Ten Year Anniversary of Core 2 Duo and Conroe: Moore’s Law is Dead, Long Live Moore’s Law
by Ian Cutress on July 27, 2016 10:30 AM EST- Posted in
- CPUs
- Intel
- Core 2 Duo
- Conroe
- ITRS
- Nostalgia
- Time To Upgrade
Core: Out of Order and Execution
After Prefetch, Cache and Decode comes Order and Execution. Without rehashing discussions of in-order vs. out-of-order architectures, typically a design with more execution ports and a larger out-of-order reorder buffer/cache can sustain a higher level of instructions per clock as long as the out-of-order buffer is smart, data can continuously be fed, and all the execution ports can be used each cycle. Whether having a super-sized core is actually beneficial to day-to-day operations in 2016 is an interesting point to discuss, during 2006 and the Core era it certainly provided significant benefits.
As Johan did back in the original piece, let’s start with semi-equivalent microarchitecture diagrams for Core vs. K8:
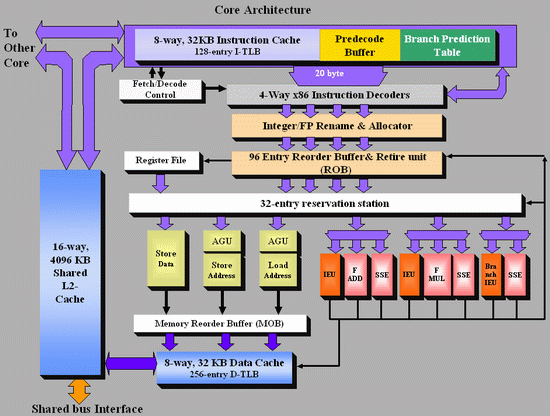
Intel Core
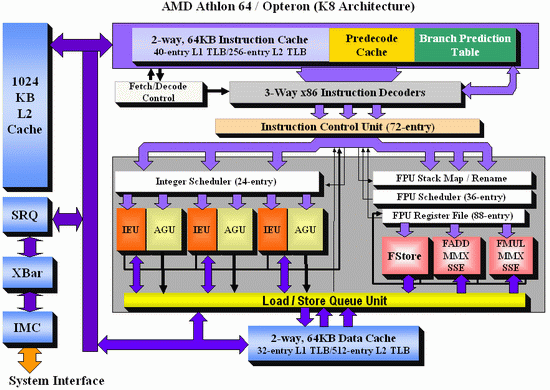
AMD K8
For anyone versed in x86 design, three differences immediately stand out when comparing the two. First is the reorder buffer, which for Intel ranks at 96 entries, compared to 72 for AMD. Second is the scheduler arrangement, where AMD uses split 24-entry INT and 36-entry FP schedulers from the ‘Instruction Control Unit’ whereas Intel has a 32-entry combined ‘reservation station’. Third is the number of SSE ports: Intel has three compared to two from AMD. Let’s go through these in order.
For the reorder buffers, with the right arrangement, bigger is usually better. Make it too big and it uses too much silicon and power however, so there is a fine line to balance between them. Also, the bigger the buffer it is, the less of an impact it has. The goal of the buffer is to push decoded instructions that are ready to work to the front of the queue, and make sure other instructions which are order dependent stay in their required order. By executing independent operations when they are ready, and allowing prefetch to gather data for instructions still waiting in the buffer, this allows latency and bandwidth issues to be hidden. (Large buffers are also key to simultaneous multithreading, which we’ll discuss in a bit as it is not here in Core 2 Duo.) However, when the buffer has the peak number of instructions being sent to the ports every cycle already, having a larger buffer has diminishing returns (the design has to keep adding ports instead, depending on power/silicon budget).
For the scheduler arrangements, using split or unified schedulers for FP and INT has both upsides and downsides. For split schedulers, the main benefit is entry count - in this case AMD can total 60 (24-INT + 36-FP) compared to Intel’s 32. However, a combined scheduler allows for better utilization, as ports are not shared between the split schedulers.
The SSE difference between the two architectures is exacerbated by what we’ve already discussed – macro-op fusion. The Intel Core microarchitecture has 3 SSE units compared to two, but also it allows certain SSE packed instructions to execute within one instruction, due to fusion, rather than two. Two of the Intel’s units are symmetric, with all three sporting 128-bit execution rather than 64-bit on K8. This means that K8 requires two 64-bit instructions whereas Intel can absorb a 128-bit instruction in one go. This means Core can outperform K8 on 128-bit SSE on many different levels, and for 64-bit FP SSE, Core can do 4 DP per cycle, whereas Athlon 64 can do 3.
