GeForce GTX 970: Correcting The Specs & Exploring Memory Allocation
by Ryan Smith on January 26, 2015 1:00 PM ESTSegmented Memory Allocation in Software
So far we’ve talked about the hardware, and having finally explained the hardware basis of segmented memory we can begin to understand the role software plays, and how software allocates memory among the two segments.
From a low-level perspective, video memory management under Windows is the domain of the combination of the operating system and the video drivers. Strictly speaking Windows controls video memory management – this being one of the big changes of Windows Vista and the Windows Display Driver Model – while the video drivers get a significant amount of input in hinting at how things should be laid out.
Meanwhile from an application’s perspective all video memory and its address space is virtual. This means that applications are writing to their own private space, blissfully unaware of what else is in video memory and where it may be, or for that matter where in memory (or even which memory) they are writing. As a result of this memory virtualization it falls to the OS and video drivers to decide where in physical VRAM to allocate memory requests, and for the GTX 970 in particular, whether to put a request in the 3.5GB segment, the 512MB segment, or in the worst case scenario system memory over PCIe.
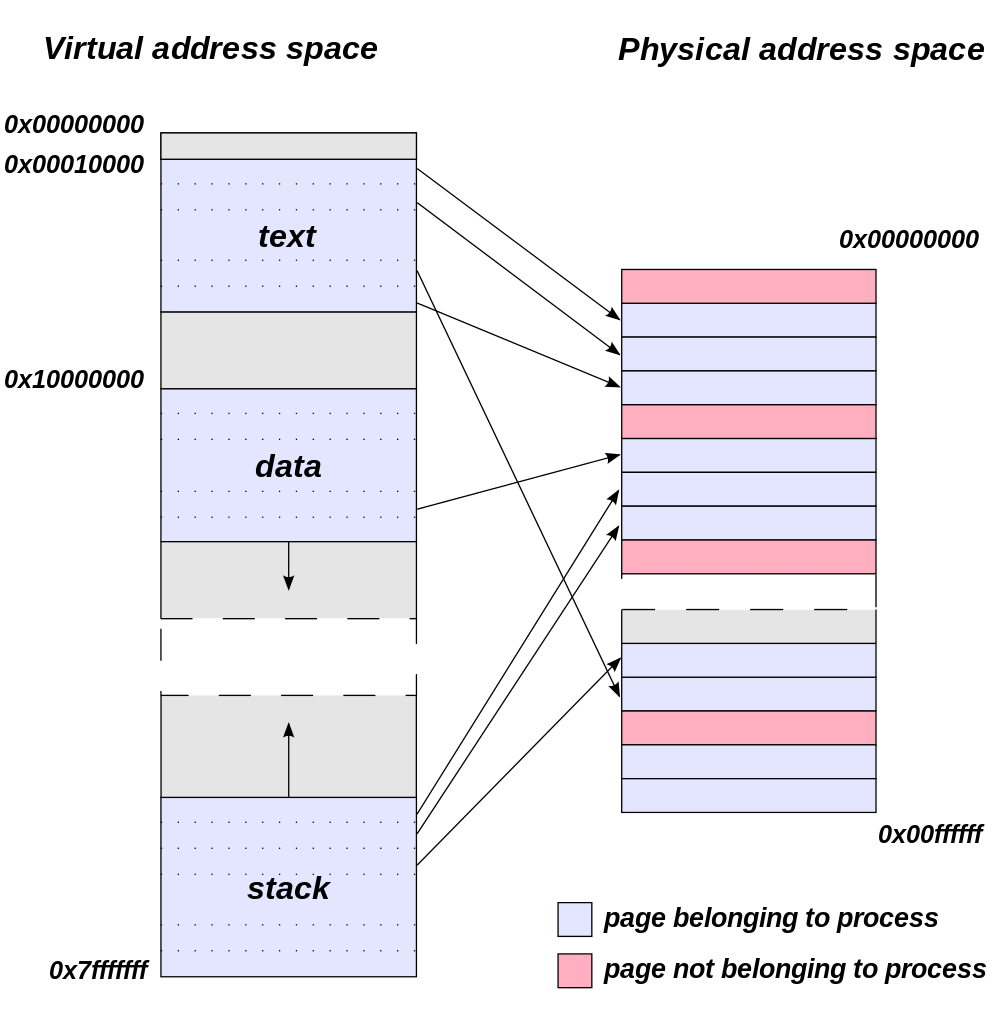
Virtual Address Space (Image Courtesy Dysprosia)
Without going quite so far to rehash the entire theory of memory management and caching, the goal of memory management in the case of the GTX 970 is to allocate resources over the entire 4GB of VRAM such that high-priority items end up in the fast segment and low-priority items end up in the slow segment. To do this NVIDIA focuses up to the first 3.5GB of memory allocations on the faster 3.5GB segment, and then finally for memory allocations beyond 3.5GB they turn to the 512MB segment, as there’s no benefit to using the slower segment so long as there’s available space in the faster segment.
