Workstation Graphics: AGP Cross Section 2004
by Derek Wilson on December 23, 2004 4:14 PM EST- Posted in
- GPUs
3Dlabs Wildcat Realizm 200 Technology
Fixed function processing may still be the staple of the workstation graphics world, but 3Dlabs isn't going to be left behind in terms of technology. The new Wildcat Realizm GPU supports everything that one would expect from a current generation graphics processor, including VS 2.0, and PS 3.0 level programmability. The hardware itself weighs in at about 150M transistors and is fabbed on a 130nm process. We're taking a look at the top end AGP SKU from 3Dlabs, but the highest end offering essentially places two of these GPUs on one board, connected by a vertex/scalability unit, but we'll take a look at that when we explore PCI Express workstations. The pipeline of the Wildcat Realizm 200 looks very much like what we expect a 3D pipeline to look.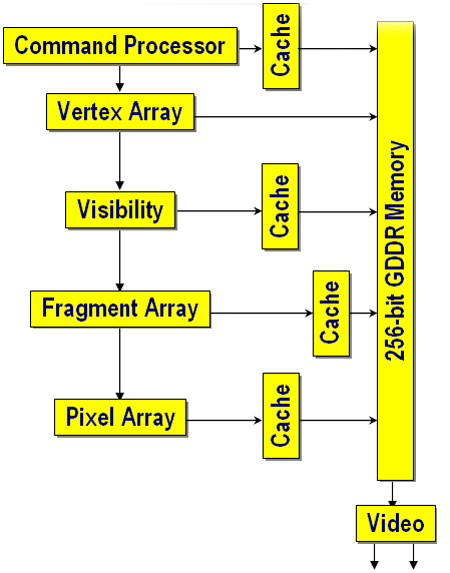
When we start to peel away the layers, we see a very straightforward and powerful architecture. We'll start by explaining everything, except for the Vertex Array and the Fragment Array (which will get a little more detailed investigation shortly).
The Command Processor is responsible for keeping track of command streams coming into the GPU. Of interest is the fact that it supports the NISTAT and NICMD registers for isochronous AGP operation. This allows the card to support requests by applications for a constant stream of data at guaranteed intervals. On cards without isochronous AGP support, cards must be capable of handling arbitrarily long delays in request fulfillment based on the capabilities of the chipset. This feature is particularly interesting for real-time broadcast video situations in which dropped frames are not an option. Of course, it only works with application support, and we don't have a good test as to the impact of isochronous AGP operation either.
Visibility is computed via a Hierarchical Z algorithm. Essentially, large tiles of data are examined at a time. If the entire tile is occluded, it can all be thrown out. 3Dlabs states that their visibility algorithm is able to discard up to 1024 multi-samples per clock. This would fit the math for a 16x16 pixel tile with 4x multi-samples per pixel. This is actually 256 pixels, which is the same size block as ATI's Hierarchical Z engine. And keep in mind, these are maximal numbers; if the tile is partially occluded, only part of the data can be thrown out.
What 3Dlabs calls the Pixel Array, it is circuitry that takes care of AA, compositing, color conversion, filtering, and everything else that might need to happen to the final image before scan out. This is similar in function, for example, to the ROP in an NVIDIA part. The Wildcat Realizm GPU is capable of outputting multiple formats from the traditional to fp16 data. This means that it can handle things like 10-bit alpha blending, or 10-bit LUT for monitors that support it. On the basic hardware level, 3Dlabs defines this block as a 16x 16-bit floating point SIMD array. This means that 4 fp16 RGBA pixels can be processed by the Pixel Array simultaneously. In fact, all the programmable processing parts of the Wildcat Realizm are referred to terms of SIMD arrays. This left us with a little math to compute based on the following information and this layout shot:
Vertex Array: 16-way, high-accuracy 36-bit float SIMD array, DX9 VS 2.0 capable
Fragment Array: 48-way, 32-bit float component SIMD array, DX9 PS 3.0 capable

For the Vertex Array, we have a 16x 36-bit floating point SIMD array. Since there are two physical Vertex Shader Arrays in the layout of the chip as shown above, and we are talking about SIMD (single instruction multiple data) arrays, it stands to reason that each array can handle 8x 36-bit components at maximum. It's not likely that this is one large 8-wide SIMD block. If 3Dlabs followed ATI and NVIDIA, they could organize this as one 6-wide unit and one 2-wide unit, executing two vec3 operations on one SIMD block and two scalar operations on the other. This would give them two "vertex pipelines" per array. Without knowing the granularity of the SIMD units, or how the driver manages allocating resources among the units, it's hard to say exactly how much work can get done per clock cycle. Also, as there are two physically separate vertex arrays, each half of the vertex processing block is likely to share resources like registers and caches. It is important to note that the vertex engine here is 36-bits wide. The extra 4 bits, which are above and beyond what anyone else offers, actually delivers 32-bits of accuracy in the final vertex calculation. Performing operations at the same accuracy level as the data stored essentially builds in a level of noise to the result. This is because intermediate results of calculations are truncated to the accuracy of the stored data. This is a desirable feature to maintain high precision vertex accuracy, but we haven't been able to come up with a real world application that pushes other parts to a place where 32-bit vertex hardware breaks down and the 36-bit hardware is able to show a tangible advantage.
