ASUS NUC14RVHv7 and ASRock Industrial NUC BOX-155H Review: Meteor Lake Brings Accelerated AI to UCFF PCs
by Ganesh T S on May 23, 2024 8:00 AM EST- Posted in
- Systems
- Intel
- Asus
- NUC
- UCFF
- Mini-PC
- ASRock Industrial
- Meteor Lake
AI Performance: UL Procyon AI Workloads
Drafting a set of benchmarks relevant to end-user AI use-cases has proved to be a challenging exercise. While training workloads are common in the datacenter and enterprise space, consumer workloads are focused on inference. In early days, the inferencing used to run in the cloud, but increasing privacy concerns, as well as the penalties associated with constant cloud communication, have contributed to the rise in demand for local inferencing capabilities. Additionally, generative AI (such as chatbots and image generators based on input prompts) has also garnered significant interest in recent days. Currently, most of these large-language models (LLMs) run in the cloud, as they are still too resource-heavy to run with reasonable performance in the systems of average users.
UL's Procyon AI benchmarks focuses on these workloads from an edge computing perspective. Broadly speaking, the benchmark is divided into two major components:
- Computer Vision (inference performance using six different neural network models)
- Generative AI (image generation using the Stable Diffusion LLM)
An attempt was made to process both benchmarks on the ASUS NUC14RVHv7 (Revel Canyon vPro) as well as the two configurations of the ASRock Industrial NUC BOX-155H as part of the evaluation of its capabilities as an "AI PC". The results are summarized in the remainder of this section.
Computer Vision Neural Networks Performance
The six supported neural networks were benchmarked with the following configurations:
- OpenVINO CPU with float32 precision
- OpenVINO GPU with float16 precision
- OpenVINO GPU with float32 precision
- OpenVINO GPU With integer precision
- OpenVINO NPU with float16 precision
- OpenVINO NPU with integer precision
- WinML GPU with float16 precision
- WinML GPU with float32 precision
- WinML GPU with integer precision
The OpenVINO configurations can be evaluated only on systems with an Intel CPU or GPU or NPU. In general, a neural network model's accuracy / quality of results improves with precision. In other words, we expect float16 to deliver better results than integer, and float32 to be better than float16. However, increased precision requires more complex calculations and that results in higher power consumption. As general purpose engines, the CPU is expected to be the most power hungry of the lot, while the NPUs which are purpose-built for neural network acceleration are expected to be better than the GPU configurations. UL has a detailed study of the variation in the quality of results with precision for different networks in their benchmark resources section.
The YOLO V3 network is used for real-time object detection in videos. The graphs below show that at the same precision, OpenVINO performs better than WinML on the GPU. Additionally, for the same precision, OpenVINO performs better on the GPU rather than the NPU.
| UL Procyon AI - YOLO V3 Average Inference Time | |||

The REAL ESRGAN network is used for upscaling images / restoration of videos and pictures. Relative performance for different precisions / execution hardware is similar to what was seen for the YOLO V3 network.
| UL Procyon AI - REAL ESRGAN Average Inference Time | |||

The ResNet 50 network is primarily used for image classification. Again, we see the NPU being slower than the GPU at the same precision, while WinML lags behind OpenVINO for the same underlying execution hardware and precision.
| UL Procyon AI - ResNet 50 Average Inference Time | |||

The MobileNet V3 network is used, among other things, for image processing tasks such as tilt correction. Similar to the other networks, WinML again lags behind OpenVINO. However, the NPU is faster than the GPU for the same precision network.
| UL Procyon AI - MobileNet V3 Average Inference Time | |||

The Inception V4 network, like the ResNet 50, is primarily used for image classification. Similar to most other networks, WinML performance is not as good as with OpenVINO, and the NPU is slower than the GPU for the same precision.
| UL Procyon AI - Inception V4 Average Inference Time | |||