The complex part of this process occurs once both memory segments are in use, at which point NVIDIA’s heuristics come into play to try to best determine which resources to allocate to which segments. How NVIDIA does this is very much a “secret sauce” scenario for the company, but from a high level identifying the type of resource and when it was last used are good ways to figure out where to send a resource. Frame buffers, render targets, UAVs, and other intermediate buffers for example are the last thing you want to send to the slow segment; meanwhile textures, resources not in active use (e.g. cached), and resources belonging to inactive applications would be great candidates to send off to the slower segment. The way NVIDIA describes the process we suspect there are even per-application optimizations in use, though NVIDIA can clearly handle generic cases as well.
From an API perspective this is applicable towards both graphics and compute, though it’s a safe bet that graphics is the more easily and accurately handled of the two thanks to the rigid nature of graphics rendering. Direct3D, OpenGL, CUDA, and OpenCL all see and have access to the full 4GB of memory available on the GTX 970, and from the perspective of the applications using these APIs the 4GB of memory is identical, the segments being abstracted. This is also why applications attempting to benchmark the memory in a piecemeal fashion will not find slow memory areas until the end of their run, as their earlier allocations will be in the fast segment and only finally spill over to the slow segment once the fast segment is full.
| GeForce GTX 970 Addressable VRAM | |||
| API | Memory | ||
| Direct3D | 4GB | ||
| OpenGL | 4GB | ||
| CUDA | 4GB | ||
| OpenCL | 4GB | ||
The one remaining unknown element here (and something NVIDIA is still investigating) is why some users have been seeing total VRAM allocation top out at 3.5GB on a GTX 970, but go to 4GB on a GTX 980. Again from a high-level perspective all of this segmentation is abstracted, so games should not be aware of what’s going on under the hood.
Overall then the role of software in memory allocation is relatively straightforward since it’s layered on top of the segments. Applications have access to the full 4GB, and due to the fact that application memory space is virtualized the existence and usage of the memory segments is abstracted from the application, with the physical memory allocation handled by the OS and driver. Only after 3.5GB is requested – enough to fill the entire 3.5GB segment – does the 512MB segment get used, at which point NVIDIA attempts to place the least sensitive/important data in the slower segment.








{kind=link}
398 Comments
View All Comments
yannigr2 - Tuesday, January 27, 2015 - link
They live deep in a hole and Nvidia forbids them to have any contact with the outside world. No internet, no telephone, no TV, no sunlight. That way they secure that their intellectual property will not leak to the reds.dragonsqrrl - Monday, January 26, 2015 - link
I thought last week Ryan was bought out by AMD?alacard - Monday, January 26, 2015 - link
This isn't a coverup, this is journalism acting as the public relations arm of a company they work closely with. Think of it sort of like regulatory capture but instead of a public-private relationship you have a private-private one.With regard to your puerile Nvidia vs AMD remark, you might want to elevate yourself above those pathetic, tribalisic, and base arguments and join adulthood where we don't give a shit who is doing lying, only that they get called out and criticized for it in an effort to curtail similar behavior in the future.
dragonsqrrl - Tuesday, January 27, 2015 - link
... you responded to the wrong comment. Can't really blame you though, at a certain point this layout makes it impossible to tell who's responding to who."you might want to elevate yourself above those pathetic, tribalisic, and base arguments and join adulthood"
You don't do much self reflection do you? This sort of critique only helps your credibility if you bring it up while you're not flaming at other people.
D. Lister - Tuesday, January 27, 2015 - link
"you might want to elevate yourself above those pathetic, tribalisic, and base arguments and join adulthood"http://www.anandtech.com/comments/8935/geforce-gtx...
"Is that PT Barnum's johnson i see swinging from your asshole?"
http://www.anandtech.com/comments/8935/geforce-gtx...
"Guys, when your master's knock some shit off their table for you to eat,..."
If irony were a dollar a pound, you could be sitting on a gold mine right there.
maximumGPU - Tuesday, January 27, 2015 - link
Priceless!alacard - Tuesday, January 27, 2015 - link
Eh, just having some fun with that colorful language. Dragonsqrrl, like you said, i thought you were responding to me and one thing i cannot stand is every discussion devolving into two cheer-leading squads fighting over their favorite corporate logo. Corporations who would gladly hire those same cheerleaders for 18 hour shifts at slave wages so their executives and board members can buy another yacht.tspacie - Monday, January 26, 2015 - link
Sure. It's fun to see what reviewers think of a product after you've made it. That said it would have been easy to miss the recent 3.5GB controversy unless you were looking for it.limitedaccess - Monday, January 26, 2015 - link
What about other Maxwell GPUs? GTX 980m, GTX 970m, GTX 965m, and GTX 750. Are they all correctly listed and therefore do not exhibit this issue?In particular a comparison between the GTX 980m and GTX 970 would be interesting.
Also how about Kepler as well?
bwat47 - Monday, January 26, 2015 - link
Its impossible for kepler to have this issue because only maxwell can partially disable a ROP/memory controller