Retesting AMD Ryzen Threadripper’s Game Mode: Halving Cores for More Performance
by Ian Cutress on August 17, 2017 12:01 PM ESTCPU Rendering Tests
Rendering tests are a long-time favorite of reviewers and benchmarkers, as the code used by rendering packages is usually highly optimized to squeeze every little bit of performance out. Sometimes rendering programs end up being heavily memory dependent as well - when you have that many threads flying about with a ton of data, having low latency memory can be key to everything. Here we take a few of the usual rendering packages under Windows 10, as well as a few new interesting benchmarks.
All of our benchmark results can also be found in our benchmark engine, Bench.
Corona 1.3: link
Corona is a standalone package designed to assist software like 3ds Max and Maya with photorealism via ray tracing. It's simple - shoot rays, get pixels. OK, it's more complicated than that, but the benchmark renders a fixed scene six times and offers results in terms of time and rays per second. The official benchmark tables list user submitted results in terms of time, however I feel rays per second is a better metric (in general, scores where higher is better seem to be easier to explain anyway). Corona likes to pile on the threads, so the results end up being very staggered based on thread count.
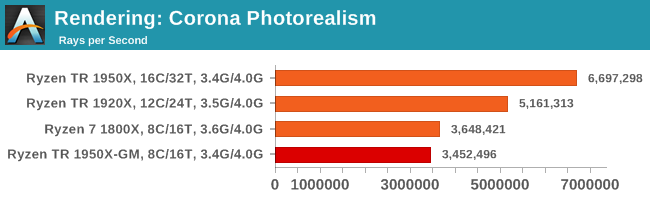
Corona loves threads. Game Mode goes behind the 1800X due to frequency.
Blender 2.78: link
For a render that has been around for what seems like ages, Blender is still a highly popular tool. We managed to wrap up a standard workload into the February 5 nightly build of Blender and measure the time it takes to render the first frame of the scene. Being one of the bigger open source tools out there, it means both AMD and Intel work actively to help improve the codebase, for better or for worse on their own/each other's microarchitecture.
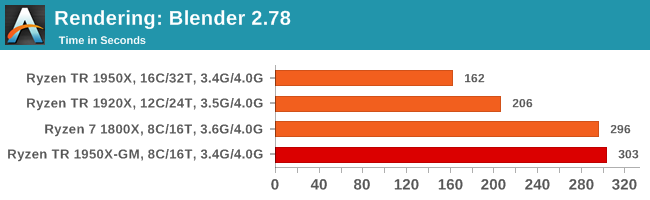
Blender loves threads.
LuxMark v3.1: Link
As a synthetic, LuxMark might come across as somewhat arbitrary as a renderer, given that it's mainly used to test GPUs, but it does offer both an OpenCL and a standard C++ mode. In this instance, aside from seeing the comparison in each coding mode for cores and IPC, we also get to see the difference in performance moving from a C++ based code-stack to an OpenCL one with a CPU as the main host.
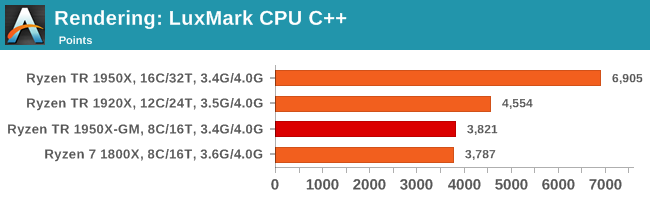
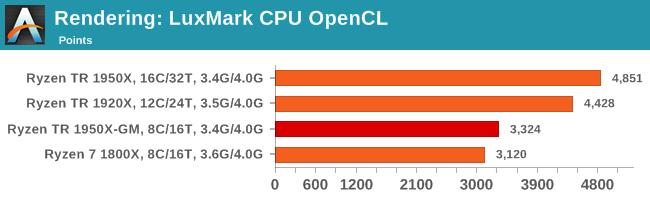
Like Blender, LuxMark is all about the thread count. Ray tracing is very nearly a textbook case for easy multi-threaded scaling, although a couple of things pop up in the OpenCL version. Aside from the scores being lower, the jump from 1920X to 1950X isn't that great, and the quad-channel DRAM of the 1950X in Game Mode puts it over the 1800X.
POV-Ray 3.7.1b4: link
Another regular benchmark in most suites, POV-Ray is another ray-tracer but has been around for many years. It just so happens that during the run up to AMD's Ryzen launch, the code base started to get active again with developers making changes to the code and pushing out updates. Our version and benchmarking started just before that was happening, but given time we will see where the POV-Ray code ends up and adjust in due course.
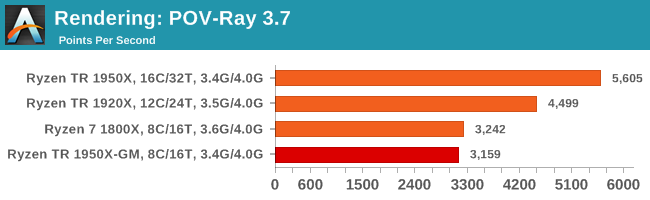
POV-Ray loves threads.
