The Radeon HD 4850 & 4870: AMD Wins at $199 and $299
by Anand Lal Shimpi & Derek Wilson on June 25, 2008 12:00 AM EST- Posted in
- GPUs
Wrapping Up the Architecture and Efficiency Discussion
Engineering is all about tradeoffs and balance. The choice to increase capability in one area may decrease capability in another. The addition of a feature may not be worth the cost of including it. In the worst case, as Intel found with NetBurst, an architecture may inherently flawed and a starting over down an entirely different path might be the best solution.
We are at a point where there are quite a number of similarities between NVIDIA and AMD hardware. They both require maintaining a huge number of threads in flight to hide memory and instruction latency. They both manage threads in large blocks of threads that share context. Caching, coalescing memory reads and writes, and handling resource allocation need to be carefully managed in order to keep the execution units fed. Both GT200 and RV770 execute branches via dynamic predication of direction a thread does not branch (meaning if a thread in a warp or wavefront branches differently from others, all threads in that group must execute both code paths). Both share instruction and constant caches across hardware that is SIMD in nature servicing multiple threads in one context in order to effect hardware that fits the SPMD (single program multiple data) programming model.
But the hearts of GT200 and RV770, the SPA (Steaming Processor Array) and the DPP (Data Parallel Processing) Array, respectively, are quite different. The explicitly scalar one operation per thread at a time approach that NVIDIA has taken is quite different from the 5 wide VLIW approach AMD has packed into their architecture. Both of them are SIMD in nature, but NVIDIA is more like S(operation)MD and AMD is S(VLIW)MD.
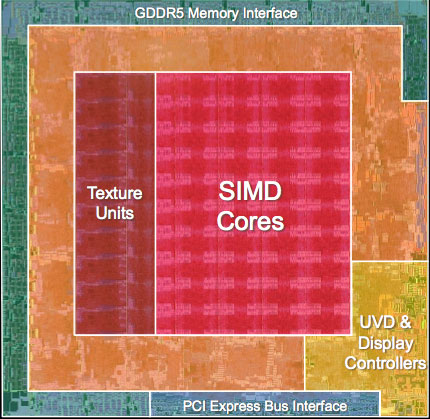
AMD's RV770, all built up and pretty
Filling the execution units of each to capacity is a challenge but looks to be more consistent on NVIDIA hardware, while in the cases where AMD hardware is used effectively (like Bioshock) we see that RV770 surpasses GTX 280 in not only performance but power efficiency as well. Area efficiency is completely owned by AMD, which means that their cost for performance delivered is lower than NVIDIA's (in terms of manufacturing -- R&D is a whole other story) since smaller ICs mean cheaper to produce parts.
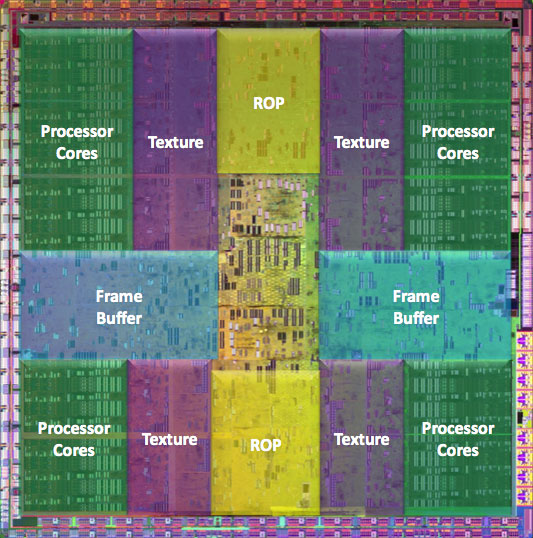
NVIDIA's GT200, in all its daunting glory
While shader/kernel length isn't as important on GT200 (except that the ratio of FP and especially multiply-add operations to other code needs to be high to extract high levels of performance), longer programs are easier for AMD's compiler to extract ILP from. Both RV770 and GT200 must balance thread issue with resource usage, but RV770 can leverage higher performance in situations where ILP can be extracted from shader/kernel code which could also help in situations where the GT200 would not be able to hide latency well.
We believe based on information found on the CUDA forums and from some of our readers that G80's SPs have about a 22 stage pipeline and that GT200 is also likely deeply piped, and while AMD has told us that their pipeline is significantly shorter than this they wouldn't tell us how long it actually is. Regardless, a shorter pipeline and the ability to execute one wavefront over multiple scheduling cycles means massive amounts of TLP isn't needed just to cover instruction latency. Yes massive amounts of TLP are needed to cover memory latency, but shader programs with lots of internal compute can also help to do this on RV770.
All of this adds up to the fact that, despite the advent of DX10 and the fact that both of these architectures are very good at executing large numbers of independent threads very quickly, getting the most out of GT200 and RV770 requires vastly different approaches in some cases. Long shaders can benefit RV770 due to increased ILP that can be extracted, while the increased resource use of long shaders may mean less threads can be issued on GT200 causing lowered performance. Of course going the other direction would have the opposite effect. Caches and resource availability/management are different, meaning that tradeoffs and choices must be made in when and how data is fetched and used. Fixed function resources are different and optimization of the usage of things like texture filters and the impact of the different setup engines can have a large (and differing with architecture) impact on performance.
