The NVIDIA Turing GPU Architecture Deep Dive: Prelude to GeForce RTX
by Nate Oh on September 14, 2018 12:30 PM ESTThe Turing Architecture: Volta in Spirit
Diving straight into the microarchitecture, the new Turing SM looks very different to the Pascal SM, but those who’ve been keeping track of Volta will notice a lot of similarities to the NVIDIA’s more recent microarchitecture. In fact, on a high-level, the Turing SM is fundamentally the same, with the notable exception of a new IP block: the RT Core. Putting the RT Cores and Tensor Cores aside for now, the most drastic changes from Pascal are same ones that differentiated Volta from Pascal. Turing’s advanced shading features are also in the same bucket in needing explicit developer support.

Like Volta, the Turing SM is partitioned into 4 sub-cores (or processing blocks) with each sub-core having a single warp scheduler and dispatch unit, as opposed Pascal’s 2 partition setup with two dispatch ports per sub-core warp scheduler. There are some fairly major implications with change, and broadly-speaking this means that Volta/Turing loses the capability to issue a second, non-dependent instruction from a thread for a single clock cycle. Turing is presumably identical to Volta performing instructions over two cycles but with schedulers that can issue an independent instruction every cycle, so ultimately Turing can maintain 2-way instruction level parallelism (ILP) this way, while still having twice the amount of schedulers over Pascal.
Like we saw in Volta, these changes go hand-in-hand with the new scheduling/execution model with independent thread scheduling that Turing also has, though differences were not disclosed at this time. Rather than per-warp like Pascal, Volta and Turing have per-thread scheduling resources, with a program counter and stack per-thread to track thread state, as well as a convergence optimizer to intelligently group active same-warp threads together into SIMT units. So all threads are equally concurrent, regardless of warp, and can yield and reconverge.

In terms of the CUDA cores and ALUs, the Turing sub-core has 16 INT32 cores, 16 FP32 cores, and 2 Tensor Cores, the same setup as the Volta sub-core. With the split INT/FP datapath model like Volta, Turing can also concurrently execute FP and INT instructions, which as we will see, is much more relevant with the RT cores involved. Where Turing differs is in lacking Volta’s full complement of FP64 cores, instead having a token amount (2 per SM) for compatibility reasons and resulting in FP64 throughput being 1/32 the TFLOP rate of FP32. Maimed FP64 is standard for NVIDIA’s consumer GPUs, but what has not been standard until now is Turing’s full 2x FP16 throughput, which was available in GP100 but was crippled in the other Pascal GPUs.
While these details may be more on the technical side of things, in Volta this design seemed inextricably linked to maximizing the most amount of performance from tensor cores, but minimizing disrupting parallelism or coordination with other compute workloads. The same is most likely true with Turing’s 2nd generation tensor cores and RT cores, where 4 independently scheduled sub-cores and granular thread manipulation would be very useful in extracting the most performance out of mixed gaming-oriented workloads, where rendering a single frame would be pulling in multiple blocks of the GPU to work in conjunction. This is actually a concept that circumscribes the RTX-OPS metric, and we will revisit that in depth later.
Memory-wise, every sub-core now has an L0 instruction cache like Volta, with identically sized 64 KB register file. In Volta, this was important in reducing latency when the tensor cores were in play, and in Turing this likely benefits RT cores similarly, which we will discuss in a later section. Otherwise, the Turing SM also has 4 load/store units per sub-core, down from 8 in Volta, but still maintains 4 texture units.