The big step for vertex hardware accuracy will need to be 64-bit. For CAD/CAM applications, a db of 64-bit values is kept. These double values are very important for manufacturing, but currently, graphics hardware isn't robust enough to display anything but single precision floating point data. Already high transistor counts would get unmanageable with current fab technology.
Other notable features of the vertex pipeline of the Wildcat Realizm products include support for 32 hardware fixed function hardware lights, and VS 2.0 level functionality with a maximum of 1000 instructions. Not supporting VS 3.0 while implementing full PS 3.0 support is an interesting choice for 3Dlabs. Right now, fixed function support is more important to the CAD/CAM market and arguably more important to the workstation market overall. But, geometry instancing could really help geometry limited applications when working with scenes full of multiple objects. Vertex textures might also be useful in the DCC market. Application support does push hardware vendors to include and exclude certain features, but we really would have liked to see full SM 3.0 support in the Wildcat Realizm product line.
The Fragment Array consists of three physical blocks that make up a 48-way 32-bit floating point SIMD array. This means that we 16x 32-bit components being processed in each of the three physical blocks at any given time. What we can deduce from this is that each of the three physical blocks share common register and cache resources and very likely operate on four pixels with strong locality of reference at a time. It's possible that 3Dlabs could organize the distribution of pixels over their pipeline in a similar manner to either ATI or NVIDIA, but we don't have enough information to determine what's going on at a higher level. We also can't say how granular 3DLab's SIMD arrays are, which means that we don't know just how much work they can get done per clock cycle. In the worst case, the Wildcat Realizm is equipped with 4x 4-wide SIMD units per physical fragment block. This would mean that operating on one component at a time would make 3 components idle while waiting for the fourth. It's much more likely that they implemented a combination of smaller units and are able to divide the work among them, as both ATI and NVIDIA have done. We know that 3Dlabs units are all vector units, which means that we are limited to combinations of 2-, 3-, and 4-wide vector blocks.
Unfortunately, without more information, we can't draw conclusions on DX9 co-issue or dual-issue per pipeline capabilities of the part. No matter what resources are under the hood, it's up to the compiler and driver to handle the allocation of everything that the GPU offers to the GLSL or HLSL code running on it. On a side note, it is a positive sign to see a third company confirm the major design decisions that we have seen both ATI and NVIDIA make in their hardware. With the 3Dlabs Wildcat Realizm 200 coming to market as a 4 vertex/12 pixel pipe architecture, it will certainly be exciting to see how things stack up in the final analysis.
The Fragment Array supports PS 3.0 and 256000 instruction length shader programs. The Fragment Array also supports 32 textures in one clock. This, again, seems to be a total limitation per clock. The compiler would likely distribute resources as needed. If we look at this in the same way that we look at the ATI or NVIDIA hardware, we'd see that we can access 2.6 textures per pixel. This could also translate to 2/3 of the components loading their own texture if needed, and if the driver supported it. 3Dlabs also talks about the Wildcat Realizm's ability to handle "cascaded dependant textures" in shaders. Gracefully handling a large number of dependent textures is useful, but it will bring shader hardware to a crawl. It's unclear how many depth/stencil operations that the Realizm is capable of in one pass, but there is a separate functional block for such processing shown on the image above.
