The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTFeeding Pascal, Cont: 4th Gen Delta Color Compression
Now that we’ve seen GDDR5X in depth, let’s talk about the other half of the equation when it comes to feeding Pascal: delta color compression.
NVIDIA has utilized delta color compression for a number of years now. However the technology only came into greater prominence in the previous Maxwell 2 generation, when NVIDIA disclosed delta color compression’s existence and offered a basic overview of how it worked. As a reminder, delta color compression is a per-buffer/per-frame compression method that breaks down a frame into tiles, and then looks at the differences between neighboring pixels – their deltas. By utilizing a large pattern library, NVIDIA is able to try different patterns to describe these deltas in as few pixels as possible, ultimately conserving bandwidth throughout the GPU, not only reducing DRAM bandwidth needs, but also L2 bandwidth needs and texture unit bandwidth needs (in the case of reading back a compressed render target).
Since its inception NVIDIA has continued to tweak and push the technology for greater compression and to catch patterns they missed on prior generations, and Pascal in that respect is no different. With Pascal we get the 4th generation of the technology, and while there’s nothing radical here compared to the 3rd generation, it’s another element of Pascal where there has been an iterative improvement on the technology.
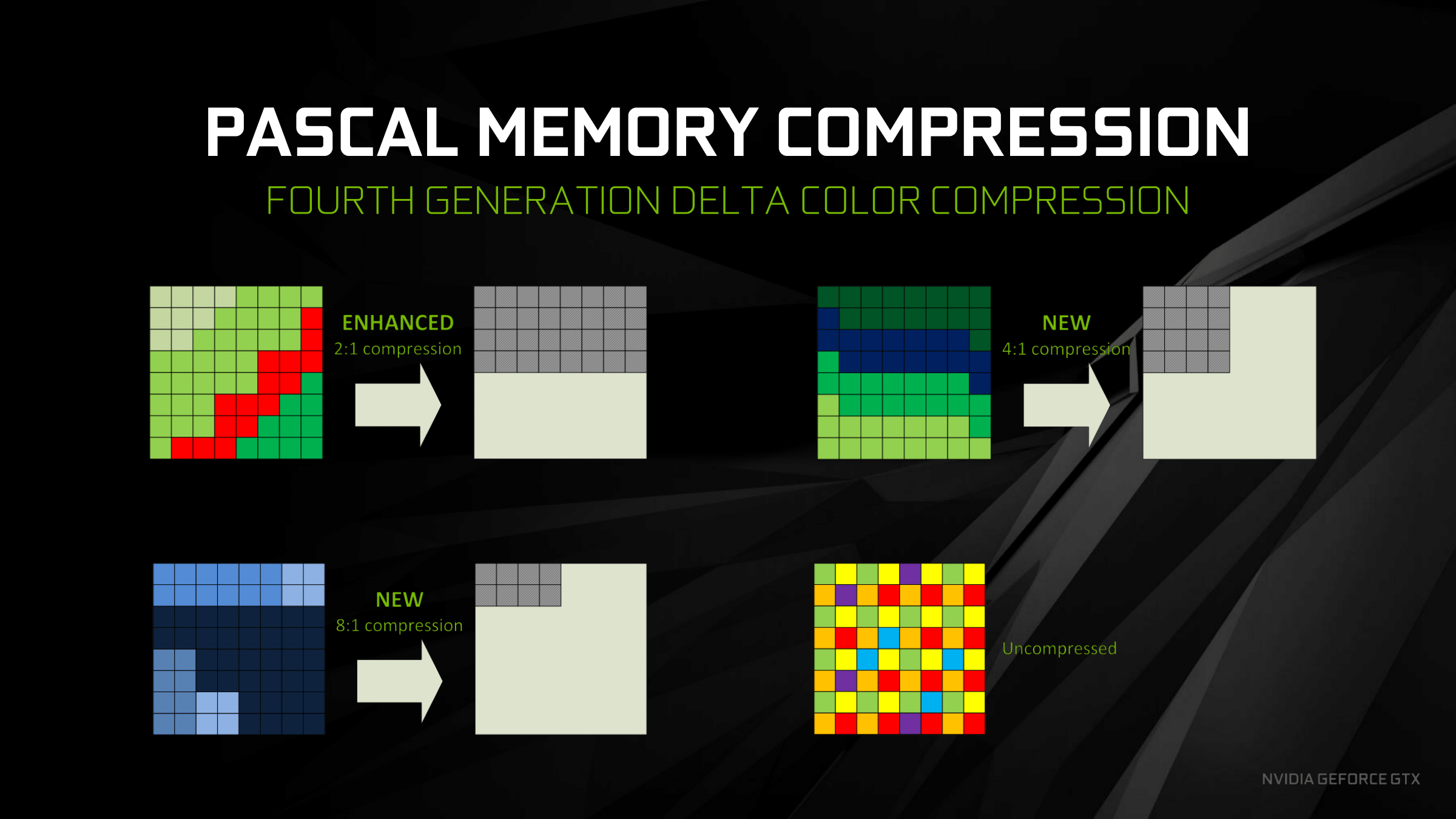
New to Pascal is a mix of improved compression modes and new compression modes. 2:1 compression mode, the only delta compression mode available up through the 3rd generation, has been enhanced with the addition of more patterns to cover more scenarios, meaning NVIDIA is able to 2:1 compress blocks more often.
Meanwhile, new to delta color compression with Pascal is 4:1 and 8:1 compression modes, joining the aforementioned 2:1 mode. Unlike 2:1 mode, the higher compression modes are a little less straightforward, as there’s a bit more involved than simply the pattern of the pixels. 4:1 compression is in essence a special case of 2:1 compression, where NVIDIA can achieve better compression when the deltas between pixels are very small, allowing those differences to be described in fewer bits. 8:1 is more radical still; rather an operating on individual pixels, it operates on multiple 2x2 blocks. Specifically, after NVIDIA’s constant color compressor does its job – finding 2x2 blocks of identical pixels and compressing them to a single sample – the 8:1 delta mode then applies 2:1 delta compression to the already compressed blocks, achieving the titular 8:1 effective compression ratio.