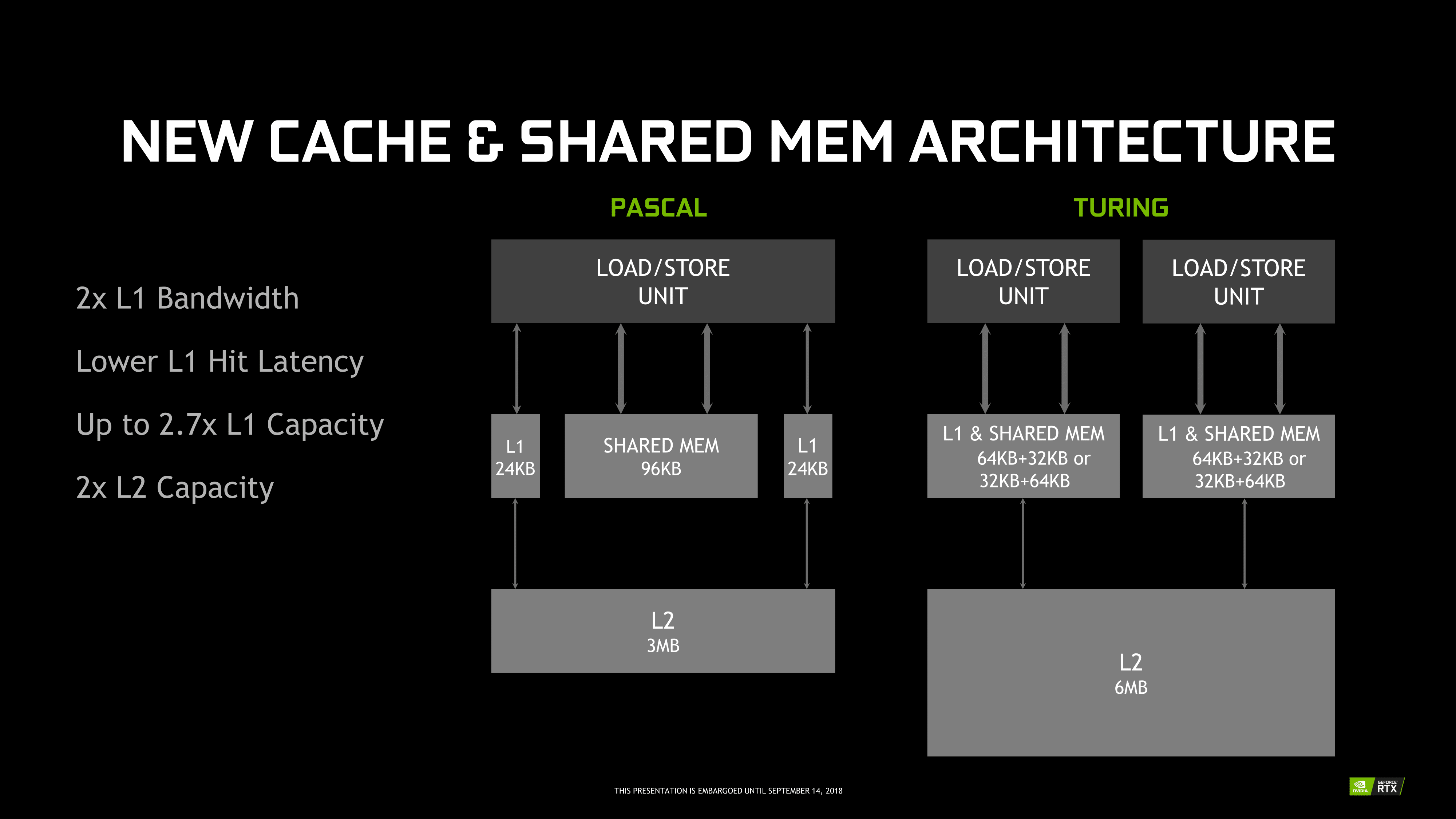
Further up the memory hierarchy is the new L1 data cache and Shared Memory (SMEM) that has been revamped and unified into a single partitionable memory block, another Volta innovation. For Turing, this is looking to be a combined 96 KB L1/SMEM, which traditional graphics workloads divide as 64KB for dedicated graphics shader RAM and as 32 KB for texture cache and register file spill area. Meanwhile, compute workloads can partition the L1/SMEM with up to 64 KB as L1 with the remaining 32 KB as SMEM, or vice versa. For Volta, SMEM can be configured up to 96 KB.
Though many of these details are only of value to developers, there are several important points to make here. One is simply how similar Turing and Volta are, as opposed to ; after all, they are in the same generational compute family. Another is how compute-oriented Volta – and by extension, Turing – are, and the fact that this is being brought to consumers as part of NVIDIA’s proclaimed ‘future of gaming.’ Part of that is, of course, permitting fast FP16 in potential gaming workloads, but Turing goes far beyond that. At the low level, Turing is less about maximizing traditional gaming, and more about maximizing gaming with special technologies such as real-time raytracing.