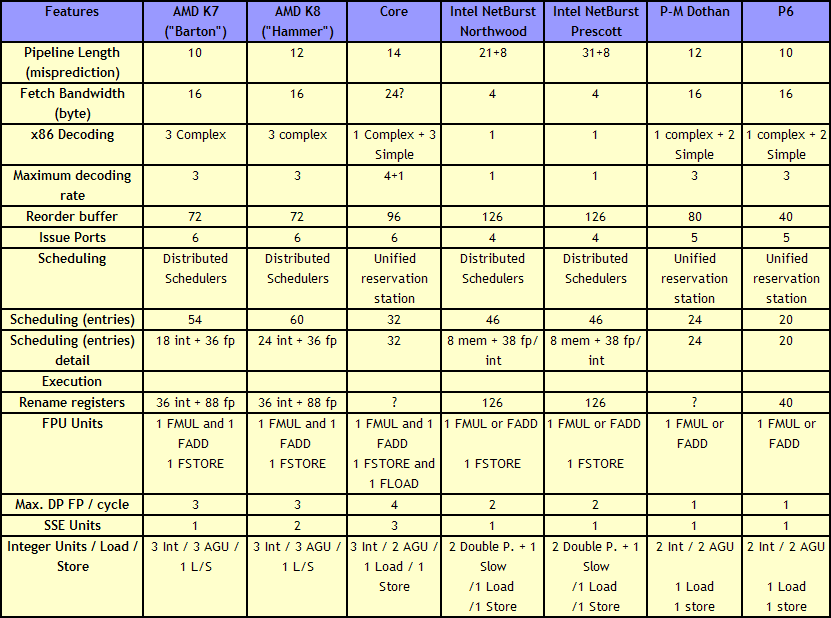
One other metric not on the diagram comes from branch prediction. Core can sustain one branch prediction per cycle, compared to one per two cycles on previous Intel microarchitectures. This was Intel matching AMD in this case, who already supported one per cycle.








158 Comments
View All Comments
Dobson123 - Wednesday, July 27, 2016 - link
I'm getting old.3ogdy - Wednesday, July 27, 2016 - link
That's what I thought about when I read "TEN year anniversary". It certainly doesn't feel like it was yesterday...but it certainly feels as old as "last month" is in my mind and that's mostly thanks to i7s, FXs, IPS, SSDs and some other things that proved to be more or less of a landmark in tech history.close - Thursday, July 28, 2016 - link
I just realized I have an old HP desktop with a C2D E6400 that will turn 10 in a few months and it's still humming along nicely every day. It ran XP until this May when I switched it to Win10 (and a brand new SSD). The kind of performance it offers in day to day work even to this day amazes me and sometimes it even makes me wonder why people with very basic workloads would buy more expensive stuff than this.junky77 - Thursday, July 28, 2016 - link
marketing, misinformation, lies and the need to feel secure and have something "better"Solandri - Friday, July 29, 2016 - link
How do you think those of us old enough to remember the 6800 and 8088 feel?JimmiG - Sunday, July 31, 2016 - link
Well my first computer had a 6510 running at 1 MHz.Funnily enough, I never owned a Core 2 CPU. I had an AM2+ motherboard and I went the route of the Athlon X2, Phenom and then Phenom II before finally switching to Intel with a Haswell i7.
Core 2 really changed the CPU landscape. For the first time in several years, Intel firmly beat AMD in efficiency and raw performance, something AMD has still not recovered from.
oynaz - Friday, August 19, 2016 - link
We miss or C64s and AmigasArtShapiro - Tuesday, August 23, 2016 - link
What about those of us who encountered vacuum tube computers?AndrewJacksonZA - Wednesday, July 27, 2016 - link
I'm still using my E6750... :-)just4U - Thursday, July 28, 2016 - link
I just retired my dads E6750. It was actually still trucking along in a Asus Nvidia board that I had figured would be dodgy because the huge aluminum heatsink on the chipset was just nasty.. Made the whole system a heatscore. Damned if that thing didn't last right into 2016. Surprised the hell out of me.