One very important thing to note is that the Wildcat Realizm calculates all pixel data in fp32, but stores pixel data in an fp16 (5s10) format. This has the effect of increasing memory bandwidth from what it would be with fp32, while decreasing accuracy. The precentage by which percision is decreased depends on the data being processed and algorithms used. The fp32->fp16 and fp16->fp32 conversions are all done with zero performance impact between the GPU and memory. It's very difficult to test the accuracy of the fragment engine. We've heard that it comes out somewhere near 30-bit accuracy from 3Dlabs, and it very well could. We would still like to see an empirical test that could determine the absolute accuracy for a handful of common shaders before we sign off on anything. This is at least an interesting solution to the problem of balancing a 32-bit and 16-bit solution. Moving all that pixel data can really impact bandwidth in shader intensive applications, and we saw just how hard the impact can be with NVIDIA's original 32-bit NV30 architecture. We've heard that it is possible to turn off the 16-bit storage feature and have the Realizm GPU store full 32-bit precision data, but we have yet to see this option in the driver or as a tweak. Obviously, we would like to get our hands on a switch like this to evaluate both the impact on performance and image quality.
Another important feature to mention about the Wildcat Realizm is its virtual memory support. The Realizm supports 16GB of virtual memory. This allows big memory applications to swap pages out of local graphics memory to system RAM if needed. On the desktop side, this isn't something that we've seen a real demand or need for, but workstation parts definitely benefit from it. Speed is absolutely useful, but more important than speed is actually being able to visualize a necessary data set. There are data sets and workloads that just can't fit in local framebuffers. The Wildcat Realizm 200 has 512 MB of local memory, but if needed, it could have swapped paged out up to the size of our free idle system memory. The 3Dlabs virtualization system doesn't support paging to disk and isn't managed by windows, but the 3Dlabs driver. Despite the limitations of the implementation, the solution is elegant, necessary, and extraordinarily useful to those who need massive amounts of RAM available to their visualization system.
On the display side, the Wildcat Realizm 200 is designed to push the limits of 9MP panels, video walls, and multi-system displays. With dual 10-bit 400MHz RAMDACs, two dual-link DVI-I connections, and support for an optional Multiview kit with genlock and framelock capabilities, the Wildcat Realizm is built to drive vast numbers of pixels. The scope of this article is limited to single display 3D applications, but if there is demand, we may explore the capabilities of professional cards to drive extremely high resolutions and 2 or more monitors.
Even though it can be tough to sort through at times, this low level description of hardware is nicer than what we get from ATI and NVIDIA in some ways because we get a chance to see what the hardware is actually doing. The block diagram high level look that others provide us can be very useful in understanding what a pipeline does, but it obfuscates the differences in respective implementations. We would love to have a combination of the low level physical description of hardware that 3Dlabs has given us and high level descriptions that we get from ATI and NVIDIA. Of course, then we could go build our own GPUs and skip the middle man.








25 Comments
View All Comments
Jeanlou - Thursday, December 1, 2005 - link
Hello,I just bumped into AnandTech Video Card Tests, and I'm really impressed !
As a Belgian Vision Systems Integration Consultant (since 1979), I'm very interrested about the ability to compare these 3 cards (Realizm 200 vs FireGL X3 256 vs NVIDIA Quatro FX 4000).
I just had a bad experience with the Realizm 200 (!)
On a ASUS NCCH-DL motherboard, Dual Xeon 2.8GHz, 2GB DDR 400, Seagate SCSI Ultra 320 HDD, 2 EIZO monitors (Monitor N°1= L985EX at 1600x1200 px), (Monitopr N°2= L565 at 1280x1024 px), Windows XP Pro SP2 x32bit partition C:\ 16GB, Windows XP Pro x64bit edition partition D:\ 16GB, plus Extended partions (2 logical E:\ and F:\). All NTFS.