Overall, delta color compression represents one of the interesting tradeoffs NVIDIA has to make in the GPU design process. The number of patterns is essentially a function of die space, so NVIDIA could always add more patterns, but would the memory bandwidth improvements be worth the real cost of die space and the power cost of those transistors? Especially since NVIDIA has already implemented the especially common patterns, which means new patterns likely won’t occur as frequently. NVIDIA of course pushed ahead here, thanks in part to the die and power savings of 16nm FinFET, but it gives us an idea of where they might (or might not) go in future generations in order to balance the costs and benefits of the technology, with less of an emphasis on patterns and instead making more novel use of those patterns.

To put all of this in numbers, NVIDIA pegs the effective increase in memory bandwidth from delta color compression alone at 20%. The difference is of course per-game, as the effectiveness of the tech depends on how well a game sticks to patterns (and if you ever create a game with random noise, you may drive an engineer or two insane), but 20% is a baseline number for the average. Meanwhile for anyone keeping track of the numbers over Maxwell 2, this is a bit less than the gains with NVIDIA’s last generation architecture, where the company claimed the average gain was 25%.
The net impact then, as NVIDIA likes to promote it, is a 70% increase in the total effective memory bandwidth. This comes from the earlier 40% (technically 42.9%) actual memory bandwidth gains in the move from 7Gbps GDDR5 to 10Gbps GDDR5X, coupled with the 20% effective memory bandwidth increase from delta compression. Keep those values in mind, as we’re going to get back to them in a little bit.
Meanwhile from a graphical perspective, to showcase the impact of delta color compression, NVIDIA sent over a pair of screenshots for Project Cars, colored to show what pixels had been compressed. Shown in pink, even Maxwell can compress most of the frame, really only struggling with finer details such as the trees, the grass, and edges of buildings. Pascal, by comparison, gets most of this. Trees and buildings are all but eliminated as visually distinct uncompressed items, leaving only patches of grass and indistinct fringe elements. It should be noted that these screenshots have most likely been picked because they’re especially impressive – seeing as how not all games compress this well – but it’s none the less a potent example of how much of a frame Pascal can compress.


