tag. Not a bad price at all for your most important computer that you will use several hours per day for five years, if you want to.
Total Meltdowner - Thursday, October 17, 2019 - link
That isn't what I would call innovation. Their CPU is nice but that's about it. There is nothing you can do on the 11Pro that you couldn't do on an iPhone 7 -10.WinterCharm - Thursday, October 17, 2019 - link
Just because the visual style doesn't change does not mean there is "no innovation"There's a bunch of innovation on the chip side from Apple. You can either acknowledge that, or look like an idiot who screams no innovation while the iPhone has a 5x perf/watt lead over other ARM chips. To put that in context, it's 3-4 times the lead that Nvidia has over AMD.
Total Meltdowner - Thursday, October 17, 2019 - link
You can't do anything new with it that is worthy of praise.Jon Tseng - Wednesday, October 16, 2019 - link
Um, if you're expecting an iPhone with a removable battery, sd card slot and a non-bga socketed processor you're probably making a fairly material category error!!Zerrohero - Wednesday, October 16, 2019 - link
“ Also did author note how iPhone XS got the new battery throttling with latest iOS update ?”...which only kicks in when the battery is in bad shape and if it does, you can choose whether to throttle or not. Everybody’s XS models are running at full speed. But of course you know all this.
(Just get the battery replaced when it goes bad and you get five years of these iPhones)
A high end Android is way worse value for money because you simply can’t use it as long as an iPhone. No software updates after couple of years, apart from some rare exceptions.
When it comes to repairability, iFixit gave the new iPhones 6/10 which is better than most of the competition. For example, Samsung’s high end models are way worse when it comes to repairability.
Again, of course you know all this very well.
It’s always amusing how riled up some people get about the new iPhones. You do know that you don’t need to buy them, there are plenty of alternatives.
steven75 - Wednesday, October 16, 2019 - link
As someone living in the present year of 2019, I wish you welcome, my time-traveling friend! I hope your time spent here is illuminating before you go back to your "current" year of 2010.Total Meltdowner - Thursday, October 17, 2019 - link
There's a reason why the argument of "muh current year" is a meme. Time is irrelevant, functionality is everything.melgross - Wednesday, October 16, 2019 - link
That’s nonsense. You don’t even notice it after a while, and it’s just 2.5% of the screen. It’s a lot worse from companies that still have big bezels on top, and even one on the bottom, like the new Pixel 4 has. Totally wasted space.