Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs
A Closer Look at the Server Node
We’ve arrived at the heart of the server node: the SoC. Calxeda licensed ARM IP and built its own SoC around it, dubbed the Calxeda EnergyCore ECX-1000 SoC. This version is produced by TSMC at 40nm and runs at 1.1GHz to 1.4GHz.
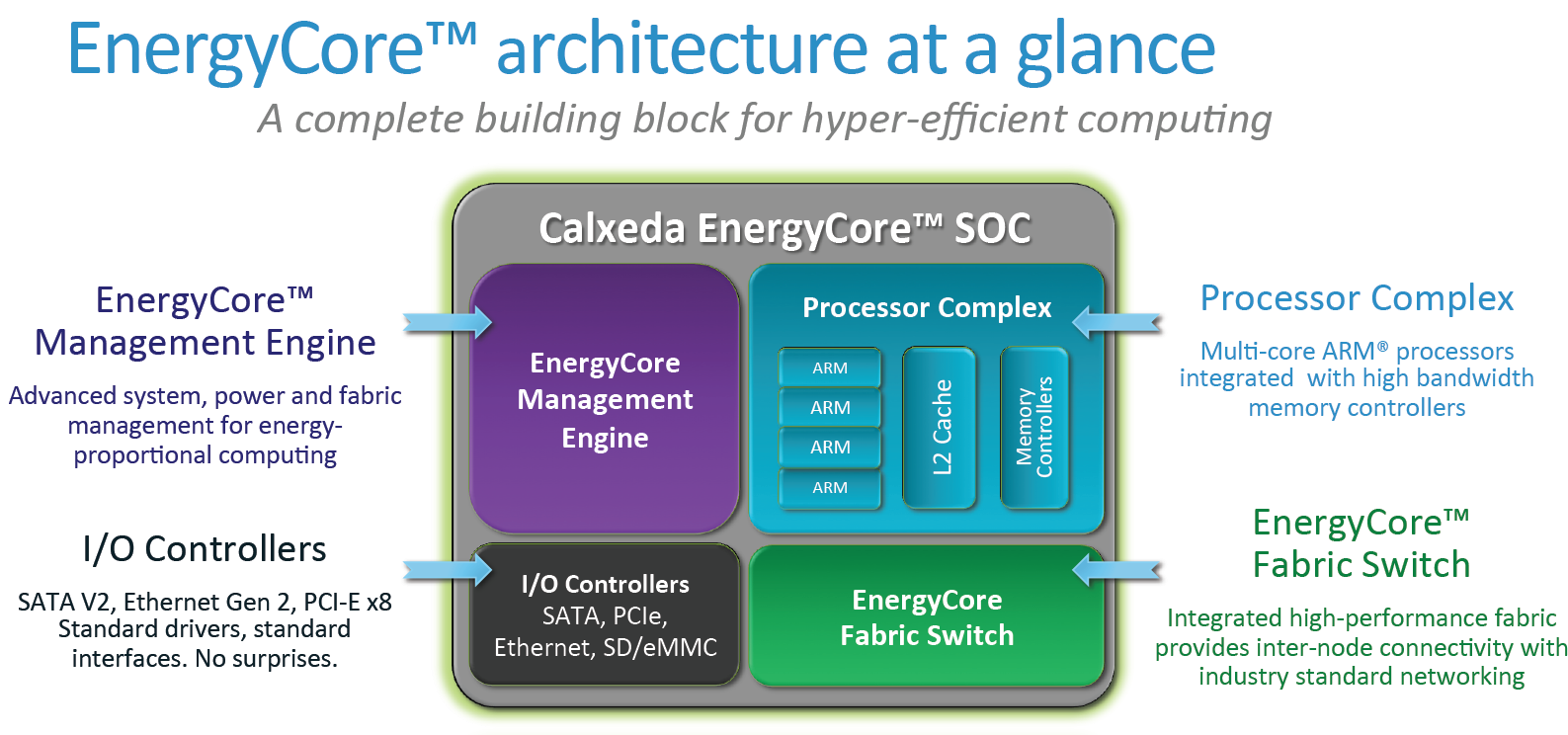
Let’s start with a familiar block on the SoC (black): the external I/O controller. The chip has a SATA 2.0 controller capable of 3Gb/s, a General Purpose Media Controller (GPMC) providing SD and eMMC access, a PCIe controller, and an Ethernet controller providing up to 10Gbit speeds. PCIe connectivity cannot be used in this system, but Calxeda can make custom designs of the "motherboard" to let customers attach PCIe cards if requested.
Another component we have to introduce before arriving at the actual processor is the EnergyCore Management Engine (ECME). This is an SoC in its own right, not unlike a BMC you’d find in conventional servers. The ECME, powered by a Cortex-M3, provides firmware management, sensor readouts and controls the processor. In true BMC fashion, it can be controlled via an IPMI command set, currently implemented in Calxeda’s own version of ipmitool. If you want to shell into a node, you can use the ECME's Serial-over-LAN feature, yet it does not provide any KVM-like environment; there simply is no (mouse-controlled) graphical interface.
The Processor Complex
Having four 32-bit Cortex-A9 cores, each with 32 KB instruction and 32 KB data L1 per-core caches, the processor block is somewhat similar to what we find inside modern smarphones. One difference is that this SoC contains a 4MB ECC enabled L2 cache, while most smartphone SoCs have a 1MB L2 cache.

