AMD Zen 3 Ryzen Deep Dive Review: 5950X, 5900X, 5800X and 5600X Tested
by Dr. Ian Cutress on November 5, 2020 9:01 AM ESTCPU Tests: Encoding
One of the interesting elements on modern processors is encoding performance. This covers two main areas: encryption/decryption for secure data transfer, and video transcoding from one video format to another.
In the encrypt/decrypt scenario, how data is transferred and by what mechanism is pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security.
Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
HandBrake 1.32: Link
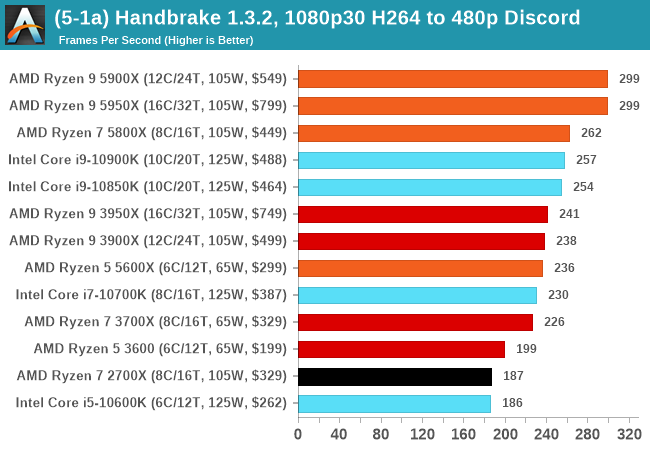
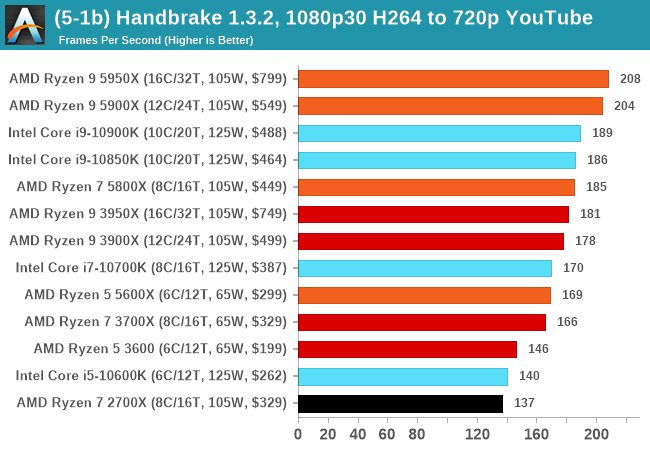
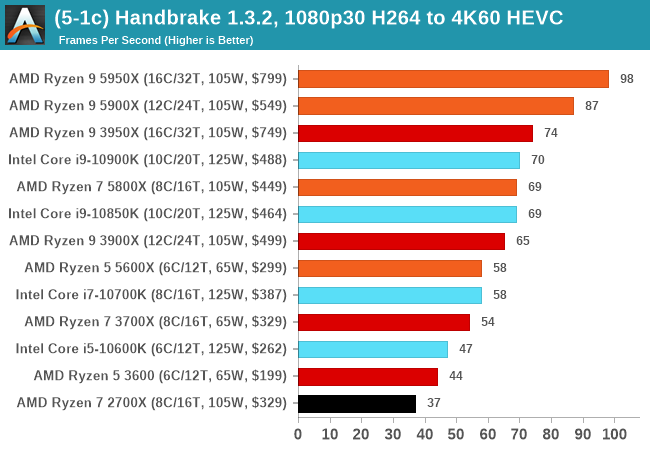
Video transcoding (both encode and decode) is a hot topic in performance metrics as more and more content is being created. First consideration is the standard in which the video is encoded, which can be lossless or lossy, trade performance for file-size, trade quality for file-size, or all of the above can increase encoding rates to help accelerate decoding rates. Alongside Google's favorite codecs, VP9 and AV1, there are others that are prominent: H264, the older codec, is practically everywhere and is designed to be optimized for 1080p video, and HEVC (or H.265) that is aimed to provide the same quality as H264 but at a lower file-size (or better quality for the same size). HEVC is important as 4K is streamed over the air, meaning less bits need to be transferred for the same quality content. There are other codecs coming to market designed for specific use cases all the time.
Handbrake is a favored tool for transcoding, with the later versions using copious amounts of newer APIs to take advantage of co-processors, like GPUs. It is available on Windows via an interface or can be accessed through the command-line, with the latter making our testing easier, with a redirection operator for the console output.
We take the compiled version of this 16-minute YouTube video about Russian CPUs at 1080p30 h264 and convert into three different files: (1) 480p30 ‘Discord’, (2) 720p30 ‘YouTube’, and (3) 4K60 HEVC.
7-Zip 1900: Link
The first compression benchmark tool we use is the open-source 7-zip, which typically offers good scaling across multiple cores. 7-zip is the compression tool most cited by readers as one they would rather see benchmarks on, and the program includes a built-in benchmark tool for both compression and decompression.