Cinebench R15: link
The latest version of CineBench has also become one of those 'used everywhere' benchmarks, particularly as an indicator of single thread performance. High IPC and high frequency gives performance in ST, whereas having good scaling and many cores is where the MT test wins out.
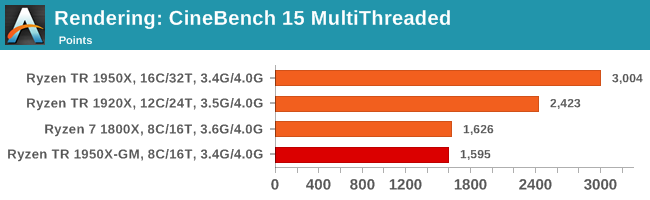
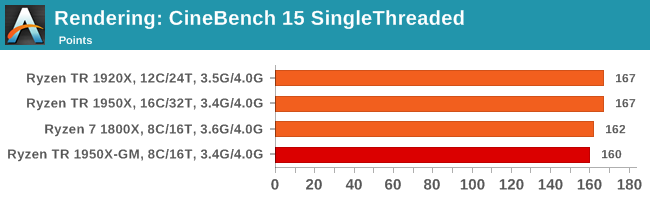
Multithreaded results are as expected, and single thread seems to benefit a bit from more DRAM channels, although 200 MHz is enough to put the 1800X over the 1950X in Game Mode.








104 Comments
View All Comments
silverblue - Friday, August 18, 2017 - link
I'd like to see what happens when you manually set a 2+2+2+2 core configuration, instead of enabling Game Mode. From what I've read, Game Mode destroys memory bandwidth but yields better latency, however it's not answering whether Zen cores can really benefit from the extra bandwidth that a quad-channel memory interface affords.Alternatively, just clock the 1950 and 1920 identically, and see if the 1920's per-core performance is any higher.
KAlmquist - Friday, August 18, 2017 - link
“One of the interesting data points in our test is the Compile. Because <B>this test requires a lot of cross-core communication</B> and DRAM, we get an interesting metric where the 1950X still comes out on top due to the core counts, but because the 1920X has fewer cores per CCX, it actually falls behind the 1950X in Game Mode and the 1800X despite having more cores.”Generally speaking, copmpilers are single threaded, so the parallelism in a software build comes from compiling multiple source files in parallel, meaning the cross-core communication is minimal. I have no idea what MSVC is doing here, can you explain? In any case, while I appreciate you including a software development benchmark, the one you've chosen would seem to provide no useful information to anyone who doesn't use MSVC.
peevee - Friday, August 18, 2017 - link
I use MSVC and it scales pretty well if you are using it right. They are doing something wrong.KAlmquist - Saturday, August 19, 2017 - link
Thanks. It makes sense that MSVC would scale about as well as any other build environment.ARS Technica also benchmarked a Chromium build, which I think uses MSVC, but uses the Google tools GN and Ninja to manage the build. They get:
Ryzen 1800X (8 cores) - 9.8 build/day
Threadripper 1920X (12 cores) - 16.7 build/day
Threadripper 1950X (16 cores) - 18.6 build/day
Very good speedup with the 1920X over the 1800X, but not so much going from the 1920X to the 1950X. Perhaps the benchmark is dependent on memory bandwidth and L3 cache.
Timur Born - Friday, August 18, 2017 - link
Thanks for the tests!I would have liked to see a combination of both being tested: Game Mode to switch off the second die and SMT disabled. That way 4 full physical cores with low latency memory access would have run the games.
Hopefully modern titles don't benefit from this, but some more "legacy" ones might like this setup even more.
Timur Born - Friday, August 18, 2017 - link
Sorry, I meant 8 cores, aka 8/8 cores mode.mat9v - Friday, August 18, 2017 - link
I wish someone had an inclination to test creative mode but with games pinned to one module. It is essentially NUMA mode but with all cores active.Or just enable SMT that is disabled in Gaming Mode - we actually then get a Ryzen 1800X CPU that overclocks well but with possibly higher performance due to all system task running on different module (if we configure system that way) and unencumbered access to more PCIEx lines.
peevee - Friday, August 18, 2017 - link
Yes, that would be interesting.c:\>start /REALTIME /NODE 0 /AFFINITY 5555 you_game_here.exe
mat9v - Friday, August 18, 2017 - link
I think I would start it on node 1 is anything since system task would be at default running on node 0.Mask 5555? Wouldn't it be AAAA - for 8 cores (8 threads) and FFFF for 8 cores (16 threads)?
peevee - Friday, August 18, 2017 - link
The mask 5555 assumes that SMT is enabled. Otherwise it should be FF.When SMT is enabled, 5555 and AAAA will allocate threads to the same cores, just different logical CPUs.
Where system threads will be run is system dependent, nothing prevents Windows from running them on NODE 1. /NODE 0 allows to run whether or not you actually have multiple NUMA nodes.
With /REALTIME Windows will have hard time allocating anything on those logical CPUs, but can use the same cores with other logical CPUs, so yes, technically it will affect results. But unless you load it with something, the difference should not be significant - things like cache and memory bus contention are more important anyway and don't care on which cores you run.