Assessing IBM's POWER8, Part 1: A Low Level Look at Little Endian
by Johan De Gelas on July 21, 2016 8:45 AM ESTMemory Subsystem: Bandwidth
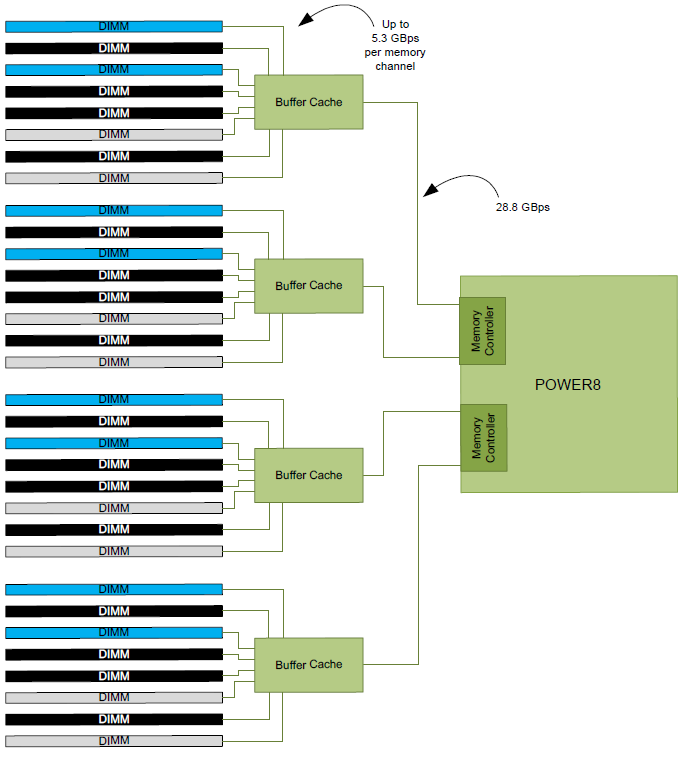
As we mentioned before, the IBM POWER8 has a memory subsystem which is more similar to the Xeon E7's than the E5's. The IBM POWER8 connects to 4 "Centaur" buffer cache chips, which have both a 19.2 GB/s read and 9.6 GB/s write link to the processor, or 28.8 GB/s in total. So the 105 GB/s aggregate bandwidth of the POWER8 is not comparable to Intel's peak bandwidth. Intel's peak bandwidth is the result of 4 channels of DDR4-2400 that can either write or read at 76.8 GB/s (2.4 GHz x 8 bytes per channel x 4 channels).
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2.1 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array sizes which are not cacheable by the Xeons' huge L3 caches.
It is important to note why we use the GCC compiler and not vendors' specialized compilers: the GCC compiler is not as good at vectorizing the code. Intel's ICC compiler does that very well, and as result shows the bandwidth available to highly optimized HPC code, which is great for that code in the real world, but it's not realistic for multi-threaded server applications.
With ICC, Intel can use the very wide 256-bit load units to their full potential and we measured up to 65 GB/s per socket. But you also have to consider that ICC is not free, and GCC is much easier to integrate and automate into the daily operations of any developer. No licensing headaches, no time consuming registrations.
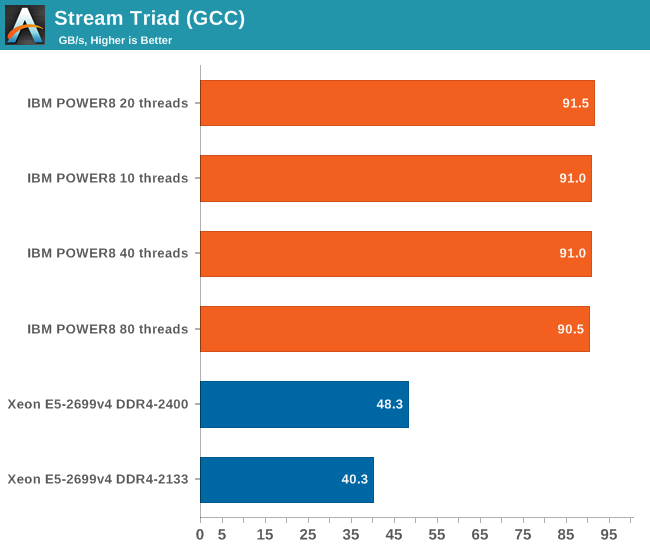
The combination of the powerful four load and two store subsystem of the POWER8 and the read/write interconnect between the CPU and the Centaur chips makes it much easier to offer more bandwidth. The IBM POWER8 delivers a solid 90 GB/s despite using old DDR3-1333 memory technology.
Intel claims higher bandwidth numbers, but those numbers can only be delivered in vectorized software.








