Workstation Graphics: AGP Cross Section 2004
by Derek Wilson on December 23, 2004 4:14 PM EST- Posted in
- GPUs
NVIDIA Quadro FX 4000 Technology
As with the ATI FireGL X3-256, NVIDIA's workstation core is based around its most recent consumer GPU. Unlike the top end offering from ATI, NVIDIA's highest end AGP workstation part is based on their highest end consumer level SKU. Thus, the Quadro FX 4000 has pixel processing advantage over the offerings from ATI and 3Dlabs in its 16 pipeline design. This will give it a shading advantage, but in the high end workstation space, geometry throughput is still most important. Fragment and pixel level impact has less effect in the workstation market than the consumer market, which is precisely the reason that last year's Quadro FX preformed much better than its consumer level partner. As with the ATI FireGL X3-256, since we're testing the consumer level part as well, we'll take a look at the common architecture and then hit on the additional features that make the NV40GL true workstation silicon.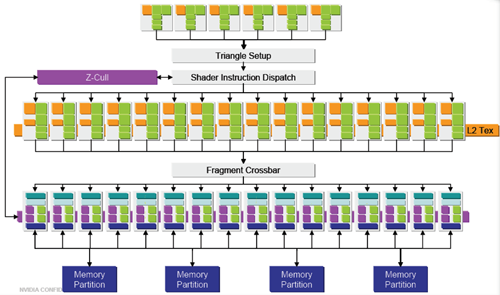
As we see the familiar pipeline laid out once again, we'll take a look at how NVIDIA defines each of these blocks, starting with the vertex pipeline and moving down. The VS 3.0 capable vertex pipelines are made up of MIMD (multiple input multiple data) processing blocks. Up to two instructions can be issued per clock per unit, and NVIDIA claims that it is able to hide completely the latency of vertex texture fetches in the pipeline.
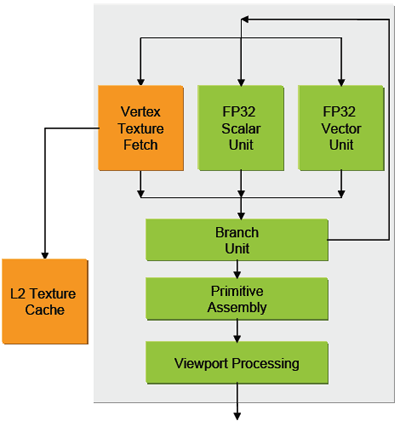
The side by side scalar and vector unit allow multiple instructions to be performed on different parts of the vertex at a time, if necessary (this is called co-issue in DX9 terminology). The 6 vertex units of the NV40 gives it more potential geometry power at a lower precision than the 3Dlabs part (on a component level, we're looking at a possible 24 32-bit components per clock). This does depend on the layout of 3Dlabs SIMD arrays and their driver's ability to schedule code for them. There is no hardware imposed limit on instructions that the vertex engine can handle, though currently software limits shader length to 65k instructions.
Visibility is computed in much the same way at the previous descriptions. The early/hierarchical z process eliminates blocks of pixels that are completely occluded and eliminates them from going through the pixel pipeline. For pixels that aren't clearly occluded, groups travel in quads four (a block of four pixels in a square pattern on a surface) through pixel pipelines. Each quad shares an L1 cache (which makes sense as each quad should have a strong locality of reference). Each of the 16 pixel pipelines looks like this on the inside:
![]()
The two shader units inside each pixel pipeline are 4 wide and can handle dual-issue and co-issue of instructions. The easy way to look at this is that each pipeline can optimally handle executing two instructions on two pixels at a time (meaning that it can perform up to 8 32-bit operations per clock cycle). This is only when not loading a texture, as texture loading will supercede the operation of one of the shader units. The pixel units are able to support shaders with lengths up to 65k instructions. Since we are not told the exact nature of the hardware, it seems very likely that NVIDIA would do some very complex resource management at the driver level and rotate texture loads and shader execution on a per quad basis. This would allow them to have less physical hardware than what software is able to "see" or make use of. To put it in perspective, if NVIDIA had all the physical processing units to brute force 8 32-bit floating operations in each of the 16 pipelines per clock cycle, that would mean needing the power of 128x 32 floating point units divided among some number of SIMD blocks. This would be approximately 2.7 times the fragment hardware packed in the Wildcat Realizm 200 GPU. In the end, we suspect that NVIDIA shares more resource than what we know about, but they just don't give us the detail to the metal that we have with the 3Dlabs part. At the same time, knowing how the 3Dlabs driver manages some of its resources in more detail would help us understand its performance characteristics better as well.
