AMD Zen Microarchitecture: Dual Schedulers, Micro-Op Cache and Memory Hierarchy Revealed
by Ian Cutress on August 18, 2016 9:00 AM ESTDeciphering the New Cache Hierarchy
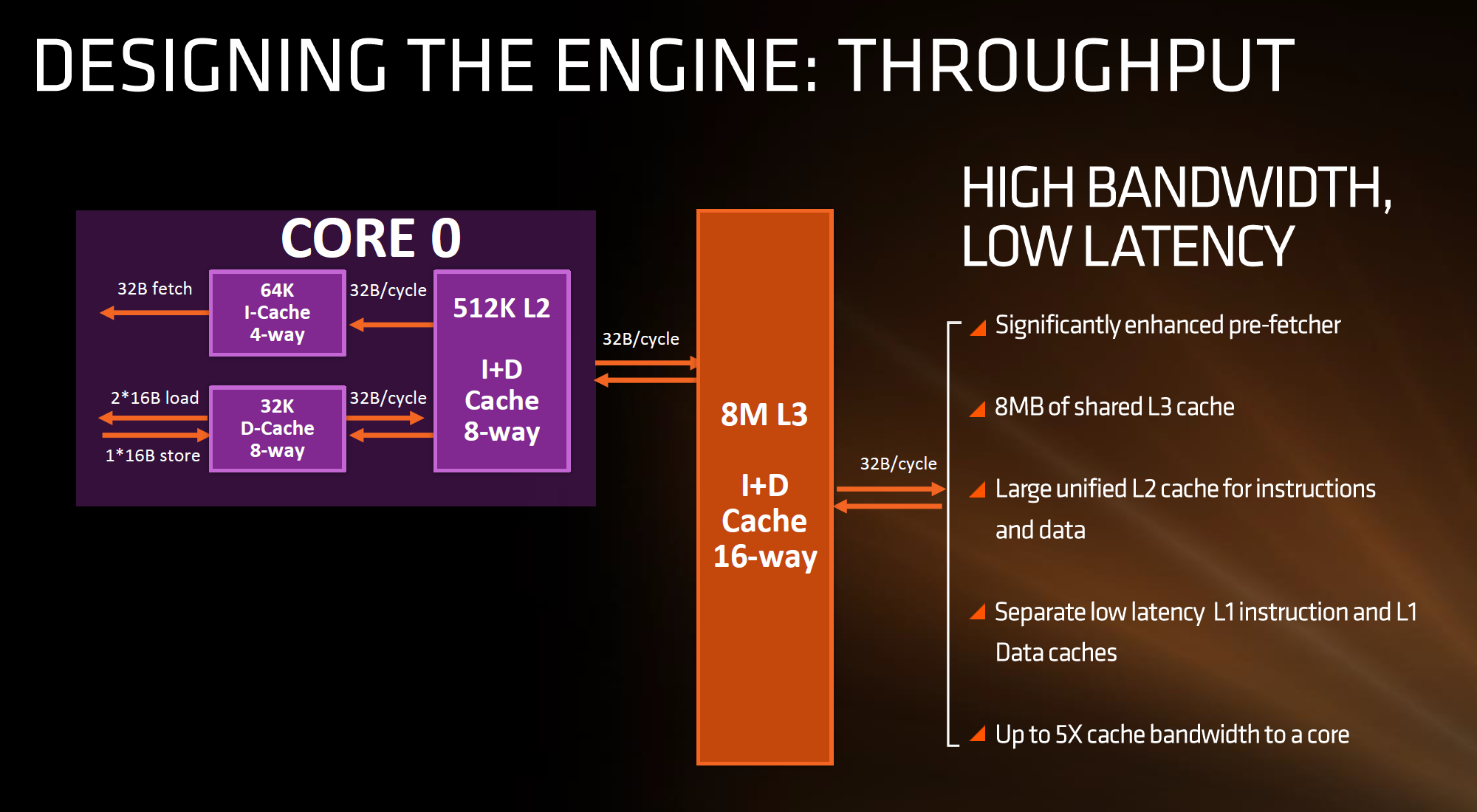
The cache hierarchy is a significant deviation from recent previous AMD designs, and most likely to its advantage. The L1 data cache is both double in size and increased in associativity compared to Bulldozer, as well as being write-back rather than write-through. It also uses an asymmetric load/store implementation, identifying that loads happen more often than stores in the critical paths of most work flows. The instruction cache is no longer shared between two cores as well as doubling in associativity, which should decrease the proportion of cache misses. AMD states that both the L1-D and L1-I are low latency, with details to come.