Finally, while we’re on the subject of compress, I want to talk a bit about memory bandwidth relative to other aspects of the GPU. While Pascal (in the form of GTX 1080) offers 43% more raw memory bandwidth than GTX 980 thanks to GDDR5X, it’s important to note just how quickly this memory bandwidth is consumed. Thanks to GTX 1080’s high clockspeeds, the raw throughput of the ROPs is coincidentally also 43% higher. Or we have the case of the CUDA cores, whose total throughput is 78% higher, shooting well past the raw memory bandwidth gains.
While it’s not a precise metric, the amount of bandwidth available per FLOP has continued to drop over the years with NVIDIA’s video cards. GTX 580 offered just short of 1 bit of memory bandwidth per FLOP, and by GTX 980 this was down to 0.36 bits/FLOP. GTX 1080 is lower still, now down to 0.29bits/FLOP thanks to the increase in both CUDA core count and frequency as afforded by the 16nm process.
| NVIDIA Memory Bandwidth per FLOP (In Bits) | ||||||
| GPU | Bandwidth/FLOP | Total FLOPs | Total Bandwidth | |||
| GTX 1080 | 0.29 bits | 8.87 TFLOPs | 320GB/sec | |||
| GTX 980 | 0.36 bits | 4.98 TFLOPs | 224GB/sec | |||
| GTX 680 | 0.47 bits | 3.25 TFLOPs | 192GB/sec | |||
| GTX 580 | 0.97 bits | 1.58 TFLOPs | 192GB/sec | |||
The good news here is that at least for graphical tasks, the CUDA cores generally aren’t the biggest consumer of DRAM bandwidth. That would fall to the ROPs, which are packed alongside the L2 cache and memory controllers for this very reason. In that case GTX 1080’s bandwidth gains keep up with the ROP performance increase, but only by just enough.
The overall memory bandwidth needs of GP104 still outpace the memory bandwidth gains from GDDR5X, and this is why features such as delta color compression are so important to GP104’s performance. GP104 is perpetually memory bandwidth starved – adding more memory bandwidth will improve performance, as we’ll see in our overclocking results – and that means that NVIDIA will continue to try to conserve memory bandwidth usage as much as possible through compression and other means. How long they can fight this battle remains to be seen – they already encounter diminishing returns in some cases – but in the meantime this allows NVIDIA to utilize smaller memory buses, keeping down the die size and power costs of their GPUs, making PCB costs cheaper, and of course boosting profit margins at the same time.








200 Comments
View All Comments
grrrgrrr - Wednesday, July 20, 2016 - link
Solid review! Some nice architecture introductions.euskalzabe - Wednesday, July 20, 2016 - link
The HDR discussion of this review was super interesting, but as always, there's one key piece of information missing: WHEN are we going to see HDR monitors that take advantage of these new GPU abilities?I myself am stuck at 1080p IPS because more resolution doesn't entice me, and there's nothing better than IPS. I'm waiting for HDR to buy my next monitor, but being 5 years old my Dell ST2220T is getting long in the teeth...
ajlueke - Wednesday, July 20, 2016 - link
Thanks for the review Ryan,I think the results are quite interesting, and the games chosen really help show the advantages and limitations of the different architectures. When you compare the GTX 1080 to its price predecessor, the 980 Ti, you are getting an almost universal ~25%-30% increase in performance.
Against rival AMDs R9 Fury X, there is more of a mixed bag. As the resolutions increase the bandwidth provided by the HBM memory on the Fury X really narrows the gap, sometimes trimming the margin to less that 10%,s specifically in games optimized more for DX12 "Hitman, "AotS". But it other games, specifically "Rise of the Tomb Raider" which boasts extremely high res textures, the 4Gb memory size on the Fury X starts to limit its performance in a big way. On average, there is again a ~25%-30% performance increase with much higher game to game variability.
This data lets a little bit of air out of the argument I hear a lot that AMD makes more "future proof" cards. While many Nvidia 900 series users may have to upgrade as more and more games switch to DX12 based programming. AMD Fury users will be in the same boat as those same games come with higher and higher res textures, due to the smaller amount of memory on board.