124 Comments
View All Comments
nobodyblog - Thursday, July 21, 2016 - link
Please correct this error, you are saying you are comparing with BEST Intel can provide, but you did address Xeon for workloads need Xeon Phi Knight Landing which is a standalone CPU, too. If you choose correctly, the benchmark will be sooo different.IBM Power 8 is 90 GB/s, while Intel's Xeon phi knight landing (as 7290F) has a bandwidth of 400 GB/s.
IBM power 8 does above 600 gflops single precision and above 300 gflops double precision FLOPs, this is *10 in Xeon phi 7290F.
Specint: xeon phi is 1500 vs 1700 for power 8
Power and Price aside....
Thanks!
LukaP - Thursday, July 21, 2016 - link
If we start comparing different product categories, why not bring the GP100 into this as well. It will deliver 10TFLOPS of single precision and can be had for much less than any of these. But then again, there is the same caveat as the Xeon Phi. You cant actually run an OS on it, you need a host CPU and then you dispatch kernels onto the accelerator. Even if its a socketed version.smilingcrow - Thursday, July 21, 2016 - link
You can boot from newer Xeon Phi; either current or the next generation due maybe this year!LukaP - Thursday, July 21, 2016 - link
Oh really? :o that is neat, though not sure if that useful, since even highly parallel tasks usually have some IPC dependent components...Anyways have you got a source for that, would love to read more
Drumsticks - Thursday, July 21, 2016 - link
I'm a verification intern on the Phi team right now, and you can indeed boot Knight's Landing! Anandtech mentions it here: http://www.anandtech.com/show/9802/supercomputing-...nobodyblog - Friday, July 22, 2016 - link
Then you can add another xeon phi to above statistics... Xeon Phi KL is a CPU like other CPUs it does everything as mentioned even its specint is comparable, not so bad...Thanks!
tipoo - Friday, July 22, 2016 - link
Xeon Phi is x86, but it's GPU-like in nature, massively parallel for performance with low per-core performance. The IBM Power8 and other Xeons compete in highly parallel spaces like banking, but where single thread performance also still matters. Can't compare them.nobodyblog - Friday, July 22, 2016 - link
Xeon Phi Knight Landing has 3 times more single thread performance than silvermont (& knight corner).. I don't think it is so bad...The comparison is truly so, see the benchmarks, they say specint for example, or anything parallel performance, additionally, you can use a Xeon high performance with a xeon phi, there is nothing that prevents you. The benchmark is not about Database performance or parsing or anything similar, it is about this article, I don't say xeon phi is currently better positioned than xeon in these uses... But IBM's Power is not so, too, it has lots of core and lots of threads which is usable only in massive parallel uses...
Thanks!
nobodyblog - Friday, July 22, 2016 - link
On the IBM server, numactl was used to physically bind the 2, 4, or 8 copies of SPEC CPU to the first 2, 4, or 8 threads of the first core. On the Intel server, the 2 copy benchmark was bound to the first core. It is not single thread, it is a trick IBM uses to cheat in benchmarks, it is 425% percents slower than xeon in single thread.Thanks!
jospoortvliet - Tuesday, July 26, 2016 - link
The benchmarks here pit one core against one core. The IBM cores can run 1, 2, 4 or 8 threads on a single core, the Intel does 1 or 2. The 425%, not sure where that number comes from, but it isn't what shows out of these benchmarks.The benchmarks show, as described by Johan:
In single thread, the IBM does about 13% less work than the Intel core. In 2-thread mode, the IBM does about 20% more than the intel across the two threads. The intel doesn't do more than 2 threads, the IBM can and does then, on average, 43% more work across the eight threads than the Intel does with its two.
So Intel is single-thread master here, IBM is throughput king. Now if you have a HEAVILY threaded workload, with hundreds of threads and little latency requirements for each, Knights Landing or a GPU is a better choice, with their hundreds of cores. If latency is important and you can afford to use two to four threads per core the IBM performs best. If latency is everything, you keep it at 1 thread per core and the Intel Xeon is the best performer.
That is entirely ignoring cost, of course, both Intel and IBM have high and low cost solutions with their downsides and benefits. This set of benchmarks simply pitted one core against another, entirely ignoring the differences in core count (IBM 10, Intel 22) and price (Intel orders of magnitude more expensive). You'll always have to look at a bigger picture: how many cores do you get for your dollar and what are your requirements.
Performance/watt, the Intel probably wins in all area's, at least if the system is idle frequently. Without idle the IBM might be not that bad, perf/power wise.
The big take-away from this article is, though, that IBM has built a system which can be quite price-competitive with Intel in the lower-high end market. To really be able to make a choice, we'd probably need a benchmark of two price-equivalent systems. I bet the workload would make a huge difference in who wins the price/performance fight.