The L2 cache sits at half a megabyte per core with 8-way associativity, which is double that of Intel’s Skylake which has 256 KB/core and is only 4-way. On the other hand, Intel’s L3/LLC on their high-end Skylake SKUs is at 2 MB/core or 8 MB/CPU, whereas Zen will feature 1 MB/core and both are at 16-way associativity.
Edit 7:18am: Actually, the slide above is being slightly evasive in its description. It doesn't say how many cores the L3 cache is stretched over, or if there is a common LLC between all cores in the chip. However, we have recieved information from a source (which can't be confirmed via public AMD documents) that states that Zen will feature two sets of 8MB L3 cache between two groups of four cores each, giving 16 MB of L3 total. This would means 2 MB/core, but it also implies that there is no last-level unified cache in silicon across all cores, which Intel has. The reasons behind something like this is typically to do with modularity, and being able to scale a core design from low core counts to high core counts. But it would still leave a Zen core with the same L3 cache per core as Intel.
| Cache Levels | ||||
| Bulldozer FX-8150 |
Zen | Broadwell-E i7-6950X |
Skylake i7-6700K |
|
| L1 Instruction | 64 KB 2-way per module |
64 KB 4-way | 32 KB 8-way | 32 KB 8-way |
| L1 Data | 16 KB 4-way Write Through |
32 KB 8-way Write Back |
32 KB 8-way Write-Back |
32 KB 8-way Write-Back |
| L2 | 2 MB 16-way per module |
512 KB 8-way | 256 KB 8-way | 256 KB 4-way |
| L3 | 1 MB/core 64-way |
1 or 2 MB/core ? 16-way |
2.5 MB/core 16/20-way |
2 MB/core 16-way |
What this means, between the L2 and the L3, is that AMD is putting more lower level cache nearer the core than Intel, and as it is low level it becomes separate to each core which can potentially improve single thread performance. The downside of bigger and lower (but separate) caches is how each of the cores will perform snoop in each other’s large caches to ensure clean data is being passed around and that old data in L3 is not out-of-date. AMD’s big headline number overall is that Zen will offer up to 5x cache bandwidth to a core over previous designs.








216 Comments
View All Comments
looncraz - Thursday, August 18, 2016 - link
Really, this design is like nothing Intel has.Intel uses a unified scheduler, and it looks from the diagram that AMD is using seven schedulers... which is just insane. Beyond both using SMT schemes and executing x86, they are very different designs.
e36Jeff - Thursday, August 18, 2016 - link
Just a quick FYI, Intel is licencing the SMT technology from Sun, as they hold the US patents for it. So Intel, just like AMD, is copying Sun.svan1971 - Thursday, August 18, 2016 - link
Wow that was a hell of a burn on AMD zingy....Nothing better than routing for Goliath huh.farmergann - Thursday, August 18, 2016 - link
Zen is actually an enlarged evolution of the Jag Cores with doubled up pipelines and SMT. Don't take my word for it either, study the link below and pay attention to what we learn about Zen. Jag/Puma+ are actually better Cores than their intel competitors despite a huge node disadvantage. AMD is back.http://www.realworldtech.com/jaguar/
msx68k - Thursday, August 18, 2016 - link
AMD did not copy anything from Intel, because Intel did not invent the SMT technique. The SMT was developed by IBM in '60, while CMT was by DEC in '90, and both are processor design techniques, something like Risc or CISC.The_Countess - Friday, August 19, 2016 - link
like intel copied the short pipeline of the athlon64, the on die memory controller, and the larger l1 and l2 caches, in addition to the already mentioned AMD64.medi03 - Friday, August 19, 2016 - link
That's one silly statement.That's the way progress works. When there is a good idea to (re-)use, you do it. Nothing wrong with it.
stimudent - Friday, August 19, 2016 - link
Think or research about what you're about to say before posting.SanX - Friday, August 19, 2016 - link
Doubt about that. Somebody is just pumping AMD stock. Typical bluff, none of these 200 journos have a clue about all these cache speed exchange etc, they understand only cash speed exchange. The 40% increase in processor performance they claim will actually be 20% or even 10%. And compared to Intel in 2017 - 0%. You can not jump factor of 2 anymore, the Moore's law is dead. And 10-20% difference in computing means EQUAL, and all that Zen noise means NOTHING.looncraz - Friday, August 19, 2016 - link
In order for the feat they demonstrated to be real, they had to have exceeded 40% IPC over Excavator, unless their SMT is scaling unusually well.FX-8350 at 3Ghz would take well more than twice as long. Even the FX-8350 at 4GHz would probably take twice as long.