The iPhone XS & XS Max Review: Unveiling the Silicon Secrets
by Andrei Frumusanu on October 5, 2018 8:00 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- iPhone XS
- iPhone XS Max
The A12 Vortex CPU µarch
When talking about the Vortex microarchitecture, we first need to talk about exactly what kind of frequencies we’re seeing on Apple’s new SoC. Over the last few generations Apple has been steadily raising frequencies of its big cores, all while also raising the microarchitecture’s IPC. I did a quick test of the frequency behaviour of the A12 versus the A11, and came up with the following table:
| Maximum Frequency vs Loaded Threads Per-Core Maximum MHz |
||||||
| Apple A11 | 1 | 2 | 3 | 4 | 5 | 6 |
| Big 1 | 2380 | 2325 | 2083 | 2083 | 2083 | 2083 |
| Big 2 | 2325 | 2083 | 2083 | 2083 | 2083 | |
| Little 1 | 1694 | 1587 | 1587 | 1587 | ||
| Little 2 | 1587 | 1587 | 1587 | |||
| Little 3 | 1587 | 1587 | ||||
| Little 4 | 1587 | |||||
| Apple A12 | 1 | 2 | 3 | 4 | 5 | 6 |
| Big 1 | 2500 | 2380 | 2380 | 2380 | 2380 | 2380 |
| Big 2 | 2380 | 2380 | 2380 | 2380 | 2380 | |
| Little 1 | 1587 | 1562 | 1562 | 1538 | ||
| Little 2 | 1562 | 1562 | 1538 | |||
| Little 3 | 1562 | 1538 | ||||
| Little 4 | 1538 | |||||
Both the A11 and A12’s maximum frequency is actually a single-thread boost clock – 2380MHz for the A11’s Monsoon cores and 2500MHz for the new Vortex cores in the A12. This is just a 5% boost in frequency in ST applications. When adding a second big thread, both the A11 and A12 clock down to respectively 2325 and 2380MHz. It’s when we are also concurrently running threads onto the small cores that things between the two SoCs diverge: while the A11 further clocks down to 2083MHz, the A12 retains the same 2380 until it hits thermal limits and eventually throttles down.
On the small core side of things, the new Tempest cores are actually clocked more conservatively compared to the Mistral predecessors. When the system just had one small core running on the A11, this would boost up to 1694MHz. This behaviour is now gone on the A12, and the clock maximum clock is 1587MHz. The frequency further slightly reduces to down to 1538MHz when there’s four small cores fully loaded.
Much improved memory latency
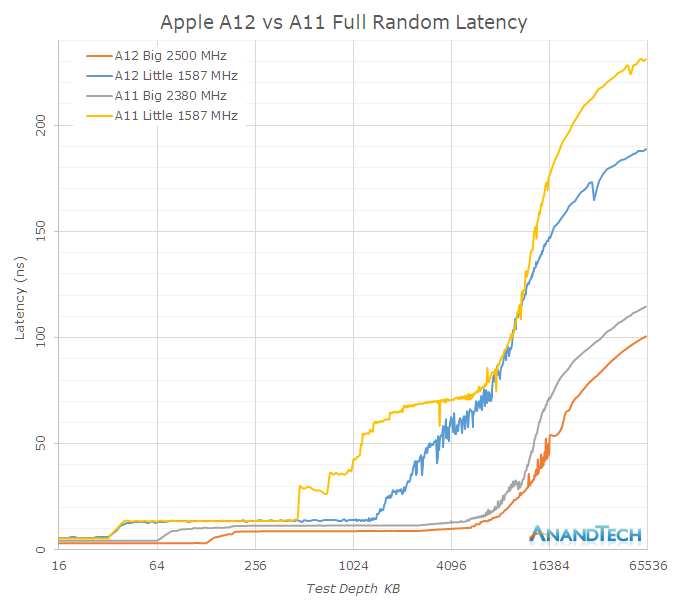
As mentioned in the previous page, it’s evident that Apple has put a significant amount of work into the cache hierarchy as well as memory subsystem of the A12. Going back to a linear latency graph, we see the following behaviours for full random latencies, for both big and small cores:
The Vortex cores have only a 5% boost in frequency over the Monsoon cores, yet the absolute L2 memory latency has improved by 29% from ~11.5ns down to ~8.8ns. Meaning the new Vortex cores’ L2 cache now completes its operations in a significantly fewer number of cycles. On the Tempest side, the L2 cycle latency seems to have remained the same, but again there’s been a large change in terms of the L2 partitioning and power management, allowing access to a larger chunk of the physical L2.