While Pascal still doesn't show the jump in DX12 versus DX11 that AMD's GPUs enjoy, it does at least show an increase or at least remain at parity.
So what you have is a card that wins in every single game tested, at every resolution over the price predecessors from both companies, all while consuming less power. That is a win pretty much any way you slice it. But there are elements of Nvidia’s strategy and the card I personally find disappointing.
I understand Nvidia wants to keep features specific to the higher margin professional cards, but avoiding HBM2 altogether in the consumer space seems to be a missed opportunity. I am a huge fan of the mini ITX gaming machines. And the Fury Nano, at the $450 price point is a great card. With an NVMe motherboard and NAS storage the need for drive bays in the case is eliminated, the Fury Nano at only 6” leads to some great forward thinking, and tiny designs. I was hoping to see an explosion of cases that cut out the need for supporting 10-11” cards and tons of drive bays if both Nvidia and AMD put out GPUs in the Nano space, but it seems not to be. HBM2 seems destined to remain on professional cards, as Nvidia won’t take the risk of adding it to a consumer Titan or GTX 1080 Ti card and potentially again cannibalize the higher margin professional card market. Now case makers don’t really have the same incentive to build smaller cases if the Fury Nano will still be the only card at that size. It’s just unfortunate that it had to happen because NVidia decided HBM2 was something they could slap on a pro card and sell for thousands extra.
But also what is also disappointing about Pascal stems from the GTX 1080 vs GTX 1070 data Ryan has shown. The GTX 1070 drops off far more than one would expect based off CUDA core numbers as the resolution increases. The GDDR5 memory versus the GDDR5X is probably at fault here, leading me to believe that Pascal can gain even further if the memory bandwidth is increased more, again with HBM2. So not only does the card limit you to the current mini-ITX monstrosities (I’m looking at you bulldog) by avoiding HBM2, it also very likely is costing us performance.
Now for the rank speculation. The data does present some interesting scenarios for the future. With the Fury X able to approach the GTX 1080 at high resolutions, most specifically in DX12 optimized games. It seems extremely likely that the Vega GPU will be able to surpass the GTX 1080, especially if the greatest limitation (4 Gb HBM) is removed with the supposed 8Gb of HBM2 and games move more and more the DX12. I imagine when it launches it will be the 4K card to get, as the Fury X already acquits itself very well there. For me personally, I will have to wait for the Vega Nano to realize my Mini-ITX dreams, unless of course, AMD doesn’t make another Nano edition card and the dream is dead. A possibility I dare not think about.
eddman - Wednesday, July 20, 2016 - link
The gap getting narrower at higher resolutions probably has more to do with chips' designs rather than bandwidth. After all, Fury is the big GCN chip optimized for high resolutions. Even though GP104 does well, it's still the middle Pascal chip.P.S. Please separate the paragraphs. It's a pain, reading your comment.
Eidigean - Wednesday, July 20, 2016 - link
The GTX 1070 is really just a way for Nvidia to sell GP104's that didn't pass all of their tests. Don't expect them to put expensive memory on a card where they're only looking to make their money back. Keeping the card cost down, hoping it sells, is more important to them.If there's a defect anywhere within one of the GPC's, the entire GPC is disabled and the chip is sold at a discount instead of being thrown out. I would not buy a 1070 which is really just a crippled 1080.
I'll be buying a 1080 for my 2560x1600 desktop, and an EVGA 1060 for my Mini-ITX build; which has a limited power supply.
mikael.skytter - Wednesday, July 20, 2016 - link
Thanks Ryan! Much appreciated.chrisp_6@yahoo.com - Wednesday, July 20, 2016 - link
Very good review. One minor comment to the article writers - do a final check on grammer - granted we are technical folks, but it was noticeable especially on the final words page.madwolfa - Wednesday, July 20, 2016 - link
It's "grammar", though. :)Eden-K121D - Thursday, July 21, 2016 - link
Oh the ironychrisp_6@yahoo.com - Thursday, July 21, 2016 - link
oh snap, that is some funny stuff right there