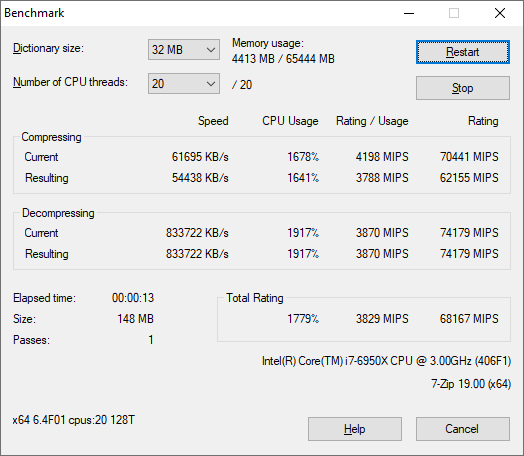
The tool can either be run from inside the software or through the command line. We take the latter route as it is easier to automate, obtain results, and put through our process. The command line flags available offer an option for repeated runs, and the output provides the average automatically through the console. We direct this output into a text file and regex the required values for compression, decompression, and a combined score.

AES Encoding
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.
WinRAR 5.90: Link
For the 2020 test suite, we move to the latest version of WinRAR in our compression test. WinRAR in some quarters is more user friendly that 7-Zip, hence its inclusion. Rather than use a benchmark mode as we did with 7-Zip, here we take a set of files representative of a generic stack
- 33 video files , each 30 seconds, in 1.37 GB,
- 2834 smaller website files in 370 folders in 150 MB,
- 100 Beat Saber music tracks and input files, for 451 MB
This is a mixture of compressible and incompressible formats. The results shown are the time taken to encode the file. Due to DRAM caching, we run the test for 20 minutes times and take the average of the last five runs when the benchmark is in a steady state.
For automation, we use AHK’s internal timing tools from initiating the workload until the window closes signifying the end. This means the results are contained within AHK, with an average of the last 5 results being easy enough to calculate.









339 Comments
View All Comments
Orkiton - Thursday, November 5, 2020 - link
Please Anandtech, up ryzen and up epic your servers, it's ages here to load a page...PrionDX - Thursday, November 5, 2020 - link
Mmm nice warm code bath, very relaxing> Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code bath.
prophet001 - Thursday, November 5, 2020 - link
How you gonna test FFXIV and not WoW.-______________-
Mr Perfect - Thursday, November 5, 2020 - link
Guys, could you please define acronyms the first time they are used in an article? Take page three for example, it touches on a BTB, TAGE and ITA, but only ITA is defined. I have no idea what a BTB or TAGE is. If they where defined on page two and I missed them, feel free to ignore me.name99 - Saturday, November 7, 2020 - link
BTB= Branch Target Buffer. Holds the addresses where a branch will go if it taken.TAGE= (tagged geometric something-or-other) name is not important; what matters is that it's currently the most accurate known branch predictor. Comes in a few variants, was 1st published around 2007 by Andre Seznec who has since gone on to show how it can be used for damn well everything! (Value prediction, indirect branch, prefetching, washing windows, you name it.)
Apple seems to have been first to implement, maybe as early as the A7, certainly very soon in the A series.
Now everybody uses it, but only in the last year or so has everyone really got on board. (Actually to be precise Seznec suggested that Intel is using TAGE based on their performance characteristics, but I don't think Intel have confirmed this. And ARM probably are but again unconfirmed. IBM is confirmed, and now AMD.)
Even if you know the basic algorithm for direction prediction is TAGE, that still doesn't make everyone equal. There are MANY extra aspects where everyone is different. The most obvious is how much storage is given to the branch predictor, but other less obvious aspects include
- how do you predict indirect branches? State of the art is ITTAGE, but that doesn't mean everyone is using it.
- how do you update your branch prediction storage (ie how fast do corrections get from the backend into the predicting mechanism at the front end)
- how do you implement your L2 storage and second-stage prediction?
- what extra "specialist" predictors do you have? (These are things like special-case predictors for loops.)
quantcon - Thursday, November 5, 2020 - link
Yeah, it's actually kinda nuts, considering Intel convinced us years ago that we've hit the point of diminishing returns and there are hardly any IPC improvements to be had.Spunjji - Sunday, November 8, 2020 - link
Seems like they needed to believe that...DanD85 - Thursday, November 5, 2020 - link
This just goes on to prove yet again how crucial a healthy competition benefits everyone. Intel has been stagnating for more than a decade. Imagine where we would have been performance-wise if we had got this ~40% increase every 3 years. Intel only have themselves to blame. They are the chipzillla, the gatekeeper and the choker of the whole industry!lmcd - Monday, November 9, 2020 - link
40% is a bit disingenuous. Most of the gap in desktop is chiplet design. Notice how mobile, while AMD-favored, is still competitive? It's just a bad bet from Intel going with stacked packaging before same-package flat chiplet, and the packaging techniques for both are very new. There aren't 40% improvements on the table going forward, Bulldozer and Piledriver were both just awful and AMD didn't ever release full desktop Steamroller or Excavator (which were fine, not great). Zen 1 left a lot on the table for such a big increase as well.GeoffreyA - Tuesday, November 10, 2020 - link
If you place Zen at Haswell's level, it took AMD three years to reach Zen 3 (from the consumer's point of view). On Intel's side, it's taken six years to go from Haswell to Sunny Cove.Even in the early tick-tock days, when more massive changes could be put in, it was usually two years apart for microarchitecture: Core (2006), Nehalem (2008), Sandy Bridge (2010/11), etc.
Whether there's a lot more juice in the tank for Zen remains to be seen. In my opinion I think there is: Z3's out-of-order structures are still quite conservative, compared to Sunny Cove, which it beats, so there's possibility of more widening there. I also think their split scheduler design, inherited from the Athlon, will allow them to scale more easily. Of course, I know the engineers in Haifa must be cooking up something potent too. Either way, exciting stuff.