I only had the test depth test up until 64MB and it’s evident that the latency curves don’t flatten out yet in this data set, but it’s visible that latency to DRAM has seen some improvements. The larger difference of the DRAM access of the Tempest cores could be explained by a raising of the maximum memory controller DVFS frequency when just small cores are active – their performance will look better when there’s also a big thread on the big cores running.
The system cache of the A12 has seen some dramatic changes in its behaviour. While bandwidth is this part of the cache hierarchy has seen a reduction compared to the A11, the latency has been much improved. One significant effect here which can be either attributed to the L2 prefetcher, or what I also see a possibility, prefetchers on the system cache side: The latency performance as well as the amount of streaming prefetchers has gone up.
Instruction throughput and latency
| Backend Execution Throughput and Latency | ||||||||
| Cortex-A75 | Cortex-A76 | Exynos-M3 | Monsoon | Vortex | |||||
| Exec | Lat | Exec | Lat | Exec | Lat | Exec | Lat | |
| Integer Arithmetic ADD |
2 | 1 | 3 | 1 | 4 | 1 | 6 | 1 |
| Integer Multiply 32b MUL |
1 | 3 | 1 | 2 | 2 | 3 | 2 | 4 |
| Integer Multiply 64b MUL |
1 | 3 | 1 | 2 | 1 (2x 0.5) |
4 | 2 | 4 |
| Integer Division 32b SDIV |
0.25 | 12 | 0.2 | < 12 | 1/12 - 1 | < 12 | 0.2 | 10 | 8 |
| Integer Division 64b SDIV |
0.25 | 12 | 0.2 | < 12 | 1/21 - 1 | < 21 | 0.2 | 10 | 8 |
| Move MOV |
2 | 1 | 3 | 1 | 3 | 1 | 3 | 1 |
| Shift ops LSL |
2 | 1 | 3 | 1 | 3 | 1 | 6 | 1 |
| Load instructions | 2 | 4 | 2 | 4 | 2 | 4 | 2 | |
| Store instructions | 2 | 1 | 2 | 1 | 1 | 1 | 2 | |
| FP Arithmetic FADD |
2 | 3 | 2 | 2 | 3 | 2 | 3 | 3 |
| FP Multiply FMUL |
2 | 3 | 2 | 3 | 3 | 4 | 3 | 4 |
| Multiply Accumulate MLA |
2 | 5 | 2 | 4 | 3 | 4 | 3 | 4 |
| FP Division (S-form) | 0.2-0.33 | 6-10 | 0.66 | 7 | >0.16 | 12 | 0.5 | 1 | 10 | 8 |
| FP Load | 2 | 5 | 2 | 5 | 2 | 5 | ||
| FP Store | 2 | 1-N | 2 | 2 | 2 | 1 | ||
| Vector Arithmetic | 2 | 3 | 2 | 2 | 3 | 1 | 3 | 2 |
| Vector Multiply | 1 | 4 | 1 | 4 | 1 | 3 | 3 | 3 |
| Vector Multiply Accumulate | 1 | 4 | 1 | 4 | 1 | 3 | 3 | 3 |
| Vector FP Arithmetic | 2 | 3 | 2 | 2 | 3 | 2 | 3 | 3 |
| Vector FP Multiply | 2 | 3 | 2 | 3 | 1 | 3 | 3 | 4 |
| Vector Chained MAC (VMLA) |
2 | 6 | 2 | 5 | 3 | 5 | 3 | 3 |
| Vector FP Fused MAC (VFMA) |
2 | 5 | 2 | 4 | 3 | 4 | 3 | 3 |
To compare the backend characteristics of Vortex, we’ve tested the instruction throughput. The backend performance is determined by the amount of execution units and the latency is dictated by the quality of their design.
The Vortex core looks pretty much the same as the predecessor Monsoon (A11) – with the exception that we’re seemingly looking at new division units, as the execution latency has seen a shaving of 2 cycles both on the integer and FP side. On the FP side the division throughput has seen a doubling.
Monsoon (A11) was a major microarchitectural update in terms of the mid-core and backend. It’s there that Apple had shifted the microarchitecture in Hurricane (A10) from a 6-wide decode from to a 7-wide decode. The most significant change in the backend here was the addition of two integer ALU units, upping them from 4 to 6 units.
Monsoon (A11) and Vortex (A12) are extremely wide machines – with 6 integer execution pipelines among which two are complex units, two load/store units, two branch ports, and three FP/vector pipelines this gives an estimated 13 execution ports, far wider than Arm’s upcoming Cortex A76 and also wider than Samsung’s M3. In fact, assuming we're not looking at an atypical shared port situation, Apple’s microarchitecture seems to far surpass anything else in terms of width, including desktop CPUs.