Moving on to the ROP pipelines, NVIDIA handles FSAA and z/stencil/color compression and rasterization here. During z only operations (such as in some shadowing and other depth only algorithms), the color portion of the ROP can handle z functionality. This means that the NV40GL is capable of 32 z/stencil operations per clock during depth only passes. This might not be as useful in the workstation segment as it is on the consumer side in games such as Doom 3.
The NVIDIA part also has the ability to support a 16-bit floating point framebuffer as the Wildcat Realizm GPU. This gives it the same functionality in display capabilities. The Quadro FX 4000 supports two dual-link DVI-I connectors, though the board is not upgradeable to genlock and framelock support. There is a separate (more expensive) product called the Quadro FX 4000 SDI, which has one dual-link DVI-I connector and two SDI connectors for broadcast video that supports genlock. If there is demand, we may compare this product to the 3Dlabs solution (and other broadcast or large scale visualization solutions).
It's unclear whether or not this part has the video processor (recently dubbed PureVideo) of NV40 built into it as well. It's possible that this feature was left out to make room for some of the workstation specific elements of the NV40GL. What, exactly, are the enhancements that were added to NV40 that make the Quadro FX 4000 a better workstation part? Let's take a look.
Hardware antialiased lines and points is the first and oldest component supported by the Quadro line that hasn't been enabled in the GeForce series. The feature just isn't necessary for gamers or consumer land applications, as it is used specifically to smooth the drawing of lines and points in wireframe modes. Antialiasing individual primitives is much more accurate and cleaner than FSAA algorithms, and is very desireable in applications where wireframe mode is used the majority of the time (which includes most of the CAD/CAM/DCC world).
OpenGL logic operations are supported, which allows things like hardware XORs to combine elements in a scene. Logic operations are performed between the fragment shader and the framebuffer in the OpenGL pipeline and have programmatic control over how (and if) data makes it down the pipeline.
The NV40GL supports 8 clip regions while NV40 only supports 1 clip region. The importance of having multiple clip regions is in accelerating 3D when overlapped by other windows. When a 3D window is clipped, the buffer can't be treated as one block in the frame buffer, but must be set up as multiple clip regions. On GeForce cards, when a 3D window needs to be broken up into multiple regions, the 3D can no longer be hardware accelerated. Though the name is similar, this is different than the also-supported hardware accelerated clip planes. In a 3D scene, a near clip plane defines the position beyond which geometry will be visible. Some applications allow the user to move or create clip planes to cut away parts of drawings and "look inside".
Memory management on the Quadro line is geared towards professional applications rather than towards games, though we aren't given much indication as to the differences in the algorithms used. The NV40GL is able to support things like quad-buffered stereo, which the NV40 is not capable of.
Two-sided lighting is supported in the fixed function pipeline on the Quadro FX 4000. Even though the GeForce 6 Series supports two-sided lighting through SM 3.0, professional applications do not normally implement lighting via shader programs yet. It's much easier and more straight forward to use the fixed function path to create lights, and hardware accelerated two-sided lighting is a nice feature to have for these applications.
Overlay planes are supported in hardware as well. There are a couple different options on the type of overlay plane to allow, but the idea is to have a lower memory footprint (usually 8bit) transparent layer rendered above the 3D scene in order to support things like pop-up windows or selection effects without clipping or drawing into the actual scene itself. This can significantly improve performance for applications and hardware that support its use.
Driver optimizations are also geared specifically towards each professional application that the user may want to run with the Quadro. Different overlay modes or other settings may be optimal for a different application. In addition, OpenGL, stability, and image quality are the most important aspects of driver development on the Quadro side.








25 Comments
View All Comments
Jeanlou - Thursday, December 1, 2005 - link
Hello,I just bumped into AnandTech Video Card Tests, and I'm really impressed !
As a Belgian Vision Systems Integration Consultant (since 1979), I'm very interrested about the ability to compare these 3 cards (Realizm 200 vs FireGL X3 256 vs NVIDIA Quatro FX 4000).
I just had a bad experience with the Realizm 200 (!)
On a ASUS NCCH-DL motherboard, Dual Xeon 2.8GHz, 2GB DDR 400, Seagate SCSI Ultra 320 HDD, 2 EIZO monitors (Monitor N°1= L985EX at 1600x1200 px), (Monitopr N°2= L565 at 1280x1024 px), Windows XP Pro SP2 x32bit partition C:\ 16GB, Windows XP Pro x64bit edition partition D:\ 16GB, plus Extended partions (2 logical E:\ and F:\). All NTFS.
