The iPhone XS & XS Max Review: Unveiling the Silicon Secrets
by Andrei Frumusanu on October 5, 2018 8:00 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- iPhone XS
- iPhone XS Max
The A12 Vortex CPU µarch
When talking about the Vortex microarchitecture, we first need to talk about exactly what kind of frequencies we’re seeing on Apple’s new SoC. Over the last few generations Apple has been steadily raising frequencies of its big cores, all while also raising the microarchitecture’s IPC. I did a quick test of the frequency behaviour of the A12 versus the A11, and came up with the following table:
| Maximum Frequency vs Loaded Threads Per-Core Maximum MHz |
||||||
| Apple A11 | 1 | 2 | 3 | 4 | 5 | 6 |
| Big 1 | 2380 | 2325 | 2083 | 2083 | 2083 | 2083 |
| Big 2 | 2325 | 2083 | 2083 | 2083 | 2083 | |
| Little 1 | 1694 | 1587 | 1587 | 1587 | ||
| Little 2 | 1587 | 1587 | 1587 | |||
| Little 3 | 1587 | 1587 | ||||
| Little 4 | 1587 | |||||
| Apple A12 | 1 | 2 | 3 | 4 | 5 | 6 |
| Big 1 | 2500 | 2380 | 2380 | 2380 | 2380 | 2380 |
| Big 2 | 2380 | 2380 | 2380 | 2380 | 2380 | |
| Little 1 | 1587 | 1562 | 1562 | 1538 | ||
| Little 2 | 1562 | 1562 | 1538 | |||
| Little 3 | 1562 | 1538 | ||||
| Little 4 | 1538 | |||||
Both the A11 and A12’s maximum frequency is actually a single-thread boost clock – 2380MHz for the A11’s Monsoon cores and 2500MHz for the new Vortex cores in the A12. This is just a 5% boost in frequency in ST applications. When adding a second big thread, both the A11 and A12 clock down to respectively 2325 and 2380MHz. It’s when we are also concurrently running threads onto the small cores that things between the two SoCs diverge: while the A11 further clocks down to 2083MHz, the A12 retains the same 2380 until it hits thermal limits and eventually throttles down.
On the small core side of things, the new Tempest cores are actually clocked more conservatively compared to the Mistral predecessors. When the system just had one small core running on the A11, this would boost up to 1694MHz. This behaviour is now gone on the A12, and the clock maximum clock is 1587MHz. The frequency further slightly reduces to down to 1538MHz when there’s four small cores fully loaded.
Much improved memory latency
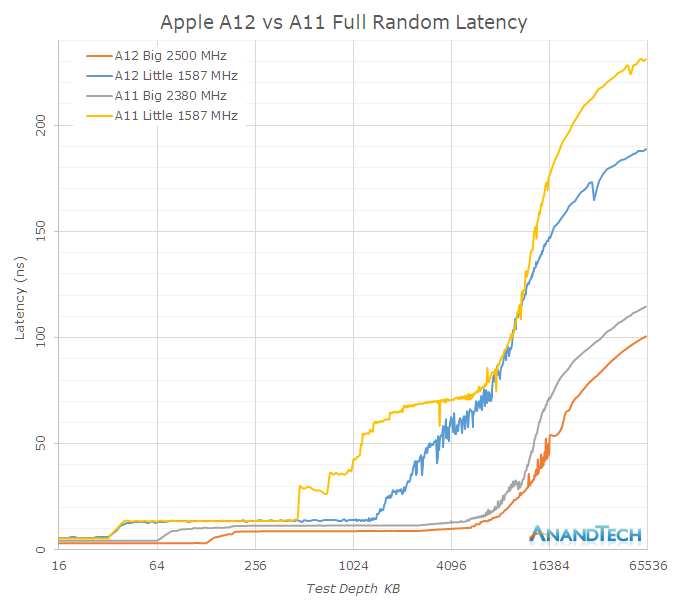
As mentioned in the previous page, it’s evident that Apple has put a significant amount of work into the cache hierarchy as well as memory subsystem of the A12. Going back to a linear latency graph, we see the following behaviours for full random latencies, for both big and small cores:
The Vortex cores have only a 5% boost in frequency over the Monsoon cores, yet the absolute L2 memory latency has improved by 29% from ~11.5ns down to ~8.8ns. Meaning the new Vortex cores’ L2 cache now completes its operations in a significantly fewer number of cycles. On the Tempest side, the L2 cycle latency seems to have remained the same, but again there’s been a large change in terms of the L2 partitioning and power management, allowing access to a larger chunk of the physical L2.