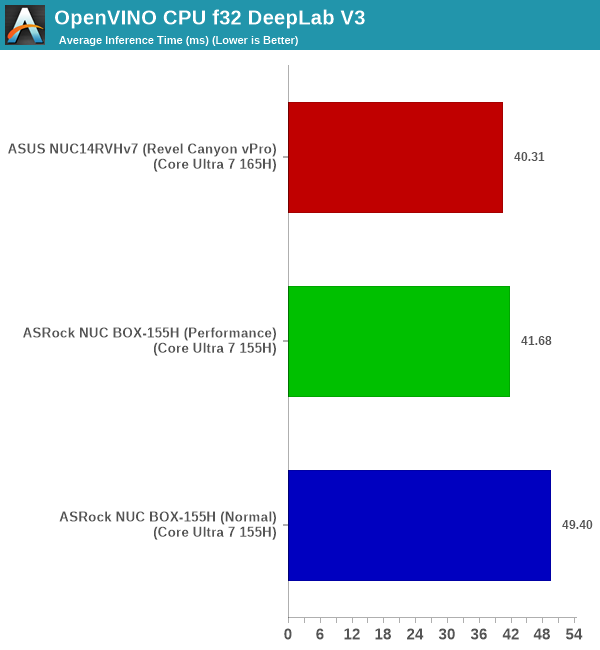
The DeepLab V3 network is used for image segmentation. In other words, it identifies groups of pixels in an image that satisfies specific requirements. The NPU is almost 4x slower than the GPU for the same precision and network. OpenVINO continues to perform better than WinML for the same precision network/
| UL Procyon AI - DeepLab V3 Average Inference Time | |||
The UL Procyon AI Computer Vision benchmark run processes each model for 3 minutes, maintaining a count of inferences as well as the average time taken for each inference. It presents an overall score for all six models together, though it is possible that some networks perform better than others for the same hardware / precision configuration.
| UL Procyon AI - Computer Vision Inferencing Overall Scores | |||
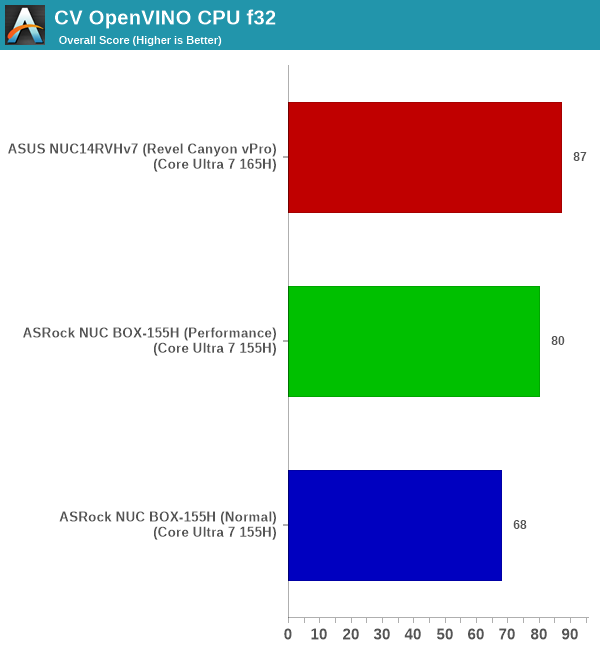
The Revel Canyon NUC comes out on top in the CPU-only OpenVINO run with float32 precision. For the OpenVINO GPU runs, the NUC BOX-155H manages to sneak in a slight lead over the other systems. Finally, WinML performance is quite bad compared to OpenVINO.
The benchmark runs for a fixed time. Hence, instead of tracking energy consumption, we opt to report the average at-wall power consumption for the system as a whole for each run set.
| UL Procyon AI - Computer Vision Average Power Consumption | |||
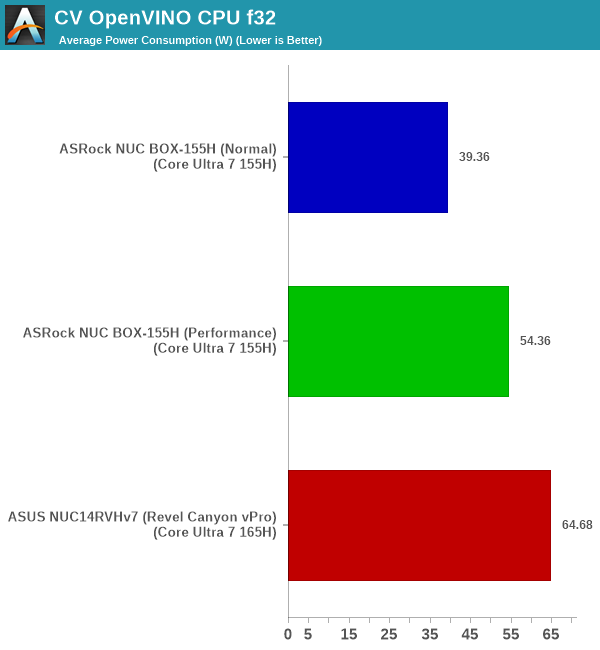
As expected, the NPU is the most power-efficient of the lot. Higher precision translates to higher power consumption, and CPU mode is the least power-efficient.
Generative AI Performance
The Stability Diffusion prompt used for benchmarking in UL Procyon AI generates 16 different images. However, on all three system configurations, the benchmark crashed after generating 3 or 4 images. This benchmark is meant for high-end systems with discrete GPUs, and hence we didn't bother to follow up on the crashes.
As we get more systems processed with the UL Procyon AI benchmark, an attempt will be made to get the Generative AI benchmark working on them.








14 Comments
View All Comments
meacupla - Thursday, May 23, 2024 - link
I suspected it would work fine as a mini-PC.Asus' implementation hitting 100c under load is disappointing, but that's on Asus for not equipping it with adequate cooling. Reply
shabby - Thursday, May 23, 2024 - link
Don't forget to blame intel for letting a mobile chip run at 115w. Replymeacupla - Thursday, May 23, 2024 - link
With all the recent power limit and stability controversy, my money is on Asus being the worse offender. It's entirely up to the OEM if they want to use 115W or not.AsRock's implementation doesn't hit 100c. Reply
shabby - Thursday, May 23, 2024 - link
Yes it does, keep reading further. ReplyTheinsanegamerN - Friday, May 24, 2024 - link
Intels reputation for being hot and slow continues unabated. ReplyJames5mith - Thursday, May 23, 2024 - link
According to the color coding on the Jetstream graphs, Chrome/Edge were run on one of the NUCs, and Firefox on the other.You should probably try and keep those color codes consistent and matching what they are meant to match. Reply
wr3zzz - Friday, May 24, 2024 - link
This is an example of there are no bad products, only bad prices. Replypowerarmour - Sunday, May 26, 2024 - link
Oh there's definitely bad products too, like this. Replyionuts - Friday, May 24, 2024 - link
Why not use an USB-C PSU? ReplyTheinsanegamerN - Friday, May 24, 2024 - link
Because why would they when they have a ready supply of mini barrel power supplies? Reply