Using the main monitor for images analyses (quality control) and the slave monitor for tools, I was unable to have a stable image at 1600 by 1200 pixels. While the Wildcat4 - 7110, or even the VP990 Pro have a very stable screen at maximum resolution. But the 7110 and the VP990 Pro don't have drivers for Window XP x64bit.
Tried everything, latest BIOS, latest drive for ChipSet...
Even 3Dlabs was unable to give me the necessary support and do not answer anymore !
As soon I reduced the resolution from the main monitor to 1280 by 1024, was everything stable, but that's not what I want, I need the maximum resolution on the main monitor.
The specs from 3Dlabs resolution table is giving 3840 by 2400 pixels maximum!
I send it back, and I'm looking for an other card.
I wonder if the FireGL X3 256 will do the job ?
We also use an other monitor from EIZO (S2410W) with 1920 by 1200 pixels !
What are exactly the several resolutions possible with the FireGL X3 256 using 2 monitors ? I cannot find it on the specs.
Any comment will be appreciated,
Best regards,
Jean
kaissa - Sunday, February 20, 2005 - link
Excellent article. I hope that you make workstation graphic card comparision a regular article. How about an article on workstation notebooks? Thanks a lot.laverdir - Thursday, December 30, 2004 - link
dear derek wilson,could you tell us how much is the performance
difference between numa and uma in general
on this tests..
and it would be great if you could post maya
related results for guadro 4k with numa enabled..
seasonal greetings
RedNight - Tuesday, December 28, 2004 - link
This is the best workstation graphics card review I have read in ages. Not only does it present the positive and negatives of each the principal cards in question, it presents them in relationship to high end mainsteam cards and thereby helps many, including myself, understand the real differences in performance. Also, by inovatingly including AutoCAD and Gaming Tests one gets a clear indication of when the workstation cards are necessary and when they would be a waste of money. ThanksDerekWilson - Monday, December 27, 2004 - link
Dubb,Thanks for letting us know about that one :-) We'll have to have a nice long talk with NV's workstation team about what exactly is going on there. They very strongly gave us the idea that the featureset wasn't present on geforce cards.
#19, NUMA was disabled because most people running a workstation with 4 or fewer GB of RAM on a 32 machine will not be running with the pae kernel installed. We wanted to test with a setup most people would be running under the circumstances. We will test NUMA capabilities in the future.
#20,
When we test workstation CPU performance or system performance, POVRay will be a possible inclusion. Thanks for the suggestion.
Derek Wilson
mbhame - Sunday, December 26, 2004 - link
Please include POVRay benchies in Workstation tests.Myrandex - Saturday, December 25, 2004 - link
I wonder why NUMA was fully supported but yet disabled. Maybe instabilities or something.Dubb - Friday, December 24, 2004 - link
http://newbietech.net/eng/qtoq/index.phphttp://forums.guru3d.com/showthread.php?s=2347485b...
Dubb - Friday, December 24, 2004 - link
uhhh.. my softquadro'd 5900 ultra begs to differ. as would all the 6800 > qfx4000 mods being done by people on guru3d's rivatuner forum.I thought you guys knew that just because nvida says something doesn't mean it's true?
they must consider "physically different sillicon" to be "we moved a resistor or two"...
DerekWilson - Friday, December 24, 2004 - link
By high end features, I wasn't talking about texturing or prgrammatic vertex or fragment shading (which is highend in the consumer space).I was rather talking about hardware support for: AA lines and points, overlay plane support, two-sided lighting (fixed function path), logic operations, fast pixel read-back speeds, and dual 10-bit 400MHz RAMDACs and 2 dual-link DVI-I connectors supporting 3840x2400 on a single display (the IBM T221 comes to mind).
There are other features, but these are key. In products like Maya and 3D Studio, not having overlay plane support creates an absolutely noticable performance hit. It really does depend on how you push the cards. We do prefer the in application benchmarks to SPECveiwperf. Even the SPECapc tests can give a better feel for where things will fall -- because the entire system is a factor rather than just the gfx card and CPU.
#14, Dubb -- I hate to be the one to tell you this -- GeForce and Quadro are physically different silicon now (NV40 and NV40GL). AFAIK, ever since GF4/Quadro4, it has been impossible to softquadro an nvidia card. The Quadro team uses the GeForce as it's base core, but then adds on workstation class features.