I only had the test depth test up until 64MB and it’s evident that the latency curves don’t flatten out yet in this data set, but it’s visible that latency to DRAM has seen some improvements. The larger difference of the DRAM access of the Tempest cores could be explained by a raising of the maximum memory controller DVFS frequency when just small cores are active – their performance will look better when there’s also a big thread on the big cores running.
The system cache of the A12 has seen some dramatic changes in its behaviour. While bandwidth is this part of the cache hierarchy has seen a reduction compared to the A11, the latency has been much improved. One significant effect here which can be either attributed to the L2 prefetcher, or what I also see a possibility, prefetchers on the system cache side: The latency performance as well as the amount of streaming prefetchers has gone up.
Instruction throughput and latency
| Backend Execution Throughput and Latency | ||||||||
| Cortex-A75 | Cortex-A76 | Exynos-M3 | Monsoon | Vortex | |||||
| Exec | Lat | Exec | Lat | Exec | Lat | Exec | Lat | |
| Integer Arithmetic ADD |
2 | 1 | 3 | 1 | 4 | 1 | 6 | 1 |
| Integer Multiply 32b MUL |
1 | 3 | 1 | 2 | 2 | 3 | 2 | 4 |
| Integer Multiply 64b MUL |
1 | 3 | 1 | 2 | 1 (2x 0.5) |
4 | 2 | 4 |
| Integer Division 32b SDIV |
0.25 | 12 | 0.2 | < 12 | 1/12 - 1 | < 12 | 0.2 | 10 | 8 |
| Integer Division 64b SDIV |
0.25 | 12 | 0.2 | < 12 | 1/21 - 1 | < 21 | 0.2 | 10 | 8 |
| Move MOV |
2 | 1 | 3 | 1 | 3 | 1 | 3 | 1 |
| Shift ops LSL |
2 | 1 | 3 | 1 | 3 | 1 | 6 | 1 |
| Load instructions | 2 | 4 | 2 | 4 | 2 | 4 | 2 | |
| Store instructions | 2 | 1 | 2 | 1 | 1 | 1 | 2 | |
| FP Arithmetic FADD |
2 | 3 | 2 | 2 | 3 | 2 | 3 | 3 |
| FP Multiply FMUL |
2 | 3 | 2 | 3 | 3 | 4 | 3 | 4 |
| Multiply Accumulate MLA |
2 | 5 | 2 | 4 | 3 | 4 | 3 | 4 |
| FP Division (S-form) | 0.2-0.33 | 6-10 | 0.66 | 7 | >0.16 | 12 | 0.5 | 1 | 10 | 8 |
| FP Load | 2 | 5 | 2 | 5 | 2 | 5 | ||
| FP Store | 2 | 1-N | 2 | 2 | 2 | 1 | ||
| Vector Arithmetic | 2 | 3 | 2 | 2 | 3 | 1 | 3 | 2 |
| Vector Multiply | 1 | 4 | 1 | 4 | 1 | 3 | 3 | 3 |
| Vector Multiply Accumulate | 1 | 4 | 1 | 4 | 1 | 3 | 3 | 3 |
| Vector FP Arithmetic | 2 | 3 | 2 | 2 | 3 | 2 | 3 | 3 |
| Vector FP Multiply | 2 | 3 | 2 | 3 | 1 | 3 | 3 | 4 |
| Vector Chained MAC (VMLA) |
2 | 6 | 2 | 5 | 3 | 5 | 3 | 3 |
| Vector FP Fused MAC (VFMA) |
2 | 5 | 2 | 4 | 3 | 4 | 3 | 3 |
To compare the backend characteristics of Vortex, we’ve tested the instruction throughput. The backend performance is determined by the amount of execution units and the latency is dictated by the quality of their design.