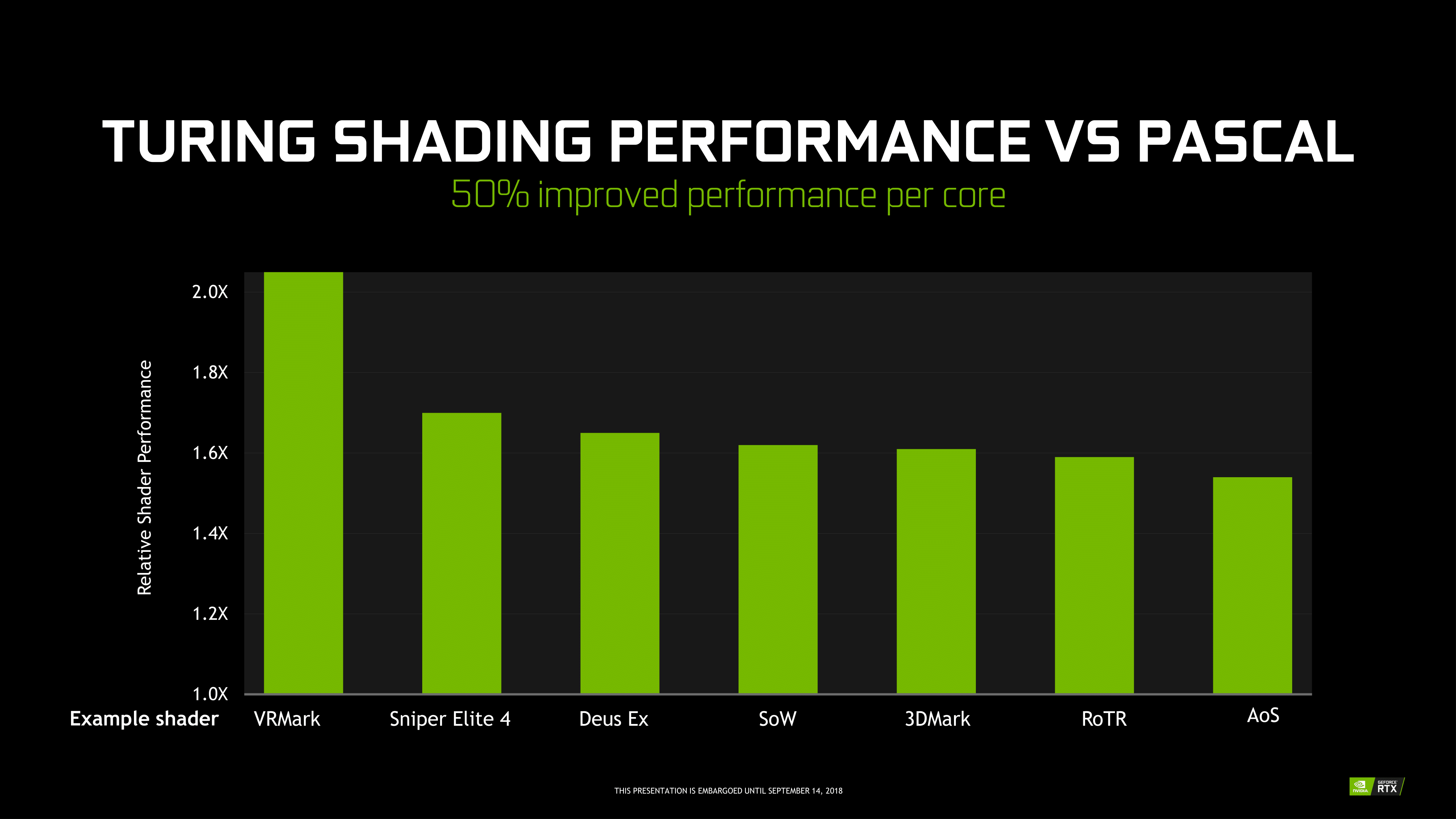
For their part, NVIDIA points to Turing’s leap in performance from Pascal, from memory hierarchy bandwidth uplifts to 50% more shader performance per core, but unfortunately for today we can’t connect this with any real world data or performance. With concurrent FP/INT execution in gaming, the company is keen to point out that around 36 INT instructions could be freed up by moving to its own pipe, which nevertheless doesn’t describe Turing performance, only the applicability of its concurrent execution feature in games.
It becomes a bit of a complex scenario, as we know that Volta already improved on Pascal in these aspects with concurrent execution, a brand new ISA, and reworked SM. And it doesn’t seem to involve architectural changes for significant clockspeed enhancements a la Pascal from Maxwell, though of course on the process side the 12nm FFN is a factor. So it comes down to special gaming workloads and real-world performance. The latter is not available today, but the former is so important to Turing that it merited dropping ‘GTX’ for ‘RTX’. And of those special workloads, real-time raytracing and RT cores take center stage.








