Ten Year Anniversary of Core 2 Duo and Conroe: Moore’s Law is Dead, Long Live Moore’s Law
by Ian Cutress on July 27, 2016 10:30 AM EST- Posted in
- CPUs
- Intel
- Core 2 Duo
- Conroe
- ITRS
- Nostalgia
- Time To Upgrade
Core: Load Me Up
When discussing the size of the reorder buffer, I mentioned that for some ops relying on the data of others, the order in which they need to be processed has to remain consistent – the load for the second op has to follow the store from the first in order for the calculation to be correct. This works for data that is read from and written to the same location in the same data stream, however with other operations, the memory addresses for loads and stores are not known until they pass the address generation units (AGUs).
This makes reordering a problem at a high level. You ultimately do not want a memory location to be written and stored by two different operations at the same time, or for the same memory address to be used by different ops while one of those ops is sitting in the reorder queue. When a load micro-op enters the buffer, the memory addresses of previous stores are not known until they pass the AGUs. Note, that this applies to memory addresses in the caches as well as main memory. However, if one can speed up loads and load latency in the buffers, this typically has a positive impact in most software scenarios.
With Core, Intel introduced a ‘New Memory Disambiguation’. For lack of a better analogy, this means that the issue of loads preceding stores is given a ‘do it and we’ll clean up after’ approach. Intel stated at the time that the risk that a load will load a value out of an address that is being written to by a store that has yet to be finished is pretty small (1-2%), and the chance decreases with larger caches. So by allowing loads to go head of stores, this allows a speedup but there has to be a catch net for when it goes wrong. To avoid this, a predictor is used to help. The dynamic alias predictor tries to spot this issue. If it happens, the load will have to be repeated, with a penalty of about 20-cycles.
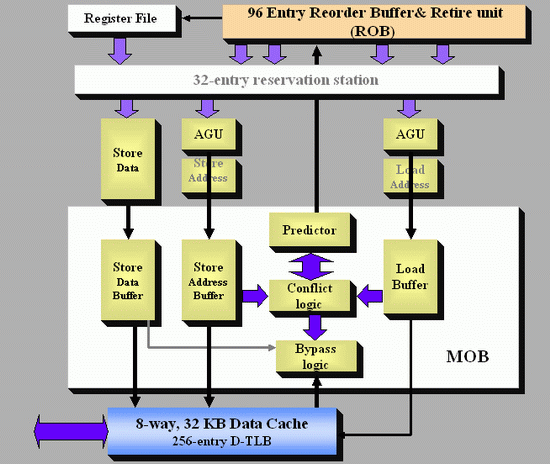
Unofficial AnandTech Diagram
The predictor gives permission for a load to move ahead of a store, and after execution the conflict logic scans the buffer in the Memory reOrder Buffer (MOB) to detect an issue. If it happens, then the load is reprocessed back up the chain. In the worst case scenario, this might reduce performance, but as Johan said back in 2006: ‘realistically it is four steps forward and one step back, resulting in a net performance boost’.
Using this memory disambiguation technique, Intel reported a 40% performance boost purely on allowing loads to be more flexible in a number of synthetic loads (or 10-20% in real world), along with L1 and L2 performance boosts. It is worth noting that this feature affects INT workloads more often than FP workloads, purely on the basis that FP workloads tend to be more ordered by default. This is why AMD’s K8 lost ground to Intel on INT workloads, despite having a lower latency memory system and more INT resources, but stayed on track with FP.
Core: No Hyper-Threading, No Integrated Memory Controller
In 2016, HT and an integrated memory controller (IMC) are now part of the fundamental x86 microarchitecture in the processors we can buy. It can be crazy to think that one of the most fundamental upticks in x86 performance in the last decade lacked these two features. At the time, Intel gave reasons for both.
Simultaneous Hyper-Threading, the act of having two threads funnel data through a single core, requires large buffers to cope with the potential doubling of data and arguably halves resources in the caches, producing more cache pressure. However, Intel gave different reasons at the time – while SMT gave a 40% performance boost, it was only seen as a positive by Intel in server applications. Intel said that SMT makes hotspots even hotter as well, meaning that consumer devices would become power hungry and hot without any reasonable performance improvement.
On the IMC, Intel stated at the time that they had two options: an IMC, or a larger L2 cache. Which one would be better is a matter for debate, but Intel in the end went with a 4 MB L2 cache. Such a cache uses less power than an IMC, and leaving the IMC on the chipset allows for a wider support range of memory types (in this case DDR2 for consumers and FB-DIMM for servers). However, having an IMC on die improves memory latency significantly, and Intel stated that techniques such as memory disambiguation and improved prefetch logic can soak up this disparity.
As we know know, on-die IMCs are the big thing.








158 Comments
View All Comments
Jon Tseng - Wednesday, July 27, 2016 - link
Great chip. Only just upgraded from my QX6850 last month. Paired with a GTX 970 it was doing just fine running all new games maxed out at 1080p. Amazing for something nearly a decade old!!Negative Decibel - Wednesday, July 27, 2016 - link
my E6600 is still kicking.tarqsharq - Wednesday, July 27, 2016 - link
My dad still uses my old E8400 for his main PC. He's getting my old i7-875k soon though.jjj - Wednesday, July 27, 2016 - link
You can't do DRAM in glasses, not in a real way. Since that's what mobile is by 2025.On-package DRAM is next year or soon not 2025.
You can't have big cores either and you need ridiculous GPUs and extreme efficiency. Parallelism and accelerators, that's where computing needs to go, from mobile to server.
We need 10-20 mm3 chips not 100cm2 boards. New NV memories not DRAM and so on.
Will be interesting to see who goes 3D first with logic on logic and then who goes 3D first as the default in the most advanced process.
At the end of the day, even if the shrinking doesn't stop, 2D just can't offer enough for the next form factor. Much higher efficiency is needed and the size of a planar chip would be far too big to fit in the device while the costs would be mad.Much more is needed. For robots too.The costs and efficiency need to scale and with planar it's at best little.
wumpus - Thursday, August 4, 2016 - link
On package DRAM seems to be a "forever coming" tech. AMD Fury-X basically shipped it, and it went nowhere. I'm guessing it will be used whenever Intel or IBM feel it can be used for serious advantage on some high-core server chip, or possibly when Intel want to build a high-speed DRAM cache (with high-speed-bus) and use 3dXpoint for "main memory".The slow rollout is shocking. I'm guessing nvidia eventually gave up with it and went with tiling (see the Kanter demo on left, but ignore the thread: nothing but fanboys beating their chests).
willis936 - Wednesday, July 27, 2016 - link
I'm certainly no silicon R&D expert but I'm very skeptical of those projections.Mr.Goodcat - Wednesday, July 27, 2016 - link
Typo:"On the later, we get the prediction that 450nm wafers should be in play at around 2021 for DRAM"
450nm wafers would be truly interesting ;-)
wumpus - Thursday, August 4, 2016 - link
I like the rapidly falling static safety. Don't breathe on a 2030 chip.faizoff - Wednesday, July 27, 2016 - link
My first Core 2 Duo was an E4400 that I bought in 2007 I believe, thing lasted me up to 2011 when I upgraded to an i5 2500k. I should've kept that C2D just for nostalgia's sake, I used it intermittently as a plex server and that thing worked great on FreeNAS. The only issue was it was really noisy and would get hot.Notmyusualid - Thursday, July 28, 2016 - link
I've got a few old servers kicking around, all with valid Win server licenses, but due to UK electricity costs, just can't bring myself to have them running at home 24/7 just to serve a backup, or yet another Breaking Bad viewing session... :) which we can do locally now.