The Vortex core looks pretty much the same as the predecessor Monsoon (A11) – with the exception that we’re seemingly looking at new division units, as the execution latency has seen a shaving of 2 cycles both on the integer and FP side. On the FP side the division throughput has seen a doubling.
Monsoon (A11) was a major microarchitectural update in terms of the mid-core and backend. It’s there that Apple had shifted the microarchitecture in Hurricane (A10) from a 6-wide decode from to a 7-wide decode. The most significant change in the backend here was the addition of two integer ALU units, upping them from 4 to 6 units.
Monsoon (A11) and Vortex (A12) are extremely wide machines – with 6 integer execution pipelines among which two are complex units, two load/store units, two branch ports, and three FP/vector pipelines this gives an estimated 13 execution ports, far wider than Arm’s upcoming Cortex A76 and also wider than Samsung’s M3. In fact, assuming we're not looking at an atypical shared port situation, Apple’s microarchitecture seems to far surpass anything else in terms of width, including desktop CPUs.








253 Comments
View All Comments
Andrei Frumusanu - Sunday, October 7, 2018 - link
Smartphones can sustain 3-3.5W. There's a window of several minutes where you can maintain peak. However because CPU workloads are bursty, it's rare that you would hit thermal issues in usual scenarios. Sustained scenarios are games, but there the GPU is the bottleneck in terms of power.Batteries easily sustain 1C discharge rate, for the XS' that's 2.6 and 3.1A, or rounded to around 10 to 12W. Temperature becomes a natural limitations before the battery discharge rate becomes any concern.
Javert89 - Sunday, October 7, 2018 - link
Thanks for the reply. My look on the battery was long term, in the past there has been the 'throttling fiasco' in which the performance of the device was cut down because batteries seemingly could not hold the power requested.. If the power draw increased on the A12, I could wonder if the problem will get worseConstructor - Sunday, October 7, 2018 - link
The whole panic about the iPhone 6 on old, softening batteries was basically just this, but after one relatively crude attempt they got the power management optimized that I had very little if any slowdown even on my 4 years old battery.The crash during the extreme load test on the XS will of course need to get fixed with another power management update, just that it needs to apply even to factory-fresh batteries already.
But when the battery ages and its current delivery capability erodes over time it will only become more and more necessary for power management to deal with such spikes, possibly by ramping up the clock less aggressively.
iAPX - Sunday, October 7, 2018 - link
This test is a master piece. Kudos!TheSparda - Sunday, October 7, 2018 - link
I am interested to know more the recent issues with the poor wifi & LTE speeds and signal strength. A smartphone having great cpu/gpu is good and all, but some of the basics such as wifi & LTE should also be up to snuff if apple wants to phone to be a total package. I feel that the wifi & LTE issues are overlooked when they designed the phone.FunBunny2 - Monday, October 8, 2018 - link
"I feel that the wifi & LTE issues are overlooked when they designed the phone."see my earlier comment, to wit: if you want to make a clear phone call, get a landline.
varase - Tuesday, October 23, 2018 - link
It already seems fixed in 12.1 beta 3, and may have been fixed in 12.0.1 but I don't have that installed.lucam - Sunday, October 7, 2018 - link
I was sure that the GPU used on A11 and A12 are basically Imagination Tech solutions and Apple can't design a completely new GPU solution from scratch.I am wondering if Apple will use the future Furian solution or not in future chips; if they won't as they don't partner anymore they will regret it.
Question is what's the current agreement with Imagination as they are still using PowerVR solutions.
tipoo - Wednesday, October 24, 2018 - link
Even with the A10, their GPU was 2/3rds custom, their arrangement with Imagination seems similar to their ARM licence. Calling it custom as of the A11 even though not that much seemed to change (but for grouping more ALUs into a core) seems like a formality.https://www.realworldtech.com/apple-custom-gpu/
Calin - Monday, October 8, 2018 - link
You could do some tests in "Airplane" mode to eliminate the WiFi and telephony stack power use.I'm not sure there's a way to eliminate the telephony stack but still keep the WiFi active.