These four Cortex-A9 cores operate between 1.1GHz and 1.4GHz, with NEON extensions for optimized SIMD processing, a dedicated FPU, and “TrustZone” technology, comparable to the NX/XD extension from x86 CPUs. The Cortex-A9 can decode two instructions per clock and dispatch up to four. This compares well with the Atom (2/2) but of course is nowhere near the current Xeon "Sandy Bridge" E5 (4/5 decode, 6 issue). But the real kicker for this SoC is its power usage, which Calxeda claims to be as low as 5W for the whole server node under load at 1.1GHz and only 0.5W when idling.
The Fabric
The last block in the Soc is the EC Fabric Switch. The EC Fabric switch is an 8X8 crossbar switch that links to five XAUI ports. These external links are used to connect to the rest of the fabric (adjacent server nodes and the SFPs) or to connect SATA 2 ports. The OS on top of server nodes sees two 10Gbit Ethernet interfaces.
As Calxeda advertises their offerings with scaling out as one of the major features, they have created fast and high volume links between each node. The fabric has a number of link topology options and specific optimizations to provide speed when needed or save power when the application does not need high bandwidth. For example, the links of the fabric can be set to operate at 1, 2.5, 5 and 10Gb/s.

A big plus for their approach is that you do not need expensive 10Gbit top-of-rack switches linking up each node; instead you just need to plug in a cable between two boxes making the fabric span across. Please note that this is not the same as in virtualized switches, where the CPU is busy handling the layer-2 traffic; the fabric switch is actually a physical, distributed layer-2 switch that operates completely autonomously—the CPU complex doesn’t need to be powered on for the switch to work.








99 Comments
View All Comments
tuxRoller - Tuesday, March 12, 2013 - link
Why WOULD you expect DVFS to boost performance?You seem to think it slightly revelational that the scores are slightly lower (but perhaps statistically meaningless).
dig23 - Tuesday, March 12, 2013 - link
On-demand seems fair choice to me, its what best you can do on this OSes. But I will be very interested to see energy efficiency numbers when DVFS working on swarm of ARM nodes...:)tuxRoller - Tuesday, March 12, 2013 - link
It's not cpu governor I'm talking about but DVFS in particular.There's bound to be some small amount of latency involved with the process.
It's point isn't for best performance but energy efficiency thus why I made the comment in the first place.
JarredWalton - Tuesday, March 12, 2013 - link
There's the potential for DVFS to optimize for better performance on a few cores while putting some of the other cores into a lower P-state, but I think that would be more for stuff like Turbo Boost/Turbo Core. It's also possible Johan is referring to the potential for the optimizations to simply improve performance in general.CodyHall - Friday, March 15, 2013 - link
Love my job, since I've been bringing in $5600… I sit at home, music playing while I work in front of my new iMac that I got now that I'm making it online.(Click Home information)http://goo.gl/9u8us
JohanAnandtech - Wednesday, March 13, 2013 - link
Can you tell me where I got you confused? Because I write "This allowed us to make use of Dynamic Voltage and Frequency Scaling (DVFS, P-states) using the CPUfreq tool. First let's see if all these power saving tweaks have reduced the total throughput."So it should been clear that we are looking for a better performance/watt ratio. The interesting thing to note is that ARM benefits from p-states, and that Intel's excellent implementation of C-states makes p-states almost useless.
Twonky - Wednesday, March 13, 2013 - link
For information about a year ago the following post on the Linkedin ARM Based Group gave a link to a M.Sc. thesis publishing figures on the performance/watt ratio for Cortex-A8 and Cortex-A9 based boards:www.linkedin.com/groups/Single-CortexA8-CortexA9-in-comparison-85447.S.84348310
AncientWisdom - Tuesday, March 12, 2013 - link
Very interesting read, thanks!staiaoman - Tuesday, March 12, 2013 - link
Damn, Johan. As always- an incredible writeup. Interesting thought experiment to figure that an upper bound on damage to INTC server share might be found by simply looking at how much of the market is running applications like your web server here (where single-threaded performance isn't as important).Intel powering phones and ARM chips in servers...the end is nigh.
JohanAnandtech - Thursday, March 14, 2013 - link
Thanks Staiaoman :-). I'll leave the though experiment to you :-)