253 Comments
View All Comments
Andrei Frumusanu - Friday, October 5, 2018 - link
Pixels and Mate 20 are next in line.name99 - Friday, October 5, 2018 - link
Hi Andrei,A few comments/questions.
- the detailed Vortex and GPU die shots seem to bear no resemblance to the full SoC die shot. I cannot figure out the relationship no matter how I try to twist and reflect...
Because I can't place them, I can't see the physical relationship of the "new A10 cache" to the rest of the SoC. If it's TIGHTLY coupled to one core, one possibility is value prediction? Another suggested idea that requires a fair bit of storage is instruction criticality tracking.
If it's loosely coupled to both cores, one possibility is it's a central repository for prefetch? Some sort of total prefetching engine that knows the usage history of the L1s AND L2s and is performing not just fancy prefetch (at both L1s and L2s) but additional related services like dead block prediction or drowsiness prediction?
Andrei Frumusanu - Friday, October 5, 2018 - link
The Vortex and GPU are just crops of the die shot at the top of the page. The Vortex shot is the bottom core rotated 90° counter-clockwise, and the GPU core is either top left or bottom right core, again rotated 90° ccw so that I could have them laid out horizontally.The "A10 cache" has no relationship with the SoC, it's part of the front-end.
name99 - Friday, October 5, 2018 - link
OK, I got ya. Thanks for the clarification. I agree, no obvious connection to L2 and the rest of the SoC. So value prediction or instruction criticality? VP mostly makes sense for loads, so we'd expect it near LS, but criticality makes sense near the front end. It's certainly something I'm partial to, though it's been mostly ignored in the literature compared to other topics. I agree it's a long shot, but, like you said, what else is that block for?name99 - Friday, October 5, 2018 - link
"The benchmark is characterised by being instruction store limited – again part of the Vortex µarch that I saw a great improvement in."Can you clarify this? There are multiple possible improvements.
- You state that A12 supports 2-wide store. The impression I got was that as of A11, Apple supported the fairly tradition 2-wide load/1-wide store per cycle. Is your contention that even as of A11, 2 stores/cycle were possible? Is there perhaps an improvement here along the lines of: previously the CPU could sustain 3 LS ops/cycle (pick a combination from up to 2 loads and up to 2 stores) and now it can sustain 4 LS ops/cycle?
- Alternatively, are the stores (and loads) wider? As of A11, the width of one path to the L1 cache was 128 bits wide. It was for this reason that bulk loads and stores could run as fast using pair load-store integer as using vector load stores (and there was no improvement in using the multi-vector load-stores). When I spoke to some Apple folks about this, the impression I got was that they were doing fancy gathering in the load store buffers before the cache, and so there was no "instruction" advantage to using vector load/stores, whatever instruction sequence you ran, it would as aggressively and as wide as possible gather before hitting the cache. So if the LS queue is now gathering to 256 bits wide, that's going to give you double the LS bandwidth (of course for appropriately written, very dense back to back load/stores).
- alternatively do you simply mean that non-aligned load/stores are handled better (eg LS that crossed cache lines were formerly expensive and now are not)? You'd hope that code doesn't do much of these, but nothing about C-code horrors surprises me any more...
BTW, it's hard to find exactly comparable numbers, but
https://www.anandtech.com/show/11544/intel-skylake...
shows the performance of a range of different server class CPUs on SPEC2006 INT, compiled under much the same conditions. A12 is, ballpark, about at the level of Skylake-SP at 3.8 to 4GHz...
(Presumably Skylake would do a lot better in *some* FP bcs of AVX512, but FP results aren't available.) This gives insight across a wider range of x86 servers than the link Andrei provided.
The ideal would be to have SPEC2006 compiled using XCode for say the newest iMac and iMac Pro, and (for mobile space) MacBook Pro...
Andrei Frumusanu - Friday, October 5, 2018 - link
> Is your contention that even as of A11, 2 stores/cycle were possible?Yes.
> - Alternatively, are the stores (and loads) wider?
Didn't verify, and very unlikely.
> - alternatively do you simply mean that non-aligned load/stores are handled better
Yes.
remedo - Friday, October 5, 2018 - link
Can you please review the massive NPU? It seems like NPU deserves a lot more attention given the industry trend.Andrei Frumusanu - Friday, October 5, 2018 - link
I don't have any good way to test it at the moment.Ansamor - Friday, October 5, 2018 - link
Aren't these (https://itunes.apple.com/es/app/aimark/id137796825... tests cross-platform or comparable with the ones of Master Lu? I remember that you used it to compare the Kirin 970 against the Qualcomm DSP.Andrei Frumusanu - Friday, October 5, 2018 - link
Wasn't aware it was available on iOS, I'll look into it.