The Radeon HD 4850 & 4870: AMD Wins at $199 and $299
by Anand Lal Shimpi & Derek Wilson on June 25, 2008 12:00 AM EST- Posted in
- GPUs
Wrapping Up the Architecture and Efficiency Discussion
Engineering is all about tradeoffs and balance. The choice to increase capability in one area may decrease capability in another. The addition of a feature may not be worth the cost of including it. In the worst case, as Intel found with NetBurst, an architecture may inherently flawed and a starting over down an entirely different path might be the best solution.
We are at a point where there are quite a number of similarities between NVIDIA and AMD hardware. They both require maintaining a huge number of threads in flight to hide memory and instruction latency. They both manage threads in large blocks of threads that share context. Caching, coalescing memory reads and writes, and handling resource allocation need to be carefully managed in order to keep the execution units fed. Both GT200 and RV770 execute branches via dynamic predication of direction a thread does not branch (meaning if a thread in a warp or wavefront branches differently from others, all threads in that group must execute both code paths). Both share instruction and constant caches across hardware that is SIMD in nature servicing multiple threads in one context in order to effect hardware that fits the SPMD (single program multiple data) programming model.
But the hearts of GT200 and RV770, the SPA (Steaming Processor Array) and the DPP (Data Parallel Processing) Array, respectively, are quite different. The explicitly scalar one operation per thread at a time approach that NVIDIA has taken is quite different from the 5 wide VLIW approach AMD has packed into their architecture. Both of them are SIMD in nature, but NVIDIA is more like S(operation)MD and AMD is S(VLIW)MD.
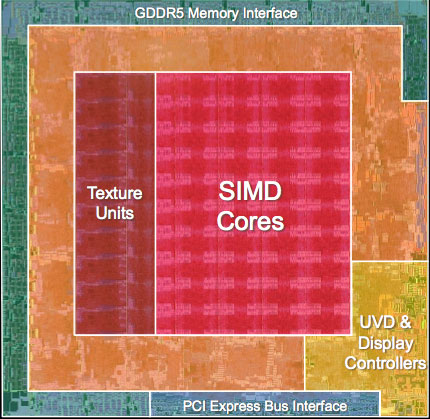
AMD's RV770, all built up and pretty
Filling the execution units of each to capacity is a challenge but looks to be more consistent on NVIDIA hardware, while in the cases where AMD hardware is used effectively (like Bioshock) we see that RV770 surpasses GTX 280 in not only performance but power efficiency as well. Area efficiency is completely owned by AMD, which means that their cost for performance delivered is lower than NVIDIA's (in terms of manufacturing -- R&D is a whole other story) since smaller ICs mean cheaper to produce parts.
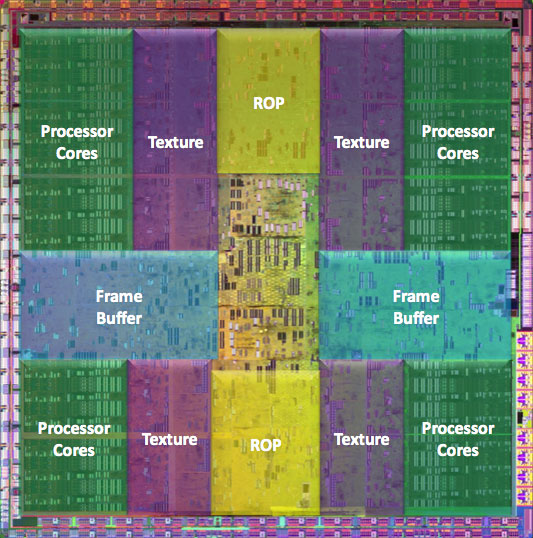
NVIDIA's GT200, in all its daunting glory
While shader/kernel length isn't as important on GT200 (except that the ratio of FP and especially multiply-add operations to other code needs to be high to extract high levels of performance), longer programs are easier for AMD's compiler to extract ILP from. Both RV770 and GT200 must balance thread issue with resource usage, but RV770 can leverage higher performance in situations where ILP can be extracted from shader/kernel code which could also help in situations where the GT200 would not be able to hide latency well.
We believe based on information found on the CUDA forums and from some of our readers that G80's SPs have about a 22 stage pipeline and that GT200 is also likely deeply piped, and while AMD has told us that their pipeline is significantly shorter than this they wouldn't tell us how long it actually is. Regardless, a shorter pipeline and the ability to execute one wavefront over multiple scheduling cycles means massive amounts of TLP isn't needed just to cover instruction latency. Yes massive amounts of TLP are needed to cover memory latency, but shader programs with lots of internal compute can also help to do this on RV770.
All of this adds up to the fact that, despite the advent of DX10 and the fact that both of these architectures are very good at executing large numbers of independent threads very quickly, getting the most out of GT200 and RV770 requires vastly different approaches in some cases. Long shaders can benefit RV770 due to increased ILP that can be extracted, while the increased resource use of long shaders may mean less threads can be issued on GT200 causing lowered performance. Of course going the other direction would have the opposite effect. Caches and resource availability/management are different, meaning that tradeoffs and choices must be made in when and how data is fetched and used. Fixed function resources are different and optimization of the usage of things like texture filters and the impact of the different setup engines can have a large (and differing with architecture) impact on performance.