Using the main monitor for images analyses (quality control) and the slave monitor for tools, I was unable to have a stable image at 1600 by 1200 pixels. While the Wildcat4 - 7110, or even the VP990 Pro have a very stable screen at maximum resolution. But the 7110 and the VP990 Pro don't have drivers for Window XP x64bit.
Tried everything, latest BIOS, latest drive for ChipSet...
Even 3Dlabs was unable to give me the necessary support and do not answer anymore !
As soon I reduced the resolution from the main monitor to 1280 by 1024, was everything stable, but that's not what I want, I need the maximum resolution on the main monitor.
The specs from 3Dlabs resolution table is giving 3840 by 2400 pixels maximum!
I send it back, and I'm looking for an other card.
I wonder if the FireGL X3 256 will do the job ?
We also use an other monitor from EIZO (S2410W) with 1920 by 1200 pixels !
What are exactly the several resolutions possible with the FireGL X3 256 using 2 monitors ? I cannot find it on the specs.
Any comment will be appreciated,
Best regards,
Jean
kaissa - Sunday, February 20, 2005 - link
Excellent article. I hope that you make workstation graphic card comparision a regular article. How about an article on workstation notebooks? Thanks a lot.laverdir - Thursday, December 30, 2004 - link
dear derek wilson,could you tell us how much is the performance
difference between numa and uma in general
on this tests..
and it would be great if you could post maya
related results for guadro 4k with numa enabled..
seasonal greetings
RedNight - Tuesday, December 28, 2004 - link
This is the best workstation graphics card review I have read in ages. Not only does it present the positive and negatives of each the principal cards in question, it presents them in relationship to high end mainsteam cards and thereby helps many, including myself, understand the real differences in performance. Also, by inovatingly including AutoCAD and Gaming Tests one gets a clear indication of when the workstation cards are necessary and when they would be a waste of money. ThanksDerekWilson - Monday, December 27, 2004 - link
Dubb,Thanks for letting us know about that one :-) We'll have to have a nice long talk with NV's workstation team about what exactly is going on there. They very strongly gave us the idea that the featureset wasn't present on geforce cards.
#19, NUMA was disabled because most people running a workstation with 4 or fewer GB of RAM on a 32 machine will not be running with the pae kernel installed. We wanted to test with a setup most people would be running under the circumstances. We will test NUMA capabilities in the future.
#20,
When we test workstation CPU performance or system performance, POVRay will be a possible inclusion. Thanks for the suggestion.
Derek Wilson
mbhame - Sunday, December 26, 2004 - link
Please include POVRay benchies in Workstation tests.Myrandex - Saturday, December 25, 2004 - link
I wonder why NUMA was fully supported but yet disabled. Maybe instabilities or something.Dubb - Friday, December 24, 2004 - link
http://newbietech.net/eng/qtoq/index.phphttp://forums.guru3d.com/showthread.php?s=2347485b...
Dubb - Friday, December 24, 2004 - link
uhhh.. my softquadro'd 5900 ultra begs to differ. as would all the 6800 > qfx4000 mods being done by people on guru3d's rivatuner forum.I thought you guys knew that just because nvida says something doesn't mean it's true?
they must consider "physically different sillicon" to be "we moved a resistor or two"...
DerekWilson - Friday, December 24, 2004 - link
By high end features, I wasn't talking about texturing or prgrammatic vertex or fragment shading (which is highend in the consumer space).I was rather talking about hardware support for: AA lines and points, overlay plane support, two-sided lighting (fixed function path), logic operations, fast pixel read-back speeds, and dual 10-bit 400MHz RAMDACs and 2 dual-link DVI-I connectors supporting 3840x2400 on a single display (the IBM T221 comes to mind).
There are other features, but these are key. In products like Maya and 3D Studio, not having overlay plane support creates an absolutely noticable performance hit. It really does depend on how you push the cards. We do prefer the in application benchmarks to SPECveiwperf. Even the SPECapc tests can give a better feel for where things will fall -- because the entire system is a factor rather than just the gfx card and CPU.
#14, Dubb -- I hate to be the one to tell you this -- GeForce and Quadro are physically different silicon now (NV40 and NV40GL). AFAIK, ever since GF4/Quadro4, it has been impossible to softquadro an nvidia card. The Quadro team uses the GeForce as it's base core, but then adds on workstation class features.