111 Comments
View All Comments
willis936 - Sunday, September 16, 2018 - link
Also in case there's anyone else in the signal integrity business reading this: does it bug anyone else that eye diagrams are always heatmaps without a colorbar legend? When I make eye diagrams I put a colorbar legend in to signify hits per mV*ps area. The only thing I see T&M companies do is specify how many samples are in the eye diagram but I don't think that's enough for easy apples to apples comparisons.Manch - Sunday, September 16, 2018 - link
No, bc heatmaps are std.willis936 - Monday, September 17, 2018 - link
A heatmap would still be used. The color alone has no meaning unless you know how many hits there are total. Even that is useless if you want to build a bathtub. The colorbar would actually tell you how many hits are in a region. This applies to all heatmaps.casperes1996 - Sunday, September 16, 2018 - link
Wow... I just started a computer science education recently, and I was recently tasked with implementing an effecient search algorithm that works on infinitely long data streams. I made it so it first checks for an upper boundary in the array, (and updates the lower boundary based on the upper one) and then does a binary search on that subarray. I feel like there's no better time to read this article since it talks about the BVH. I felt so clever when I read it and thought "That sounds a lot like a binary search" before the article then mentioned it itself!ballsystemlord - Sunday, September 16, 2018 - link
You made only 1 typo! Great job!"In any case, as most silicon design firms hvae leapfrogging design teams,"
Should be "have":
"In any case, as most silicon design firms have leapfrogging design teams,"
There is one more problem (stray 2 letter word), in your article, but I forgot were it was. Sorry.
Sherlock - Monday, September 17, 2018 - link
The fact that Microsoft has released a Ray Tracing specific API seems to suggest that the next XBox will support it. And considering AMD is the CPU/GPU partner for the next gen XBox - it seems highly likely that the next gen AMD GPU's will have dedicated Ray Tracing hardware as well. I expect meaningful use of these hardware feature only once the next gen console hardware is released - which is due in the next 2-3 years. RTX seems a wasteful expenditure for the end-consumer now. The only motivation for NVidia to release this now is so that consumers don't feel as they are behind the curve against AMD. This gives some semblance to the rumros that Nvidia will release a "GTX" line and expect it to be their volume selling product - with the RTX as proof-of-concept for early adoptersbebby - Monday, September 17, 2018 - link
Very good point from Sherlock. I also believe that Sony and Microsoft will be the ones defining what kind of hardware features will be used and which not.In general, with Moore's Law slowing down, progress gets slower and the incremental improvements are minimal. With the result that there is less competition, prices go up and there is not any more any "wow" effect coming with a new GPU. (last time I had this was with the 470gtx)
My disappointment lies with the power consumption. Nvidia should focus more on power consumption rather than performance if they ever want to have a decent market share in tablets/phablets.
levizx - Monday, September 17, 2018 - link
Actually the efficiency increased only 18% not 23%. 150% / 127% - 1 = 18.11%, you can't just 50% - 27% = 23%, the efficiency increase is compared to "without optimization" i.e. 127%rrinker - Monday, September 17, 2018 - link
91 comments (as I type this) and most of them are arguing over "boo hoo, it's too expensive" Well, if it's too expensive - don't buy it. Why complain? Oh yeah, because Internet. This is NOT just the same old GPU, just a little faster - this is something completely different, or at least, something with significant differences to the current cop of traditional GPUs. There's no surprise that it's going to be more expensive - if you are shocked at the price then you really MUST be living under a rock. The first new ANYTHING is always premium priced - there is no competition, it's a unique product, and there is a lot of development costs involved. CAN they sell it for less? Most likely, but their job is not to sell it for the lowest possible profit, it's to sell it for what the market will bear. Simple as that. Don't like it, don;t buy it. Absolutely NO ONE needs the latest and greatest on launch day. I won't be buying one of these, I do nothing that would benefit from the new features. Maybe in a few years, when everyone has raytracing, and the games I want to play require it - then I'll buy a card like this. Griping about pricing on something you don't need - priceless.eddman - Tuesday, September 18, 2018 - link
... except this is the first time we've had such a massive price jump in the past 18 years. Even 8800 series, which according to jensen was the biggest technology jump before 20 series, launched at about the same MSRP as the last gen.It does HYBRID, partial, limited ray-tracing, and? How does that justify such a massive price jump? If these cards are supposed to be the replacements for pascals, then they are damn overpriced COMPARED to them. This is not how generational pricing is supposed to be.
If these are supposed to be a new category, then why name them like that? Why not go with 2090 Ti, 2090, or something along those lines.
Since they haven't done that and considering they left and right compare these cards to pascal cards even in regular rasterized games, then I have to conclude they consider them generational replacements.