We still haven't gotten to the point where we can write simple shader code that just does what we want it to do and expect it to perform perfectly everywhere. Right now it seems like typical usage models favor GT200, while relative performance can vary wildly on RV770 depending on how well the code fits the hardware. G80 (and thus NVIDIA's architecture) did have a lead in the industry for months before R600 hit the scene, and it wasn't until RV670 that AMD had a real competitor in the market place. This could be part of the reason we are seeing fewer titles benefiting from the massive amount of compute available on AMD hardware. But with this launch, AMD has solidified their place in the market (as we will see the 4800 series offers a lot of value), and it will be very interesting to see what happens going forward.








215 Comments
View All Comments
DevinCerly - Thursday, September 17, 2020 - link
https://mediahubofficialchannel.kofilms.info/ati-b...">[img]https://i.ytimg.com/vi/fqjU_OCZ4j4/hqdefault.jpg[/img]Ati BhoEpisode 0307-March-2020New Comedy https://mediahubofficialchannel.kofilms.info/ati-b...">SerialBy Media Hub Official Channel
GertieHuh - Friday, September 18, 2020 - link
https://teammojang.bgworld.info/ask-mojang/mbzCqMu...">[img]https://i.ytimg.com/vi/6XaGgppwjZM/hqdefault.jpg[/img]Ask https://teammojang.bgworld.info/ask-mojang/mbzCqMu...">Mojang #10: Electricity or Magic?
JuanitaBed - Saturday, September 19, 2020 - link
https://realpharmnutrition.plthrow.info/eng-sub/sp...">[img]https://i.ytimg.com/vi/M_m2tVwr7_o/hqdefault.jpg[/img]ENG SUB Mateusz Kieliszkowski x Konrad Karwat https://realpharmnutrition.plthrow.info/eng-sub/sp...">- trening hantla
Bettyabaws - Sunday, September 20, 2020 - link
https://joanaceddia.csgoal.info/lYBys6h-a2DdipU/pl...">[img]https://i.ytimg.com/vi/bJBNrF90yXc/hqdefault.jpg[/img]https://joanaceddia.csgoal.info/lYBys6h-a2DdipU/pl...">Playing A Horror Game
Holliebrill - Tuesday, September 22, 2020 - link
https://chelseatv.ilhistory.info/iIt8rbaeh9PI0rA/o...">[img]https://i.ytimg.com/vi/UZHHPlQpcqM/hqdefault.jpg[/img]Olivier https://chelseatv.ilhistory.info/iIt8rbaeh9PI0rA/o...">Giroud Winner Stuns VillaAston Villa 1-2 ChelseaUnseen Extra
Rosalynexete - Tuesday, September 22, 2020 - link
https://stay12.cscrone.info/iGWumpbSgXqoZWw/moje-s...">[img]https://i.ytimg.com/vi/V2u52oIFx58/hqdefault.jpg[/img]https://stay12.cscrone.info/iGWumpbSgXqoZWw/moje-s...">MOJE SETUP TOUR 2019
YolandaBob - Thursday, September 24, 2020 - link
https://tensai2407.trworld.info/aZ6Yg6HSp2dpw5Y/ms...">[img]https://i.ytimg.com/vi/3ehJilF65a4/hqdefault.jpg[/img]🥠مشكلتي Щ…Ш№ https://tensai2407.trworld.info/aZ6Yg6HSp2dpw5Y/ms...">Ш§Щ„ЩЉЩ€ШЄЩЉЩ€ШЁ Щ€ ЩЃЩЉЩЃШ§ Щ€ Ш§Щ„ШЩЉШ§Ш© Щ€ЩѓЩ„ ШґЩЉ
CelesteCen - Sunday, September 27, 2020 - link
https://onetwoonetwors.azfun.info/kXiV2b2zkc3NsL4/...">[img]https://i.ytimg.com/vi/-E4wXzZkhzY/hqdefault.jpg[/img]КОРОЧЕ ГОВОРЯ, Р§РРў-КОДЫ https://onetwoonetwors.azfun.info/kXiV2b2zkc3NsL4/...">Р’ РЕАЛЬНОРМ† Р–РР—РќРР§РРўР«, РГРА Р’ РЕАЛЬНОСТР
EvelynBeece - Tuesday, September 29, 2020 - link
https://flashgitzanimation.seworld.info/qY3ImZLdZ4...">[img]https://i.ytimg.com/vi/sUd4-y1ROgM/hqdefault.jpg[/img]PUTTING https://flashgitzanimation.seworld.info/qY3ImZLdZ4...">AN END TO THIS
BrendaDeast - Thursday, October 1, 2020 - link
https://topg33ks.ilmem.info/z-mh/tKfLZ5h-r4KKZL4.h...">[img]https://i.ytimg.com/vi/SBe1bLzOQ1Y/hqdefault.jpg[/img]ЧђЧ– ЧћЧ” ЧћЧ—Ч›Ч” ЧњЧ Ч• Ч‘Ч©ЧњЧ‘ 4 Ч©Чњ https://topg33ks.ilmem.info/z-mh/tKfLZ5h-r4KKZL4.h...">ЧћЧђЧЁЧ•Ч•Чњ?