We still haven't gotten to the point where we can write simple shader code that just does what we want it to do and expect it to perform perfectly everywhere. Right now it seems like typical usage models favor GT200, while relative performance can vary wildly on RV770 depending on how well the code fits the hardware. G80 (and thus NVIDIA's architecture) did have a lead in the industry for months before R600 hit the scene, and it wasn't until RV670 that AMD had a real competitor in the market place. This could be part of the reason we are seeing fewer titles benefiting from the massive amount of compute available on AMD hardware. But with this launch, AMD has solidified their place in the market (as we will see the 4800 series offers a lot of value), and it will be very interesting to see what happens going forward.








215 Comments
View All Comments
araczynski - Wednesday, June 25, 2008 - link
...as more and more people are hooking up their graphics cards to big HDTVs instead of wasting time with little monitors, i keep hoping to find out whether the 9800gx2/4800 lines have proper 1080p scaling/synching with the tvs? for example the 8800 line from nvidia seems to butcher 1080p with tv's.anyone care to speak from experience?
DerekWilson - Wednesday, June 25, 2008 - link
i havent had any problem with any modern graphics card (dvi or hdmi) and digital hdtvsi haven't really played with analog for a long time and i'm not sure how either amd or nvidia handle analog issues like overscan and timing.
araczynski - Wednesday, June 25, 2008 - link
interesting, what cards have you worked with? i have the 8800gts512 right now and have the same problem as with the 7900gtx previously. when i select 1080p for the resolution (which the drivers recognize the tv being capable of as it lists it as the native resolution) i get a washed out messy result where the contrast/brightness is completely maxed (sliders do little to help) as well as the whole overscan thing that forces me to shrink the displayed image down to fit the actual tv (with the nvidia driver utility). 1600x900 can usually be tolerable in XP (not in vista for some reason) and 1080p is just downright painful.i suppose it could by my dvi to hdmi cable? its a short run, but who knows... i just remember reading a bit on the nvidia forums that this is a known issue with the 8800 line, so was curious as to how the 9800 line or even the 4800 line handle it.
but as the previous guy mentioned, ATI does tend to do the TV stuff much better than nvidia ever did... maybe 4850 crossfire will be in my rig soon... unless i hear more about the 4870x2 soon...
ChronoReverse - Wednesday, June 25, 2008 - link
ATI cards tend to do the TV stuff properlyFXi - Wednesday, June 25, 2008 - link
If Nvidia doesn't release SLI to Intel chipsets (and on a $/perf ratio it might not even help if it does), the 4870 in CF is going to stop sales of the 260's into the ground.Releasing SLI on Intel and easing the price might help ease that problem, but of course they won't do it. Looks like ATI hasn't just come back, they've got a very, very good chip on their hands.
Powervano - Wednesday, June 25, 2008 - link
Anand and DerekWhat about temperatures of HD4870 under IDLE and LOAD? page 21 only shows power comsumption.
iwodo - Wednesday, June 25, 2008 - link
Given how ATI architecture greatly rely on maximizing its Shader use, wouldn't driver optimization be much more important then Nvidia in this regard?And is ATI going about Nvidia CUDA? Given CUDA now have a much bigger exposure then how ever ATI is offering.. CAL or CTM.. i dont even know now.
DerekWilson - Wednesday, June 25, 2008 - link
getting exposure for AMD's own GPGPU solutions and tools is going to be though, especially in light of Tesla and the momentum NVIDIA is building in the higher performance areas.they've just got to keep at it.
but i think their best hope is in Apple right now with OpenCL (as has been mentioned above) ...
certainly AMD need to keep pushing their GPU compute solutions, and trying to get people to build real apps that they can point to (like folding) and say "hey look we do this well too" ...
but in the long term i think NVIDIA's got the better marketing there (both to consumers and developers) and it's not likely going to be until a single compute language emerges as the dominant one that we see level competition.
Amiga500 - Wednesday, June 25, 2008 - link
AMD are going to continue to use the open source alternative - Open CL.In a relatively fledgling program environment, it makes all the sense in the world for developers to use the open source option, as compatibility and interoperability can be assured, unlike older environments like graphics APIs.
OSX v10.6 (snow lepoard) will use Open CL.
DerekWilson - Wednesday, June 25, 2008 - link
OpenCL isn't "open source" ...Apple is trying to create an industry standard heterogeneous compute language.
What we need is a compute language that isn't "owned" by a specific hardware maker. The problem is that NVIDIA has the power to redefine the CUDA language as it moves forward to better fit their architecture. Whether they would do this or not is irrelevant in light of the fact that it makes no sense for a competitor to adopt the solution if the possibility exists.
If NVIDIA wants to advance the industry, eventually they'll try and get CUDA ANSI / ISO certified or try to form an industry working group to refine and standardize it. While they have the exposure and power in CUDA and Tesla they won't really be interested in doing this (at least that's our prediction).
Apple is starting from a standards centric view and I hope they will help build a heterogeneous computing language that combines the high points of all the different solutions out there now into something that's easy to develop or and that can generate code to run well on all architectures.
but we'll have to wait and see.